 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanoid Hanoi: Investigating Shared Whole-Body Control for Skill-Based Box Rearrangement
Feb 14, 2026We investigate a skill-based framework for humanoid box rearrangement that enables long-horizon execution by sequencing reusable skills at the task level. In our architecture, all skills execute through a shared, task-agnostic whole-body controller (WBC), providing a consistent closed-loop interface for skill composition, in contrast to non-shared designs that use separate low-level controllers per skill. We find that naively reusing the same pretrained WBC can reduce robustness over long horizons, as new skills and their compositions induce shifted state and command distributions. We address this with a simple data aggregation procedure that augments shared-WBC training with rollouts from closed-loop skill execution under domain randomization. To evaluate the approach, we introduce \emph{Humanoid Hanoi}, a long-horizon Tower-of-Hanoi box rearrangement benchmark, and report results in simulation and on the Digit V3 humanoid robot, demonstrating fully autonomous rearrangement over extended horizons and quantifying the benefits of the shared-WBC approach over non-shared baselines.
Long-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction
Dec 11, 2025



Recent advances in generalizable Gaussian splatting (GS) have enabled feed-forward reconstruction of scenes from tens of input views. Long-LRM notably scales this paradigm to 32 input images at $950\times540$ resolution, achieving 360° scene-level reconstruction in a single forward pass. However, directly predicting millions of Gaussian parameters at once remains highly error-sensitive: small inaccuracies in positions or other attributes lead to noticeable blurring, particularly in fine structures such as text. In parallel, implicit representation methods such as LVSM and LaCT have demonstrated significantly higher rendering fidelity by compressing scene information into model weights rather than explicit Gaussians, and decoding RGB frames using the full transformer or TTT backbone. However, this computationally intensive decompression process for every rendered frame makes real-time rendering infeasible. These observations raise key questions: Is the deep, sequential "decompression" process necessary? Can we retain the benefits of implicit representations while enabling real-time performance? We address these questions with Long-LRM++, a model that adopts a semi-explicit scene representation combined with a lightweight decoder. Long-LRM++ matches the rendering quality of LaCT on DL3DV while achieving real-time 14 FPS rendering on an A100 GPU, overcoming the speed limitations of prior implicit methods. Our design also scales to 64 input views at the $950\times540$ resolution, demonstrating strong generalization to increased input lengths. Additionally, Long-LRM++ delivers superior novel-view depth prediction on ScanNetv2 compared to direct depth rendering from Gaussians. Extensive ablation studies validate the effectiveness of each component in the proposed framework.
GS4: Generalizable Sparse Splatting Semantic SLAM
Jun 06, 2025Traditional SLAM algorithms are excellent at camera tracking but might generate lower resolution and incomplete 3D maps. Recently, Gaussian Splatting (GS) approaches have emerged as an option for SLAM with accurate, dense 3D map building. However, existing GS-based SLAM methods rely on per-scene optimization which is time-consuming and does not generalize to diverse scenes well. In this work, we introduce the first generalizable GS-based semantic SLAM algorithm that incrementally builds and updates a 3D scene representation from an RGB-D video stream using a learned generalizable network. Our approach starts from an RGB-D image recognition backbone to predict the Gaussian parameters from every downsampled and backprojected image location. Additionally, we seamlessly integrate 3D semantic segmentation into our GS framework, bridging 3D mapping and recognition through a shared backbone. To correct localization drifting and floaters, we propose to optimize the GS for only 1 iteration following global localization. We demonstrate state-of-the-art semantic SLAM performance on the real-world benchmark ScanNet with an order of magnitude fewer Gaussians compared to other recent GS-based methods, and showcase our model's generalization capability through zero-shot transfer to the NYUv2 and TUM RGB-D datasets.
