 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Policy Gradients for Robot Control
Feb 02, 2026Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.
mjlab: A Lightweight Framework for GPU-Accelerated Robot Learning
Jan 29, 2026We present mjlab, a lightweight, open-source framework for robot learning that combines GPU-accelerated simulation with composable environments and minimal setup friction. mjlab adopts the manager-based API introduced by Isaac Lab, where users compose modular building blocks for observations, rewards, and events, and pairs it with MuJoCo Warp for GPU-accelerated physics. The result is a framework installable with a single command, requiring minimal dependencies, and providing direct access to native MuJoCo data structures. mjlab ships with reference implementations of velocity tracking, motion imitation, and manipulation tasks.
Coordinated Humanoid Manipulation with Choice Policies
Dec 31, 2025Humanoid robots hold great promise for operating in human-centric environments, yet achieving robust whole-body coordination across the head, hands, and legs remains a major challenge. We present a system that combines a modular teleoperation interface with a scalable learning framework to address this problem. Our teleoperation design decomposes humanoid control into intuitive submodules, which include hand-eye coordination, grasp primitives, arm end-effector tracking, and locomotion. This modularity allows us to collect high-quality demonstrations efficiently. Building on this, we introduce Choice Policy, an imitation learning approach that generates multiple candidate actions and learns to score them. This architecture enables both fast inference and effective modeling of multimodal behaviors. We validate our approach on two real-world tasks: dishwasher loading and whole-body loco-manipulation for whiteboard wiping. Experiments show that Choice Policy significantly outperforms diffusion policies and standard behavior cloning. Furthermore, our results indicate that hand-eye coordination is critical for success in long-horizon tasks. Our work demonstrates a practical path toward scalable data collection and learning for coordinated humanoid manipulation in unstructured environments.
Viser: Imperative, Web-based 3D Visualization in Python
Jul 30, 2025We present Viser, a 3D visualization library for computer vision and robotics. Viser aims to bring easy and extensible 3D visualization to Python: we provide a comprehensive set of 3D scene and 2D GUI primitives, which can be used independently with minimal setup or composed to build specialized interfaces. This technical report describes Viser's features, interface, and implementation. Key design choices include an imperative-style API and a web-based viewer, which improve compatibility with modern programming patterns and workflows.
Flow Matching Policy Gradients
Jul 28, 2025Flow-based generative models, including diffusion models, excel at modeling continuous distributions in high-dimensional spaces. In this work, we introduce Flow Policy Optimization (FPO), a simple on-policy reinforcement learning algorithm that brings flow matching into the policy gradient framework. FPO casts policy optimization as maximizing an advantage-weighted ratio computed from the conditional flow matching loss, in a manner compatible with the popular PPO-clip framework. It sidesteps the need for exact