 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
LuxRemix: Lighting Decomposition and Remixing for Indoor Scenes
Jan 21, 2026We present a novel approach for interactive light editing in indoor scenes from a single multi-view scene capture. Our method leverages a generative image-based light decomposition model that factorizes complex indoor scene illumination into its constituent light sources. This factorization enables independent manipulation of individual light sources, specifically allowing control over their state (on/off), chromaticity, and intensity. We further introduce multi-view lighting harmonization to ensure consistent propagation of the lighting decomposition across all scene views. This is integrated into a relightable 3D Gaussian splatting representation, providing real-time interactive control over the individual light sources. Our results demonstrate highly photorealistic lighting decomposition and relighting outcomes across diverse indoor scenes. We evaluate our method on both synthetic and real-world datasets and provide a quantitative and qualitative comparison to state-of-the-art techniques. For video results and interactive demos, see https://luxremix.github.io.
Flow Matching Policy Gradients
Jul 28, 2025Flow-based generative models, including diffusion models, excel at modeling continuous distributions in high-dimensional spaces. In this work, we introduce Flow Policy Optimization (FPO), a simple on-policy reinforcement learning algorithm that brings flow matching into the policy gradient framework. FPO casts policy optimization as maximizing an advantage-weighted ratio computed from the conditional flow matching loss, in a manner compatible with the popular PPO-clip framework. It sidesteps the need for exact likelihood computation while preserving the generative capabilities of flow-based models. Unlike prior approaches for diffusion-based reinforcement learning that bind training to a specific sampling method, FPO is agnostic to the choice of diffusion or flow integration at both training and inference time. We show that FPO can train diffusion-style policies from scratch in a variety of continuous control tasks. We find that flow-based models can capture multimodal action distributions and achieve higher performance than Gaussian policies, particularly in under-conditioned settings.
Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop
Jun 12, 2025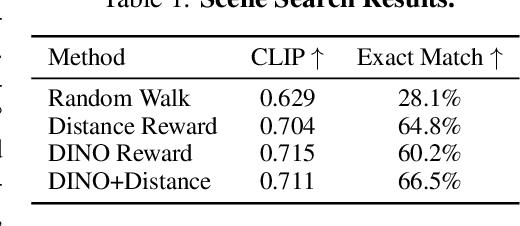
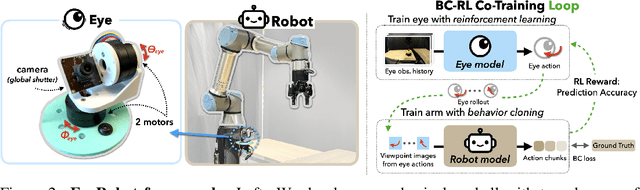


Humans do not passively observe the visual world -- we actively look in order to act. Motivated by this principle, we introduce EyeRobot, a robotic system with gaze behavior that emerges from the need to complete real-world tasks. We develop a mechanical eyeball that can freely rotate to observe its surroundings and train a gaze policy to control it using reinforcement learning. We accomplish this by first collecting teleoperated demonstrations paired with a 360 camera. This data is imported into a simulation environment that supports rendering arbitrary eyeball viewpoints, allowing episode rollouts of eye gaze on top of robot demonstrations. We then introduce a BC-RL loop to train the hand and eye jointly: the hand (BC) agent is trained from rendered eye observations, and the eye (RL) agent is rewarded when the hand produces correct action predictions. In this way, hand-eye coordination emerges as the eye looks towards regions which allow the hand to complete the task. EyeRobot implements a foveal-inspired policy architecture allowing high resolution with a small compute budget, which we find also leads to the emergence of more stable fixation as well as improved ability to track objects and ignore distractors. We evaluate EyeRobot on five panoramic workspace manipulation tasks requiring manipulation in an arc surrounding the robot arm. Our experiments suggest EyeRobot exhibits hand-eye coordination behaviors which effectively facilitate manipulation over large workspaces with a single camera. See project site for videos: https://www.eyerobot.net/
Pippo: High-Resolution Multi-View Humans from a Single Image
Feb 11, 2025
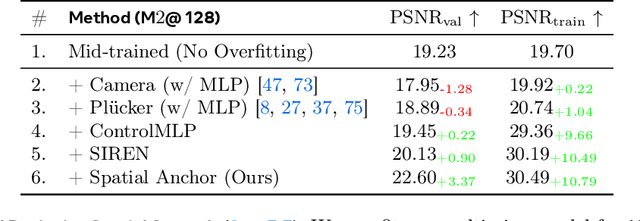
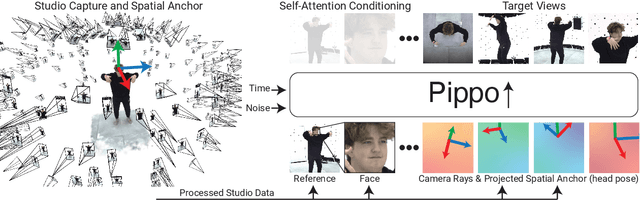