Point-based Instance Completion with Scene Constraints
Apr 08, 2025Recent point-based object completion methods have demonstrated the ability to accurately recover the missing geometry of partially observed objects. However, these approaches are not well-suited for completing objects within a scene, as they do not consider known scene constraints (e.g., other observed surfaces) in their completions and further expect the partial input to be in a canonical coordinate system, which does not hold for objects within scenes. While instance scene completion methods have been proposed for completing objects within a scene, they lag behind point-based object completion methods in terms of object completion quality and still do not consider known scene constraints during completion. To overcome these limitations, we propose a point cloud-based instance completion model that can robustly complete objects at arbitrary scales and pose in the scene. To enable reasoning at the scene level, we introduce a sparse set of scene constraints represented as point clouds and integrate them into our completion model via a cross-attention mechanism. To evaluate the instance scene completion task on indoor scenes, we further build a new dataset called ScanWCF, which contains labeled partial scans as well as aligned ground truth scene completions that are watertight and collision-free. Through several experiments, we demonstrate that our method achieves improved fidelity to partial scans, higher completion quality, and greater plausibility over existing state-of-the-art methods.
Where do Large Vision-Language Models Look at when Answering Questions?
Mar 18, 2025Large Vision-Language Models (LVLMs) have shown promising performance in vision-language understanding and reasoning tasks. However, their visual understanding behaviors remain underexplored. A fundamental question arises: to what extent do LVLMs rely on visual input, and which image regions contribute to their responses? It is non-trivial to interpret the free-form generation of LVLMs due to their complicated visual architecture (e.g., multiple encoders and multi-resolution) and variable-length outputs. In this paper, we extend existing heatmap visualization methods (e.g., iGOS++) to support LVLMs for open-ended visual question answering. We propose a method to select visually relevant tokens that reflect the relevance between generated answers and input image. Furthermore, we conduct a comprehensive analysis of state-of-the-art LVLMs on benchmarks designed to require visual information to answer. Our findings offer several insights into LVLM behavior, including the relationship between focus region and answer correctness, differences in visual attention across architectures, and the impact of LLM scale on visual understanding. The code and data are available at https://github.com/bytedance/LVLM_Interpretation.
PointRecon: Online Point-based 3D Reconstruction via Ray-based 2D-3D Matching
Oct 30, 2024We propose a novel online, point-based 3D reconstruction method from posed monocular RGB videos. Our model maintains a global point cloud representation of the scene, continuously updating the features and 3D locations of points as new images are observed. It expands the point cloud with newly detected points while carefully removing redundancies. The point cloud updates and depth predictions for new points are achieved through a novel ray-based 2D-3D feature matching technique, which is robust against errors in previous point position predictions. In contrast to offline methods, our approach processes infinite-length sequences and provides real-time updates. Additionally, the point cloud imposes no pre-defined resolution or scene size constraints, and its unified global representation ensures view consistency across perspectives. Experiments on the ScanNet dataset show that our method achieves state-of-the-art quality among online MVS approaches. Project page: https://arthurhero.github.io/projects/pointrecon
Long-LRM: Long-sequence Large Reconstruction Model for Wide-coverage Gaussian Splats
Oct 16, 2024



