 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Hardware-Agnostic Quadrupedal World Models via Morphology Conditioning
Apr 09, 2026World models promise a paradigm shift in robotics, where an agent learns the underlying physics of its environment once to enable efficient planning and behavior learning. However, current world models are often hardware-locked specialists: a model trained on a Boston Dynamics Spot robot fails catastrophically on a Unitree Go1 due to the mismatch in kinematic and dynamic properties, as the model overfits to specific embodiment constraints rather than capturing the universal locomotion dynamics. Consequently, a slight change in actuator dynamics or limb length necessitates training a new model from scratch. In this work, we take a step towards a framework for training a generalizable Quadrupedal World Model (QWM) that disentangles environmental dynamics from robot morphology. We address the limitations of implicit system identification, where treating static physical properties (like mass or limb length) as latent variables to be inferred from motion history creates an adaptation lag that can compromise zero-shot safety and efficiency. Instead, we explicitly condition the generative dynamics on the robot's engineering specifications. By integrating a physical morphology encoder and a reward normalizer, we enable the model to serve as a neural simulator capable of generalizing across morphologies. This capability unlocks zero-shot control across a range of embodiments. We introduce, for the first time, a world model that enables zero-shot generalization to new morphologies for locomotion. While we carefully study the limitations of our method, QWM operates as a distribution-bounded interpolator within the quadrupedal morphology family rather than a universal physics engine, this work represents a significant step toward morphology-conditioned world models for legged locomotion.
Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations
Jan 02, 2026Diffusion policies have emerged as powerful generative models for offline policy learning, whose sampling process can be rigorously characterized by a score function guiding a Stochastic Differential Equation (SDE). However, the same score-based SDE modeling that grants diffusion policies the flexibility to learn diverse behavior also incurs solver and score-matching errors, large data requirements, and inconsistencies in action generation. While less critical in image generation, these inaccuracies compound and lead to failure in continuous control settings. We introduce Contractive Diffusion Policies (CDPs) to induce contractive behavior in the diffusion sampling dynamics. Contraction pulls nearby flows closer to enhance robustness against solver and score-matching errors while reducing unwanted action variance. We develop an in-depth theoretical analysis along with a practical implementation recipe to incorporate CDPs into existing diffusion policy architectures with minimal modification and computational cost. We evaluate CDPs for offline learning by conducting extensive experiments in simulation and real-world settings. Across benchmarks, CDPs often outperform baseline policies, with pronounced benefits under data scarcity.
Safe Domain Randomization via Uncertainty-Aware Out-of-Distribution Detection and Policy Adaptation
Jul 08, 2025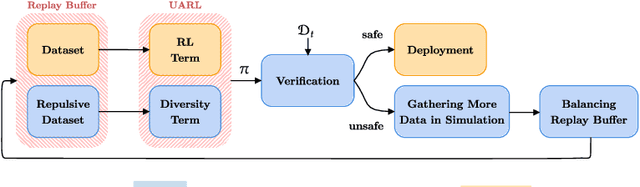
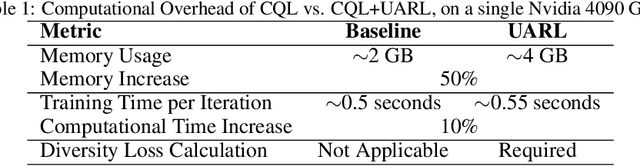


Deploying reinforcement learning (RL) policies in real-world involves significant challenges, including distribution shifts, safety concerns, and the impracticality of direct interactions during policy refinement. Existing methods, such as domain randomization (DR) and off-dynamics RL, enhance policy robustness by direct interaction with the target domain, an inherently unsafe practice. We propose Uncertainty-Aware RL (UARL), a novel framework that prioritizes safety during training by addressing Out-Of-Distribution (OOD) detection and policy adaptation without requiring direct interactions in target domain. UARL employs an ensemble of critics to quantify policy uncertainty and incorporates progressive environmental randomization to prepare the policy for diverse real-world conditions. By iteratively refining over high-uncertainty regions of the state space in simulated environments, UARL enhances robust generalization to the target domain without explicitly training on it. We evaluate UARL on MuJoCo benchmarks and a quadrupedal robot, demonstrating its effectiveness in reliable OOD detection, improved performance, and enhanced sample efficiency compared to baselines.
Learning to Coordinate with Experts
Feb 13, 2025When deployed in dynamic environments, AI agents will inevitably encounter challenges that exceed their individual capabilities. Leveraging assistance from expert agents-whether human or AI-can significantly enhance safety and performance in such situations. However, querying experts is often costly, necessitating the development of agents that can efficiently request and utilize expert guidance. In this paper, we introduce a fundamental coordination problem called Learning to Yield and Request Control (YRC), where the objective is to learn a strategy that determines when to act autonomously and when to seek expert assistance. We consider a challenging practical setting in which an agent does not interact with experts during training but must adapt to novel environmental changes and expert interventions at test time. To facilitate empirical research, we introduce YRC-Bench, an open-source benchmark featuring diverse domains. YRC-Bench provides a standardized Gym-like API, simulated experts, evaluation pipeline, and implementation of competitive baselines. Towards tackling the YRC problem, we propose a novel validation approach and investigate the performance of various learning methods across diverse environments, yielding insights that can guide future research.