We present Pippo, a generative model capable of producing 1K resolution dense turnaround videos of a person from a single casually clicked photo. Pippo is a multi-view diffusion transformer and does not require any additional inputs - e.g., a fitted parametric model or camera parameters of the input image. We pre-train Pippo on 3B human images without captions, and conduct multi-view mid-training and post-training on studio captured humans. During mid-training, to quickly absorb the studio dataset, we denoise several (up to 48) views at low-resolution, and encode target cameras coarsely using a shallow MLP. During post-training, we denoise fewer views at high-resolution and use pixel-aligned controls (e.g., Spatial anchor and Plucker rays) to enable 3D consistent generations. At inference, we propose an attention biasing technique that allows Pippo to simultaneously generate greater than 5 times as many views as seen during training. Finally, we also introduce an improved metric to evaluate 3D consistency of multi-view generations, and show that Pippo outperforms existing works on multi-view human generation from a single image.
Fillerbuster: Multi-View Scene Completion for Casual Captures
Feb 07, 2025
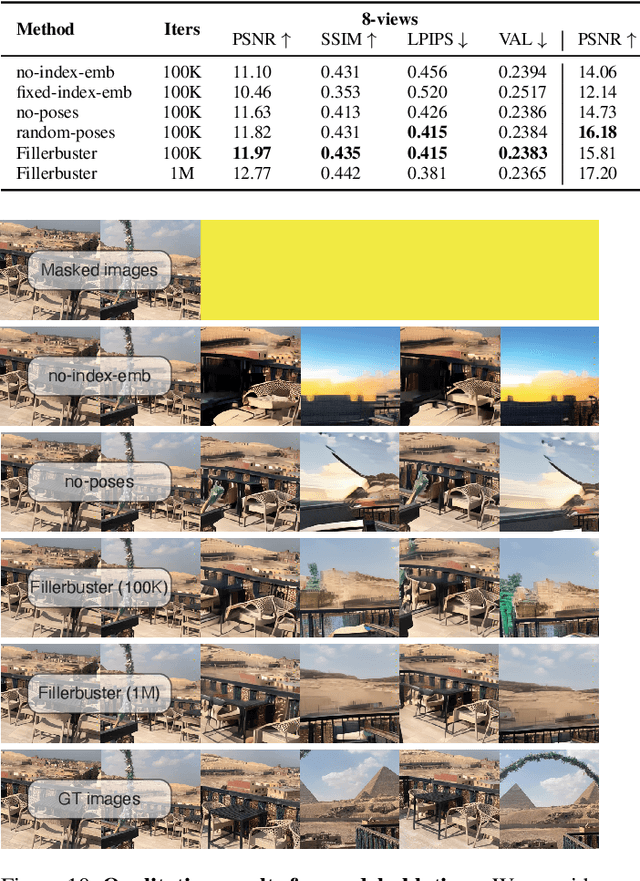
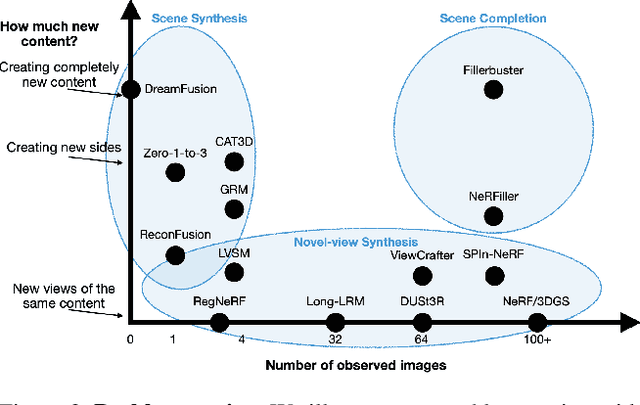

