 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperEdit: Rectifying and Facilitating Supervision for Instruction-Based Image Editing
May 05, 2025Due to the challenges of manually collecting accurate editing data, existing datasets are typically constructed using various automated methods, leading to noisy supervision signals caused by the mismatch between editing instructions and original-edited image pairs. Recent efforts attempt to improve editing models through generating higher-quality edited images, pre-training on recognition tasks, or introducing vision-language models (VLMs) but fail to resolve this fundamental issue. In this paper, we offer a novel solution by constructing more effective editing instructions for given image pairs. This includes rectifying the editing instructions to better align with the original-edited image pairs and using contrastive editing instructions to further enhance their effectiveness. Specifically, we find that editing models exhibit specific generation attributes at different inference steps, independent of the text. Based on these prior attributes, we define a unified guide for VLMs to rectify editing instructions. However, there are some challenging editing scenarios that cannot be resolved solely with rectified instructions. To this end, we further construct contrastive supervision signals with positive and negative instructions and introduce them into the model training using triplet loss, thereby further facilitating supervision effectiveness. Our method does not require the VLM modules or pre-training tasks used in previous work, offering a more direct and efficient way to provide better supervision signals, and providing a novel, simple, and effective solution for instruction-based image editing. Results on multiple benchmarks demonstrate that our method significantly outperforms existing approaches. Compared with previous SOTA SmartEdit, we achieve 9.19% improvements on the Real-Edit benchmark with 30x less training data and 13x smaller model size.
Vidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
Where do Large Vision-Language Models Look at when Answering Questions?
Mar 18, 2025Large Vision-Language Models (LVLMs) have shown promising performance in vision-language understanding and reasoning tasks. However, their visual understanding behaviors remain underexplored. A fundamental question arises: to what extent do LVLMs rely on visual input, and which image regions contribute to their responses? It is non-trivial to interpret the free-form generation of LVLMs due to their complicated visual architecture (e.g., multiple encoders and multi-resolution) and variable-length outputs. In this paper, we extend existing heatmap visualization methods (e.g., iGOS++) to support LVLMs for open-ended visual question answering. We propose a method to select visually relevant tokens that reflect the relevance between generated answers and input image. Furthermore, we conduct a comprehensive analysis of state-of-the-art LVLMs on benchmarks designed to require visual information to answer. Our findings offer several insights into LVLM behavior, including the relationship between focus region and answer correctness, differences in visual attention across architectures, and the impact of LLM scale on visual understanding. The code and data are available at https://github.com/bytedance/LVLM_Interpretation.
Rethinking Homogeneity of Vision and Text Tokens in Large Vision-and-Language Models
Feb 04, 2025



Large vision-and-language models (LVLMs) typically treat visual and textual embeddings as homogeneous inputs to a large language model (LLM). However, these inputs are inherently different: visual inputs are multi-dimensional and contextually rich, often pre-encoded by models like CLIP, while textual inputs lack this structure. In this paper, we propose Decomposed Attention (D-Attn), a novel method that processes visual and textual embeddings differently by decomposing the 1-D causal self-attention in LVLMs. After the attention decomposition, D-Attn diagonalizes visual-to-visual self-attention, reducing computation from $\mathcal{O}(|V|^2)$ to $\mathcal{O}(|V|)$ for $|V|$ visual embeddings without compromising performance. Moreover, D-Attn debiases positional encodings in textual-to-visual cross-attention, further enhancing visual understanding. Finally, we introduce an $\alpha$-weighting strategy to merge visual and textual information, maximally preserving the pre-trained LLM's capabilities with minimal modifications. Extensive experiments and rigorous analyses validate the effectiveness of D-Attn, demonstrating significant improvements on multiple image benchmarks while significantly reducing computational costs. Code, data, and models will be publicly available.