likelihood computation while preserving the generative capabilities of flow-based models. Unlike prior approaches for diffusion-based reinforcement learning that bind training to a specific sampling method, FPO is agnostic to the choice of diffusion or flow integration at both training and inference time. We show that FPO can train diffusion-style policies from scratch in a variety of continuous control tasks. We find that flow-based models can capture multimodal action distributions and achieve higher performance than Gaussian policies, particularly in under-conditioned settings.
Eye, Robot: Learning to Look to Act with a BC-RL Perception-Action Loop
Jun 12, 2025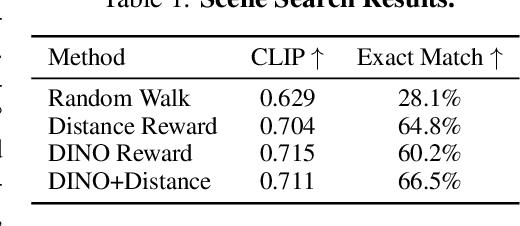
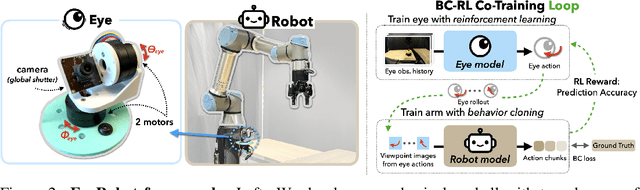


Humans do not passively observe the visual world -- we actively look in order to act. Motivated by this principle, we introduce EyeRobot, a robotic system with gaze behavior that emerges from the need to complete real-world tasks. We develop a mechanical eyeball that can freely rotate to observe its surroundings and train a gaze policy to control it using reinforcement learning. We accomplish this by first collecting teleoperated demonstrations paired with a 360 camera. This data is imported into a simulation environment that supports rendering arbitrary eyeball viewpoints, allowing episode rollouts of eye gaze on top of robot demonstrations. We then introduce a BC-RL loop to train the hand and eye jointly: the hand (BC) agent is trained from rendered eye observations, and the eye (RL) agent is rewarded when the hand produces correct action predictions. In this way, hand-eye coordination emerges as the eye looks towards regions which allow the hand to complete the task. EyeRobot implements a foveal-inspired policy architecture allowing high resolution with a small compute budget, which we find also leads to the emergence of more stable fixation as well as improved ability to track objects and ignore distractors. We evaluate EyeRobot on five panoramic workspace manipulation tasks requiring manipulation in an arc surrounding the robot arm. Our experiments suggest EyeRobot exhibits hand-eye coordination behaviors which effectively facilitate manipulation over large workspaces with a single camera. See project site for videos: https://www.eyerobot.net/
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
May 06, 2025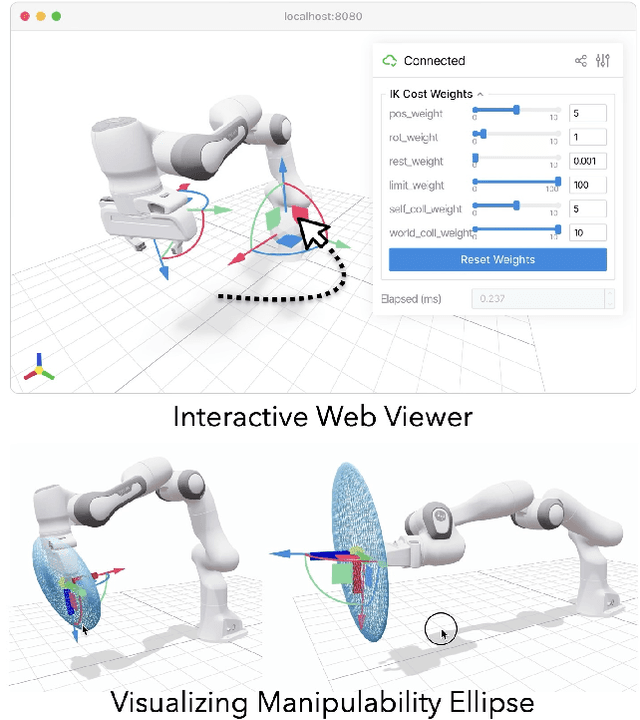
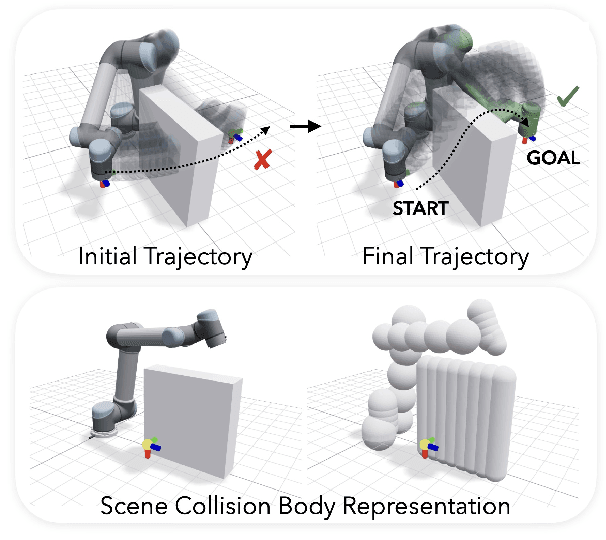
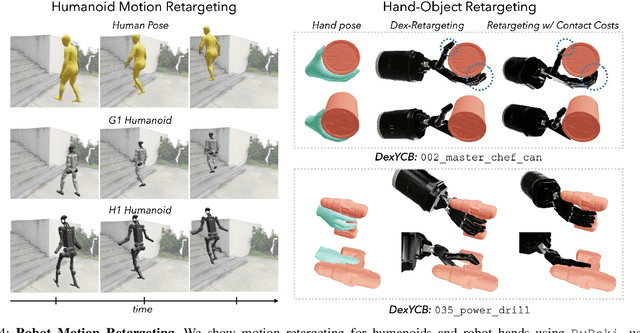
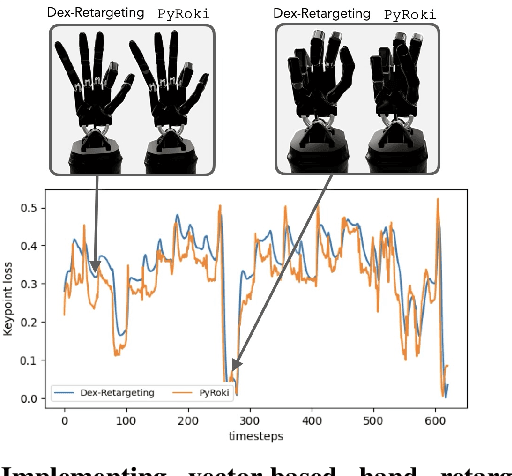
Robot motion can have many goals. Depending on the task, we might optimize for pose error, speed, collision, or similarity to a human demonstration. Motivated by this, we present PyRoki: a modular, extensible, and cross-platform toolkit for solving kinematic optimization problems. PyRoki couples an interface for specifying kinematic variables and costs with an efficient nonlinear least squares optimizer. Unlike existing tools, it is also cross-platform: optimization runs natively on CPU, GPU, and TPU. In this paper, we present (i) the design and implementation of PyRoki, (ii) motion retargeting and planning case studies that highlight the advantages of PyRoki's modularity, and (iii) optimization benchmarking, where PyRoki can be 1.4-1.7x faster and converges to lower errors than cuRobo, an existing GPU-accelerated inverse kinematics library.