We present Fillerbuster, a method that completes unknown regions of a 3D scene by utilizing a novel large-scale multi-view latent diffusion transformer. Casual captures are often sparse and miss surrounding content behind objects or above the scene. Existing methods are not suitable for handling this challenge as they focus on making the known pixels look good with sparse-view priors, or on creating the missing sides of objects from just one or two photos. In reality, we often have hundreds of input frames and want to complete areas that are missing and unobserved from the input frames. Additionally, the images often do not have known camera parameters. Our solution is to train a generative model that can consume a large context of input frames while generating unknown target views and recovering image poses when desired. We show results where we complete partial captures on two existing datasets. We also present an uncalibrated scene completion task where our unified model predicts both poses and creates new content. Our model is the first to predict many images and poses together for scene completion.
Toon3D: Seeing Cartoons from a New Perspective
May 17, 2024In this work, we recover the underlying 3D structure of non-geometrically consistent scenes. We focus our analysis on hand-drawn images from cartoons and anime. Many cartoons are created by artists without a 3D rendering engine, which means that any new image of a scene is hand-drawn. The hand-drawn images are usually faithful representations of the world, but only in a qualitative sense, since it is difficult for humans to draw multiple perspectives of an object or scene 3D consistently. Nevertheless, people can easily perceive 3D scenes from inconsistent inputs! In this work, we correct for 2D drawing inconsistencies to recover a plausible 3D structure such that the newly warped drawings are consistent with each other. Our pipeline consists of a user-friendly annotation tool, camera pose estimation, and image deformation to recover a dense structure. Our method warps images to obey a perspective camera model, enabling our aligned results to be plugged into novel-view synthesis reconstruction methods to experience cartoons from viewpoints never drawn before. Our project page is https://toon3d.studio .
NeRFiller: Completing Scenes via Generative 3D Inpainting
Dec 07, 2023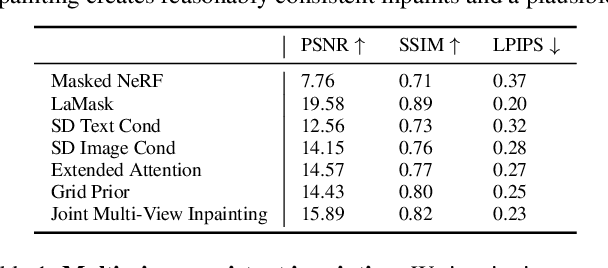

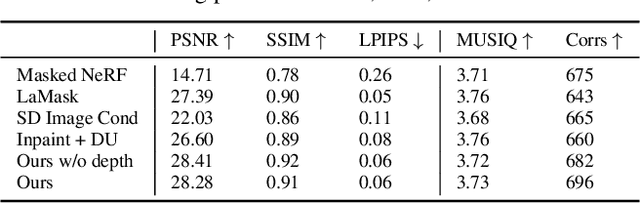

We propose NeRFiller, an approach that completes missing portions of a 3D capture via generative 3D inpainting using off-the-shelf 2D visual generative models. Often parts of a captured 3D scene or object are missing due to mesh reconstruction failures or a lack of observations (e.g., contact regions, such as the bottom of objects, or hard-to-reach areas). We approach this challenging 3D inpainting problem by leveraging a 2D inpainting diffusion model. We identify a surprising behavior of these models, where they generate more 3D consistent inpaints when images form a 2$\times$2 grid, and show how to generalize this behavior to more than four images. We then present an iterative framework to distill these inpainted regions into a single consistent 3D scene. In contrast to related works, we focus on completing scenes rather than deleting foreground objects, and our approach does not require tight 2D object masks or text. We compare our approach to relevant baselines adapted to our setting on a variety of scenes, where NeRFiller creates the most 3D consistent and plausible scene completions. Our project page is at https://ethanweber.me/nerfiller.
Nerfbusters: Removing Ghostly Artifacts from Casually Captured NeRFs
Apr 21, 2023Casually captured Neural Radiance Fields (NeRFs) suffer from artifacts such as floaters or flawed geometry when rendered outside the camera trajectory. Existing evaluation protocols often do not capture these effects, since they usually only assess image quality at every 8th frame of the training capture. To push forward progress in novel-view synthesis, we propose a new dataset and evaluation procedure, where two camera trajectories are recorded of the scene: one used for training, and the other for evaluation. In this more challenging in-the-wild setting, we find that existing hand-crafted regularizers do not remove floaters nor improve scene geometry. Thus, we propose a 3D diffusion-based method that leverages local 3D priors and a novel density-based score distillation sampling loss to discourage artifacts during NeRF optimization. We show that this data-driven prior removes floaters and improves scene geometry for casual captures.
Nerfstudio: A Modular Framework for Neural Radiance Field Development
Feb 08, 2023



Neural Radiance Fields (NeRF) are a rapidly growing area of research with wide-ranging applications in computer vision, graphics, robotics, and more. In order to streamline the development and deployment of NeRF research, we propose a modular PyTorch framework, Nerfstudio. Our framework includes plug-and-play components for implementing NeRF-based methods, which make it easy for researchers and practitioners to incorporate NeRF into their projects. Additionally, the modular design enables support for extensive real-time visualization tools, streamlined pipelines for importing captured in-the-wild data, and tools for exporting to video, point cloud and mesh representations. The modularity of Nerfstudio enables the development of Nerfacto, our method that combines components from recent papers to achieve a balance between speed and quality, while also remaining flexible to future modifications. To promote community-driven development, all associated code and data are made publicly available with open-source licensing at https://nerf.studio.