Multi-Reward as Condition for Instruction-based Image Editing
Nov 06, 2024
High-quality training triplets (instruction, original image, edited image) are essential for instruction-based image editing. Predominant training datasets (e.g., InsPix2Pix) are created using text-to-image generative models (e.g., Stable Diffusion, DALL-E) which are not trained for image editing. Accordingly, these datasets suffer from inaccurate instruction following, poor detail preserving, and generation artifacts. In this paper, we propose to address the training data quality issue with multi-perspective reward data instead of refining the ground-truth image quality. 1) we first design a quantitative metric system based on best-in-class LVLM (Large Vision Language Model), i.e., GPT-4o in our case, to evaluate the generation quality from 3 perspectives, namely, instruction following, detail preserving, and generation quality. For each perspective, we collected quantitative score in $0\sim 5$ and text descriptive feedback on the specific failure points in ground-truth edited images, resulting in a high-quality editing reward dataset, i.e., RewardEdit20K. 2) We further proposed a novel training framework to seamlessly integrate the metric output, regarded as multi-reward, into editing models to learn from the imperfect training triplets. During training, the reward scores and text descriptions are encoded as embeddings and fed into both the latent space and the U-Net of the editing models as auxiliary conditions. During inference, we set these additional conditions to the highest score with no text description for failure points, to aim at the best generation outcome. Experiments indicate that our multi-reward conditioned model outperforms its no-reward counterpart on two popular editing pipelines, i.e., InsPix2Pix and SmartEdit. The code and dataset will be released.
Beyond Raw Videos: Understanding Edited Videos with Large Multimodal Model
Jun 15, 2024



The emerging video LMMs (Large Multimodal Models) have achieved significant improvements on generic video understanding in the form of VQA (Visual Question Answering), where the raw videos are captured by cameras. However, a large portion of videos in real-world applications are edited videos, \textit{e.g.}, users usually cut and add effects/modifications to the raw video before publishing it on social media platforms. The edited videos usually have high view counts but they are not covered in existing benchmarks of video LMMs, \textit{i.e.}, ActivityNet-QA, or VideoChatGPT benchmark. In this paper, we leverage the edited videos on a popular short video platform, \textit{i.e.}, TikTok, and build a video VQA benchmark (named EditVid-QA) covering four typical editing categories, i.e., effect, funny, meme, and game. Funny and meme videos benchmark nuanced understanding and high-level reasoning, while effect and game evaluate the understanding capability of artificial design. Most of the open-source video LMMs perform poorly on the EditVid-QA benchmark, indicating a huge domain gap between edited short videos on social media and regular raw videos. To improve the generalization ability of LMMs, we collect a training set for the proposed benchmark based on both Panda-70M/WebVid raw videos and small-scale TikTok/CapCut edited videos, which boosts the performance on the proposed EditVid-QA benchmark, indicating the effectiveness of high-quality training data. We also identified a serious issue in the existing evaluation protocol using the GPT-3.5 judge, namely a "sorry" attack, where a sorry-style naive answer can achieve an extremely high rating from the GPT judge, e.g., over 4.3 for correctness score on VideoChatGPT evaluation protocol. To avoid the "sorry" attacks, we evaluate results with GPT-4 judge and keyword filtering. The datasets will be released for academic purposes only.
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
May 09, 2024
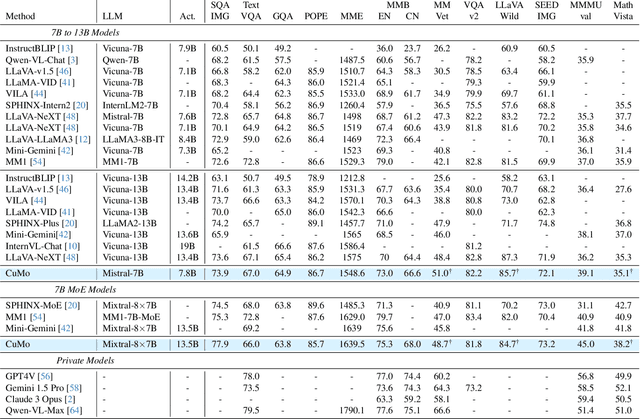
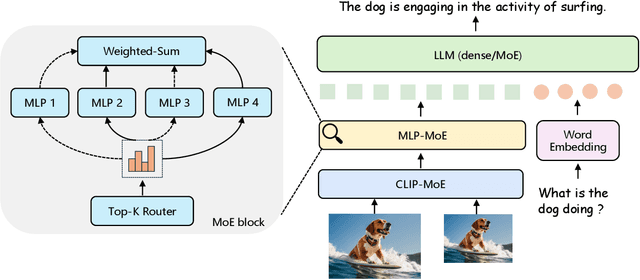
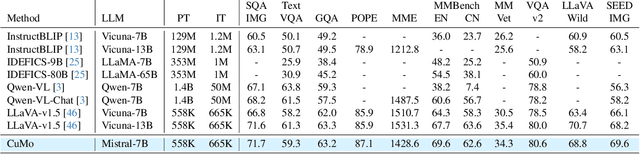
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
Edit3K: Universal Representation Learning for Video Editing Components
