 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperEdit: Rectifying and Facilitating Supervision for Instruction-Based Image Editing
May 05, 2025Due to the challenges of manually collecting accurate editing data, existing datasets are typically constructed using various automated methods, leading to noisy supervision signals caused by the mismatch between editing instructions and original-edited image pairs. Recent efforts attempt to improve editing models through generating higher-quality edited images, pre-training on recognition tasks, or introducing vision-language models (VLMs) but fail to resolve this fundamental issue. In this paper, we offer a novel solution by constructing more effective editing instructions for given image pairs. This includes rectifying the editing instructions to better align with the original-edited image pairs and using contrastive editing instructions to further enhance their effectiveness. Specifically, we find that editing models exhibit specific generation attributes at different inference steps, independent of the text. Based on these prior attributes, we define a unified guide for VLMs to rectify editing instructions. However, there are some challenging editing scenarios that cannot be resolved solely with rectified instructions. To this end, we further construct contrastive supervision signals with positive and negative instructions and introduce them into the model training using triplet loss, thereby further facilitating supervision effectiveness. Our method does not require the VLM modules or pre-training tasks used in previous work, offering a more direct and efficient way to provide better supervision signals, and providing a novel, simple, and effective solution for instruction-based image editing. Results on multiple benchmarks demonstrate that our method significantly outperforms existing approaches. Compared with previous SOTA SmartEdit, we achieve 9.19% improvements on the Real-Edit benchmark with 30x less training data and 13x smaller model size.
Where do Large Vision-Language Models Look at when Answering Questions?
Mar 18, 2025Large Vision-Language Models (LVLMs) have shown promising performance in vision-language understanding and reasoning tasks. However, their visual understanding behaviors remain underexplored. A fundamental question arises: to what extent do LVLMs rely on visual input, and which image regions contribute to their responses? It is non-trivial to interpret the free-form generation of LVLMs due to their complicated visual architecture (e.g., multiple encoders and multi-resolution) and variable-length outputs. In this paper, we extend existing heatmap visualization methods (e.g., iGOS++) to support LVLMs for open-ended visual question answering. We propose a method to select visually relevant tokens that reflect the relevance between generated answers and input image. Furthermore, we conduct a comprehensive analysis of state-of-the-art LVLMs on benchmarks designed to require visual information to answer. Our findings offer several insights into LVLM behavior, including the relationship between focus region and answer correctness, differences in visual attention across architectures, and the impact of LLM scale on visual understanding. The code and data are available at https://github.com/bytedance/LVLM_Interpretation.
Focus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

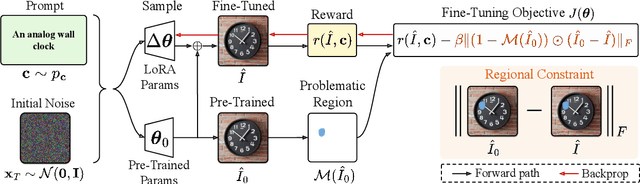
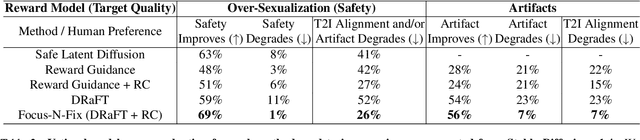
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Active Open-Vocabulary Recognition: Let Intelligent Moving Mitigate CLIP Limitations
Nov 28, 2023



Active recognition, which allows intelligent agents to explore observations for better recognition performance, serves as a prerequisite for various embodied AI tasks, such as grasping, navigation and room arrangements. Given the evolving environment and the multitude of object classes, it is impractical to include all possible classes during the training stage. In this paper, we aim at advancing active open-vocabulary recognition, empowering embodied agents to actively perceive and classify arbitrary objects. However, directly adopting recent open-vocabulary classification models, like Contrastive Language Image Pretraining (CLIP), poses its unique challenges. Specifically, we observe that CLIP's performance is heavily affected by the viewpoint and occlusions, compromising its reliability in unconstrained embodied perception scenarios. Further, the sequential nature of observations in agent-environment interactions necessitates an effective method for integrating features that maintains discriminative strength for open-vocabulary classification. To address these issues, we introduce a novel agent for active open-vocabulary recognition. The proposed method leverages inter-frame and inter-concept similarities to navigate agent movements and to fuse features, without relying on class-specific knowledge. Compared to baseline CLIP model with 29.6% accuracy on ShapeNet dataset, the proposed agent could achieve 53.3% accuracy for open-vocabulary recognition, without any fine-tuning to the equipped CLIP model. Additional experiments conducted with the Habitat simulator further affirm the efficacy of our method.
Fairness-Aware Unsupervised Feature Selection
Jun 04, 2021



Feature selection is a prevalent data preprocessing paradigm for various learning tasks. Due to the expensive cost of acquiring supervision information, unsupervised feature selection sparks great interests recently. However, existing unsupervised feature selection algorithms do not have fairness considerations and suffer from a high risk of amplifying discrimination by selecting features that are over associated with protected attributes such as gender, race, and ethnicity. In this paper, we make an initial investigation of the fairness-aware unsupervised feature selection problem and develop a principled framework, which leverages kernel alignment to find a subset of high-quality features that can best preserve the information in the original feature space while being minimally correlated with protected attributes. Specifically, different from the mainstream in-processing debiasing methods, our proposed framework can be regarded as a model-agnostic debiasing strategy that eliminates biases and discrimination before downstream learning algorithms are involved. Experimental results on multiple real-world datasets demonstrate that our framework achieves a good trade-off between utility maximization and fairness promotion.
DCSFN: Deep Cross-scale Fusion Network for Single Image Rain Removal
Aug 03, 2020


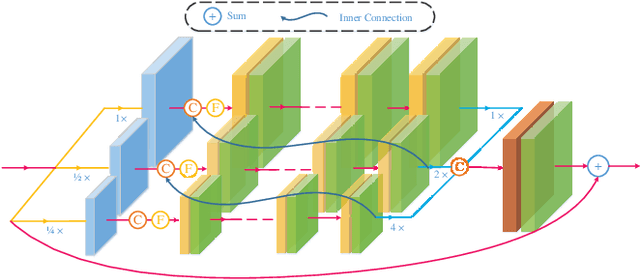
Rain removal is an important but challenging computer vision task as rain streaks can severely degrade the visibility of images that may make other visions or multimedia tasks fail to work. Previous works mainly focused on feature extraction and processing or neural network structure, while the current rain removal methods can already achieve remarkable results, training based on single network structure without considering the cross-scale relationship may cause information drop-out. In this paper, we explore the cross-scale manner between networks and inner-scale fusion operation to solve the image rain removal task. Specifically, to learn features with different scales, we propose a multi-sub-networks structure, where these sub-networks are fused via a crossscale manner by Gate Recurrent Unit to inner-learn and make full use of information at different scales in these sub-networks. Further, we design an inner-scale connection block to utilize the multi-scale information and features fusion way between different scales to improve rain representation ability and we introduce the dense block with skip connection to inner-connect these blocks. Experimental results on both synthetic and real-world datasets have demonstrated the superiority of our proposed method, which outperforms over the state-of-the-art methods. The source code will be available at https://supercong94.wixsite.com/supercong94.