Predict-Optimize-Distill: A Self-Improving Cycle for 4D Object Understanding
Apr 24, 2025Humans can resort to long-form inspection to build intuition on predicting the 3D configurations of unseen objects. The more we observe the object motion, the better we get at predicting its 3D state immediately. Existing systems either optimize underlying representations from multi-view observations or train a feed-forward predictor from supervised datasets. We introduce Predict-Optimize-Distill (POD), a self-improving framework that interleaves prediction and optimization in a mutually reinforcing cycle to achieve better 4D object understanding with increasing observation time. Given a multi-view object scan and a long-form monocular video of human-object interaction, POD iteratively trains a neural network to predict local part poses from RGB frames, uses this predictor to initialize a global optimization which refines output poses through inverse rendering, then finally distills the results of optimization back into the model by generating synthetic self-labeled training data from novel viewpoints. Each iteration improves both the predictive model and the optimized motion trajectory, creating a virtuous cycle that bootstraps its own training data to learn about the pose configurations of an object. We also introduce a quasi-multiview mining strategy for reducing depth ambiguity by leveraging long video. We evaluate POD on 14 real-world and 5 synthetic objects with various joint types, including revolute and prismatic joints as well as multi-body configurations where parts detach or reattach independently. POD demonstrates significant improvement over a pure optimization baseline which gets stuck in local minima, particularly for longer videos. We also find that POD's performance improves with both video length and successive iterations of the self-improving cycle, highlighting its ability to scale performance with additional observations and looped refinement.
From Simple to Complex Skills: The Case of In-Hand Object Reorientation
Jan 09, 2025



Learning policies in simulation and transferring them to the real world has become a promising approach in dexterous manipulation. However, bridging the sim-to-real gap for each new task requires substantial human effort, such as careful reward engineering, hyperparameter tuning, and system identification. In this work, we present a system that leverages low-level skills to address these challenges for more complex tasks. Specifically, we introduce a hierarchical policy for in-hand object reorientation based on previously acquired rotation skills. This hierarchical policy learns to select which low-level skill to execute based on feedback from both the environment and the low-level skill policies themselves. Compared to learning from scratch, the hierarchical policy is more robust to out-of-distribution changes and transfers easily from simulation to real-world environments. Additionally, we propose a generalizable object pose estimator that uses proprioceptive information, low-level skill predictions, and control errors as inputs to estimate the object pose over time. We demonstrate that our system can reorient objects, including symmetrical and textureless ones, to a desired pose.
Reconstructing People, Places, and Cameras
Dec 23, 2024



We present "Humans and Structure from Motion" (HSfM), a method for jointly reconstructing multiple human meshes, scene point clouds, and camera parameters in a metric world coordinate system from a sparse set of uncalibrated multi-view images featuring people. Our approach combines data-driven scene reconstruction with the traditional Structure-from-Motion (SfM) framework to achieve more accurate scene reconstruction and camera estimation, while simultaneously recovering human meshes. In contrast to existing scene reconstruction and SfM methods that lack metric scale information, our method estimates approximate metric scale by leveraging a human statistical model. Furthermore, it reconstructs multiple human meshes within the same world coordinate system alongside the scene point cloud, effectively capturing spatial relationships among individuals and their positions in the environment. We initialize the reconstruction of humans, scenes, and cameras using robust foundational models and jointly optimize these elements. This joint optimization synergistically improves the accuracy of each component. We compare our method to existing approaches on two challenging benchmarks, EgoHumans and EgoExo4D, demonstrating significant improvements in human localization accuracy within the world coordinate frame (reducing error from 3.51m to 1.04m in EgoHumans and from 2.9m to 0.56m in EgoExo4D). Notably, our results show that incorporating human data into the SfM pipeline improves camera pose estimation (e.g., increasing RRA@15 by 20.3% on EgoHumans). Additionally, qualitative results show that our approach improves overall scene reconstruction quality. Our code is available at: muelea.github.io/hsfm.