Mar 24, 2024This paper focuses on understanding the predominant video creation pipeline, i.e., compositional video editing with six main types of editing components, including video effects, animation, transition, filter, sticker, and text. In contrast to existing visual representation learning of visual materials (i.e., images/videos), we aim to learn visual representations of editing actions/components that are generally applied on raw materials. We start by proposing the first large-scale dataset for editing components of video creation, which covers about $3,094$ editing components with $618,800$ videos. Each video in our dataset is rendered by various image/video materials with a single editing component, which supports atomic visual understanding of different editing components. It can also benefit several downstream tasks, e.g., editing component recommendation, editing component recognition/retrieval, etc. Existing visual representation methods perform poorly because it is difficult to disentangle the visual appearance of editing components from raw materials. To that end, we benchmark popular alternative solutions and propose a novel method that learns to attend to the appearance of editing components regardless of raw materials. Our method achieves favorable results on editing component retrieval/recognition compared to the alternative solutions. A user study is also conducted to show that our representations cluster visually similar editing components better than other alternatives. Furthermore, our learned representations used to transition recommendation tasks achieve state-of-the-art results on the AutoTransition dataset. The code and dataset will be released for academic use.
$R^{2}$Former: Unified $R$etrieval and $R$eranking Transformer for Place Recognition
Apr 06, 2023



Visual Place Recognition (VPR) estimates the location of query images by matching them with images in a reference database. Conventional methods generally adopt aggregated CNN features for global retrieval and RANSAC-based geometric verification for reranking. However, RANSAC only employs geometric information but ignores other possible information that could be useful for reranking, e.g. local feature correlations, and attention values. In this paper, we propose a unified place recognition framework that handles both retrieval and reranking with a novel transformer model, named $R^{2}$Former. The proposed reranking module takes feature correlation, attention value, and xy coordinates into account, and learns to determine whether the image pair is from the same location. The whole pipeline is end-to-end trainable and the reranking module alone can also be adopted on other CNN or transformer backbones as a generic component. Remarkably, $R^{2}$Former significantly outperforms state-of-the-art methods on major VPR datasets with much less inference time and memory consumption. It also achieves the state-of-the-art on the hold-out MSLS challenge set and could serve as a simple yet strong solution for real-world large-scale applications. Experiments also show vision transformer tokens are comparable and sometimes better than CNN local features on local matching. The code is released at https://github.com/Jeff-Zilence/R2Former.
TopNet: Transformer-based Object Placement Network for Image Compositing
Apr 06, 2023



We investigate the problem of automatically placing an object into a background image for image compositing. Given a background image and a segmented object, the goal is to train a model to predict plausible placements (location and scale) of the object for compositing. The quality of the composite image highly depends on the predicted location/scale. Existing works either generate candidate bounding boxes or apply sliding-window search using global representations from background and object images, which fail to model local information in background images. However, local clues in background images are important to determine the compatibility of placing the objects with certain locations/scales. In this paper, we propose to learn the correlation between object features and all local background features with a transformer module so that detailed information can be provided on all possible location/scale configurations. A sparse contrastive loss is further proposed to train our model with sparse supervision. Our new formulation generates a 3D heatmap indicating the plausibility of all location/scale combinations in one network forward pass, which is over 10 times faster than the previous sliding-window method. It also supports interactive search when users provide a pre-defined location or scale. The proposed method can be trained with explicit annotation or in a self-supervised manner using an off-the-shelf inpainting model, and it outperforms state-of-the-art methods significantly. The user study shows that the trained model generalizes well to real-world images with diverse challenging scenes and object categories.