Getting By Goal Misgeneralization With a Little Help From a Mentor
Oct 28, 2024While reinforcement learning (RL) agents often perform well during training, they can struggle with distribution shift in real-world deployments. One particularly severe risk of distribution shift is goal misgeneralization, where the agent learns a proxy goal that coincides with the true goal during training but not during deployment. In this paper, we explore whether allowing an agent to ask for help from a supervisor in unfamiliar situations can mitigate this issue. We focus on agents trained with PPO in the CoinRun environment, a setting known to exhibit goal misgeneralization. We evaluate multiple methods for determining when the agent should request help and find that asking for help consistently improves performance. However, we also find that methods based on the agent's internal state fail to proactively request help, instead waiting until mistakes have already occurred. Further investigation suggests that the agent's internal state does not represent the coin at all, highlighting the importance of learning nuanced representations, the risks of ignoring everything not immediately relevant to reward, and the necessity of developing ask-for-help strategies tailored to the agent's training algorithm.
Taming the Tail in Class-Conditional GANs: Knowledge Sharing via Unconditional Training at Lower Resolutions
Feb 26, 2024
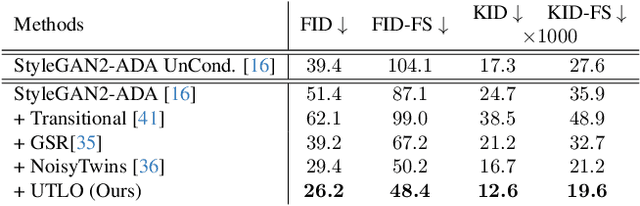
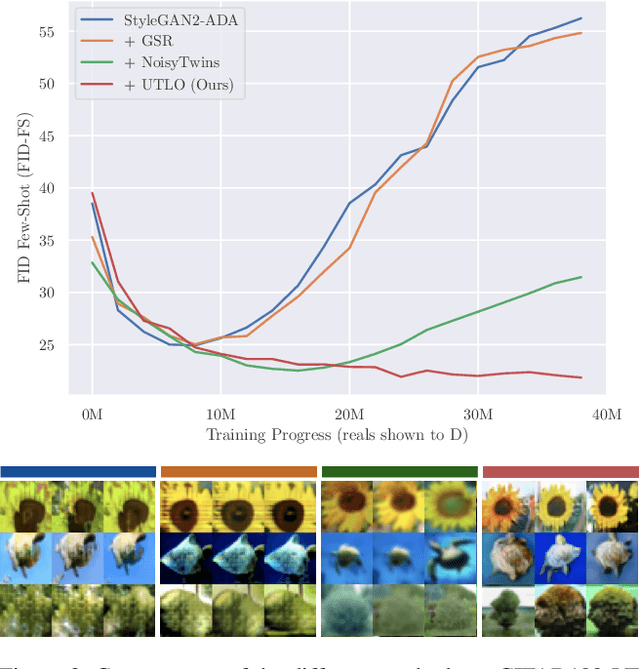

Despite the extensive research on training generative adversarial networks (GANs) with limited training data, learning to generate images from long-tailed training distributions remains fairly unexplored. In the presence of imbalanced multi-class training data, GANs tend to favor classes with more samples, leading to the generation of low-quality and less diverse samples in tail classes. In this study, we aim to improve the training of class-conditional GANs with long-tailed data. We propose a straightforward yet effective method for knowledge sharing, allowing tail classes to borrow from the rich information from classes with more abundant training data. More concretely, we propose modifications to existing class-conditional GAN architectures to ensure that the lower-resolution layers of the generator are trained entirely unconditionally while reserving class-conditional generation for the higher-resolution layers. Experiments on several long-tail benchmarks and GAN architectures demonstrate a significant improvement over existing methods in both the diversity and fidelity of the generated images. The code is available at https://github.com/khorrams/utlo.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Contextual Pre-Planning on Reward Machine Abstractions for Enhanced Transfer in Deep Reinforcement Learning
Jul 11, 2023Recent studies show that deep reinforcement learning (DRL) agents tend to overfit to the task on which they were trained and fail to adapt to minor environment changes. To expedite learning when transferring to unseen tasks, we propose a novel approach to representing the current task using reward machines (RM), state machine abstractions that induce subtasks based on the current task's rewards and dynamics. Our method provides agents with symbolic representations of optimal transitions from their current abstract state and rewards them for achieving these transitions. These representations are shared across tasks, allowing agents to exploit knowledge of previously encountered symbols and transitions, thus enhancing transfer. Our empirical evaluation shows that our representations improve sample efficiency and few-shot transfer in a variety of domains.
