 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-level 3D shape perception emerges from multi-view learning
Feb 19, 2026Humans can infer the three-dimensional structure of objects from two-dimensional visual inputs. Modeling this ability has been a longstanding goal for the science and engineering of visual intelligence, yet decades of computational methods have fallen short of human performance. Here we develop a modeling framework that predicts human 3D shape inferences for arbitrary objects, directly from experimental stimuli. We achieve this with a novel class of neural networks trained using a visual-spatial objective over naturalistic sensory data; given a set of images taken from different locations within a natural scene, these models learn to predict spatial information related to these images, such as camera location and visual depth, without relying on any object-related inductive biases. Notably, these visual-spatial signals are analogous to sensory cues readily available to humans. We design a zero-shot evaluation approach to determine the performance of these `multi-view' models on a well established 3D perception task, then compare model and human behavior. Our modeling framework is the first to match human accuracy on 3D shape inferences, even without task-specific training or fine-tuning. Remarkably, independent readouts of model responses predict fine-grained measures of human behavior, including error patterns and reaction times, revealing a natural correspondence between model dynamics and human perception. Taken together, our findings indicate that human-level 3D perception can emerge from a simple, scalable learning objective over naturalistic visual-spatial data. All code, human behavioral data, and experimental stimuli needed to reproduce our findings can be found on our project page.
Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop
Jun 12, 2025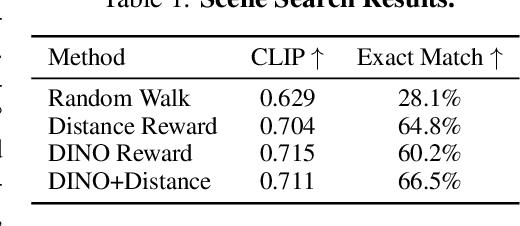
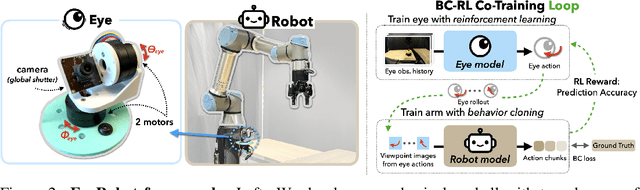


Humans do not passively observe the visual world -- we actively look in order to act. Motivated by this principle, we introduce EyeRobot, a robotic system with gaze behavior that emerges from the need to complete real-world tasks. We develop a mechanical eyeball that can freely rotate to observe its surroundings and train a gaze policy to control it using reinforcement learning. We accomplish this by first collecting teleoperated demonstrations paired with a 360 camera. This data is imported into a simulation environment that supports rendering arbitrary eyeball viewpoints, allowing episode rollouts of eye gaze on top of robot demonstrations. We then introduce a BC-RL loop to train the hand and eye jointly: the hand (BC) agent is trained from rendered eye observations, and the eye (RL) agent is rewarded when the hand produces correct action predictions. In this way, hand-eye coordination emerges as the eye looks towards regions which allow the hand to complete the task. EyeRobot implements a foveal-inspired policy architecture allowing high resolution with a small compute budget, which we find also leads to the emergence of more stable fixation as well as improved ability to track objects and ignore distractors. We evaluate EyeRobot on five panoramic workspace manipulation tasks requiring manipulation in an arc surrounding the robot arm. Our experiments suggest EyeRobot exhibits hand-eye coordination behaviors which effectively facilitate manipulation over large workspaces with a single camera. See project site for videos: https://www.eyerobot.net/
Hidden in plain sight: VLMs overlook their visual representations
Jun 09, 2025Language provides a natural interface to specify and evaluate performance on visual tasks. To realize this possibility, vision language models (VLMs) must successfully integrate visual and linguistic information. Our work compares VLMs to a direct readout of their visual encoders to understand their ability to integrate across these modalities. Across a series of vision-centric benchmarks (e.g., depth estimation, correspondence), we find that VLMs perform substantially worse than their visual encoders, dropping to near-chance performance. We investigate these results through a series of analyses across the entire VLM: namely 1) the degradation of vision representations, 2) brittleness to task prompt, and 3) the language model's role in solving the task. We find that the bottleneck in performing these vision-centric tasks lies in this third category; VLMs are not effectively using visual information easily accessible throughout the entire model, and they inherit the language priors present in the LLM. Our work helps diagnose the failure modes of open-source VLMs, and presents a series of evaluations useful for future investigations into visual understanding within VLMs.
Evaluating Multiview Object Consistency in Humans and Image Models
Sep 10, 2024



We introduce a benchmark to directly evaluate the alignment between human observers and vision models on a 3D shape inference task. We leverage an experimental design from the cognitive sciences which requires zero-shot visual inferences about object shape: given a set of images, participants identify which contain the same/different objects, despite considerable viewpoint variation. We draw from a diverse range of images that include common objects (e.g., chairs) as well as abstract shapes (i.e., procedurally generated `nonsense' objects). After constructing over 2000 unique image sets, we administer these tasks to human participants, collecting 35K trials of behavioral data from over 500 participants. This includes explicit choice behaviors as well as intermediate measures, such as reaction time and gaze data. We then evaluate the performance of common vision models (e.g., DINOv2, MAE, CLIP). We find that humans outperform all models by a wide margin. Using a multi-scale evaluation approach, we identify underlying similarities and differences between models and humans: while human-model performance is correlated, humans allocate more time/processing on challenging trials. All images, data, and code can be accessed via our project page.
Approaching human 3D shape perception with neurally mappable models
Sep 07, 2023Humans effortlessly infer the 3D shape of objects. What computations underlie this ability? Although various computational models have been proposed, none of them capture the human ability to match object shape across viewpoints. Here, we ask whether and how this gap might be closed. We begin with a relatively novel class of computational models, 3D neural fields, which encapsulate the basic principles of classic analysis-by-synthesis in a deep neural network (DNN). First, we find that a 3D Light Field Network (3D-LFN) supports 3D matching judgments well aligned to humans for within-category comparisons, adversarially-defined comparisons that accentuate the 3D failure cases of standard DNN models, and adversarially-defined comparisons for algorithmically generated shapes with no category structure. We then investigate the source of the 3D-LFN's ability to achieve human-aligned performance through a series of computational experiments. Exposure to multiple viewpoints of objects during training and a multi-view learning objective are the primary factors behind model-human alignment; even conventional DNN architectures come much closer to human behavior when trained with multi-view objectives. Finally, we find that while the models trained with multi-view learning objectives are able to partially generalize to new object categories, they fall short of human alignment. This work provides a foundation for understanding human shape inferences within neurally mappable computational architectures.