We propose Long-LRM, a generalizable 3D Gaussian reconstruction model that is capable of reconstructing a large scene from a long sequence of input images. Specifically, our model can process 32 source images at 960x540 resolution within only 1.3 seconds on a single A100 80G GPU. Our architecture features a mixture of the recent Mamba2 blocks and the classical transformer blocks which allowed many more tokens to be processed than prior work, enhanced by efficient token merging and Gaussian pruning steps that balance between quality and efficiency. Unlike previous feed-forward models that are limited to processing 1~4 input images and can only reconstruct a small portion of a large scene, Long-LRM reconstructs the entire scene in a single feed-forward step. On large-scale scene datasets such as DL3DV-140 and Tanks and Temples, our method achieves performance comparable to optimization-based approaches while being two orders of magnitude more efficient. Project page: https://arthurhero.github.io/projects/llrm
Long-Term 3D Point Tracking By Cost Volume Fusion
Jul 18, 2024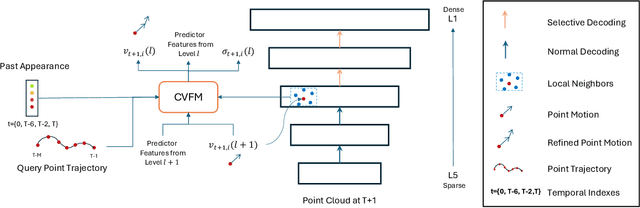
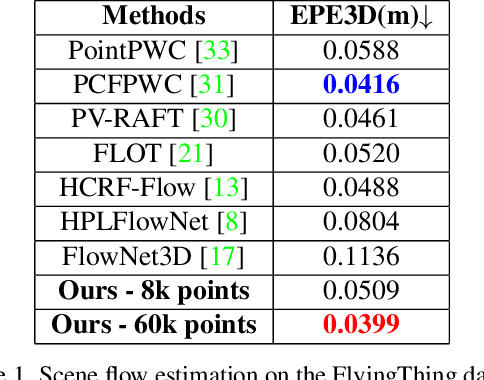
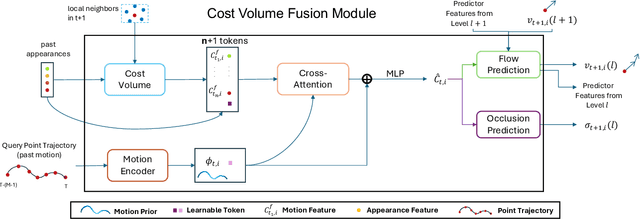
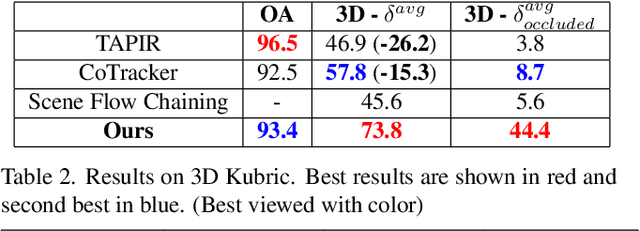
Long-term point tracking is essential to understand non-rigid motion in the physical world better. Deep learning approaches have recently been incorporated into long-term point tracking, but most prior work predominantly functions in 2D. Although these methods benefit from the well-established backbones and matching frameworks, the motions they produce do not always make sense in the 3D physical world. In this paper, we propose the first deep learning framework for long-term point tracking in 3D that generalizes to new points and videos without requiring test-time fine-tuning. Our model contains a cost volume fusion module that effectively integrates multiple past appearances and motion information via a transformer architecture, significantly enhancing overall tracking performance. In terms of 3D tracking performance, our model significantly outperforms simple scene flow chaining and previous 2D point tracking methods, even if one uses ground truth depth and camera pose to backproject 2D point tracks in a synthetic scenario.
Point Cloud Models Improve Visual Robustness in Robotic Learners
Apr 29, 2024



Visual control policies can encounter significant performance degradation when visual conditions like lighting or camera position differ from those seen during training -- often exhibiting sharp declines in capability even for minor differences. In this work, we examine robustness to a suite of these types of visual changes for RGB-D and point cloud based visual control policies. To perform these experiments on both model-free and model-based reinforcement learners, we introduce a novel Point Cloud World Model (PCWM) and point cloud based control policies. Our experiments show that policies that explicitly encode point clouds are significantly more robust than their RGB-D counterparts. Further, we find our proposed PCWM significantly outperforms prior works in terms of sample efficiency during training. Taken together, these results suggest reasoning about the 3D scene through point clouds can improve performance, reduce learning time, and increase robustness for robotic learners. Project Webpage: https://pvskand.github.io/projects/PCWM
Object Dynamics Modeling with Hierarchical Point Cloud-based Representations
Apr 09, 2024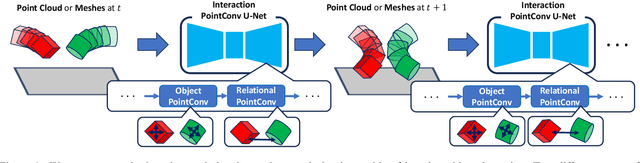



Modeling object dynamics with a neural network is an important problem with numerous applications. Most recent work has been based on graph neural networks. However, physics happens in 3D space, where geometric information potentially plays an important role in modeling physical phenomena. In this work, we propose a novel U-net architecture based on continuous point convolution which naturally embeds information from 3D coordinates and allows for multi-scale feature representations with established downsampling and upsampling procedures. Bottleneck layers in the downsampled point clouds lead to better long-range interaction modeling. Besides, the flexibility of point convolutions allows our approach to generalize to sparsely sampled points from mesh vertices and dynamically generate features on important interaction points on mesh faces. Experimental results demonstrate that our approach significantly improves the state-of-the-art, especially in scenarios that require accurate gravity or collision reasoning.