LEADER: Learning Attention over Driving Behaviors for Planning under Uncertainty
Sep 23, 2022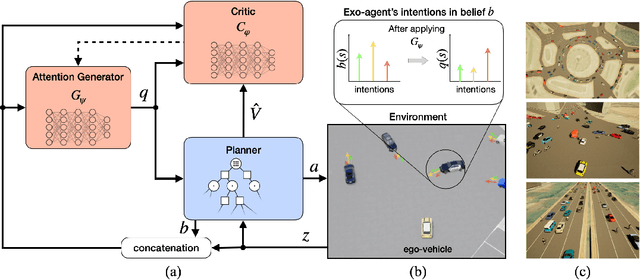

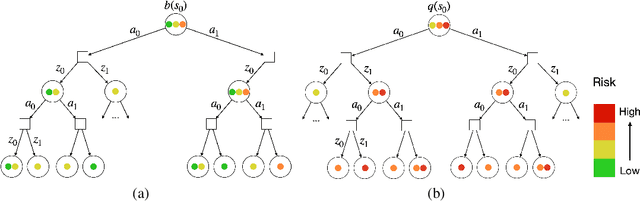
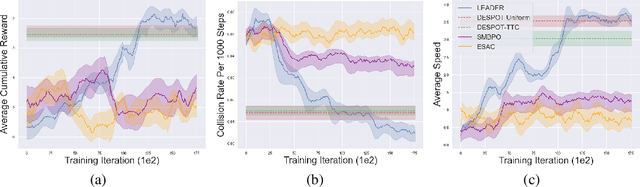
Uncertainty on human behaviors poses a significant challenge to autonomous driving in crowded urban environments. The partially observable Markov decision processes (POMDPs) offer a principled framework for planning under uncertainty, often leveraging Monte Carlo sampling to achieve online performance for complex tasks. However, sampling also raises safety concerns by potentially missing critical events. To address this, we propose a new algorithm, LEarning Attention over Driving bEhavioRs (LEADER), that learns to attend to critical human behaviors during planning. LEADER learns a neural network generator to provide attention over human behaviors in real-time situations. It integrates the attention into a belief-space planner, using importance sampling to bias reasoning towards critical events. To train the algorithm, we let the attention generator and the planner form a min-max game. By solving the min-max game, LEADER learns to perform risk-aware planning without human labeling.
Stochastic Block-ADMM for Training Deep Networks
May 01, 2021

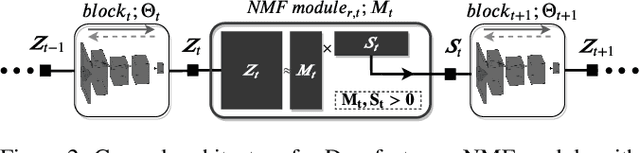
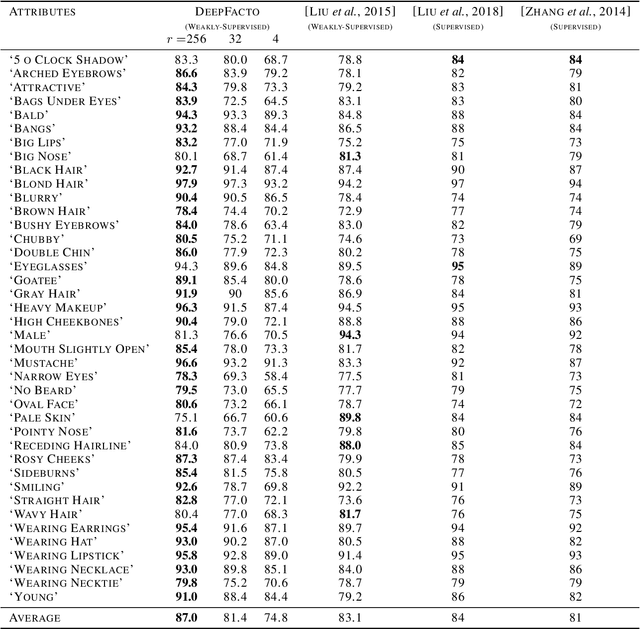
In this paper, we propose Stochastic Block-ADMM as an approach to train deep neural networks in batch and online settings. Our method works by splitting neural networks into an arbitrary number of blocks and utilizes auxiliary variables to connect these blocks while optimizing with stochastic gradient descent. This allows training deep networks with non-differentiable constraints where conventional backpropagation is not applicable. An application of this is supervised feature disentangling, where our proposed DeepFacto inserts a non-negative matrix factorization (NMF) layer into the network. Since backpropagation only needs to be performed within each block, our approach alleviates vanishing gradients and provides potentials for parallelization. We prove the convergence of our proposed method and justify its capabilities through experiments in supervised and weakly-supervised settings.