 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Concept Subspace for Self-explainable Text-Attributed Graph Learning
Apr 13, 2026We introduce Graph Concept Bottleneck (GCB) as a new paradigm for self-explainable text-attributed graph learning. GCB maps graphs into a subspace, concept bottleneck, where each concept is a meaningful phrase, and predictions are made based on the activation of these concepts. Unlike existing interpretable graph learning methods that primarily rely on subgraphs as explanations, the concept bottleneck provides a new form of interpretation. To refine the concept space, we apply the information bottleneck principle to focus on the most relevant concepts. This not only yields more concise and faithful explanations but also explicitly guides the model to "think" toward the correct decision. We empirically show that GCB achieves intrinsic interpretability with accuracy on par with black-box Graph Neural Networks. Moreover, it delivers better performance under distribution shifts and data perturbations, showing improved robustness and generalizability, benefitting from concept-guided prediction.
Towards Long-Form Spatio-Temporal Video Grounding
Feb 26, 2026In real scenarios, videos can span several minutes or even hours. However, existing research on spatio-temporal video grounding (STVG), given a textual query, mainly focuses on localizing targets in short videos of tens of seconds, typically less than one minute, which limits real-world applications. In this paper, we explore Long-Form STVG (LF-STVG), which aims to locate targets in long-term videos. Compared with short videos, long-term videos contain much longer temporal spans and more irrelevant information, making it difficult for existing STVG methods that process all frames at once. To address this challenge, we propose an AutoRegressive Transformer architecture for LF-STVG, termed ART-STVG. Unlike conventional STVG methods that require the entire video sequence to make predictions at once, ART-STVG treats the video as streaming input and processes frames sequentially, enabling efficient handling of long videos. To model spatio-temporal context, we design spatial and temporal memory banks and apply them to the decoders. Since memories from different moments are not always relevant to the current frame, we introduce simple yet effective memory selection strategies to provide more relevant information to the decoders, significantly improving performance. Furthermore, instead of parallel spatial and temporal localization, we propose a cascaded spatio-temporal design that connects the spatial decoder to the temporal decoder, allowing fine-grained spatial cues to assist complex temporal localization in long videos. Experiments on newly extended LF-STVG datasets show that ART-STVG significantly outperforms state-of-the-art methods, while achieving competitive performance on conventional short-form STVG.
Sparrow: Text-Anchored Window Attention with Visual-Semantic Glimpsing for Speculative Decoding in Video LLMs
Feb 17, 2026Although speculative decoding is widely used to accelerate Vision-Language Models (VLMs) inference, it faces severe performance collapse when applied to Video Large Language Models (Vid-LLMs). The draft model typically falls into the trap of attention dilution and negative visual gain due to key-value cache explosion and context window mismatches. We observe a visual semantic internalization phenomenon in Vid-LLMs, indicating that critical visual semantics are implicitly encoded into text hidden states during deep-layer interactions, which renders raw visual inputs structurally redundant during deep inference. To address this, we propose the Sparrow framework, which first utilizes visually-aware text-anchored window attention via hidden state reuse to fully offload visual computation to the target model, and leverages intermediate-layer visual state bridging to train the draft model with semantic-rich intermediate states, thereby filtering out low-level visual noise. Additionally, a multi-token prediction strategy is introduced to bridge the training-inference distribution shift. Experiments show that Sparrow achieves an average speedup of 2.82x even with 25k visual tokens, effectively resolving the performance degradation in long sequences and offering a practical solution for real-time long video tasks.
VisRefiner: Learning from Visual Differences for Screenshot-to-Code Generation
Feb 05, 2026Screenshot-to-code generation aims to translate user interface screenshots into executable frontend code that faithfully reproduces the target layout and style. Existing multimodal large language models perform this mapping directly from screenshots but are trained without observing the visual outcomes of their generated code. In contrast, human developers iteratively render their implementation, compare it with the design, and learn how visual differences relate to code changes. Inspired by this process, we propose VisRefiner, a training framework that enables models to learn from visual differences between rendered predictions and reference designs. We construct difference-aligned supervision that associates visual discrepancies with corresponding code edits, allowing the model to understand how appearance variations arise from implementation changes. Building on this, we introduce a reinforcement learning stage for self-refinement, where the model improves its generated code by observing both the rendered output and the target design, identifying their visual differences, and updating the code accordingly. Experiments show that VisRefiner substantially improves single-step generation quality and layout fidelity, while also endowing models with strong self-refinement ability. These results demonstrate the effectiveness of learning from visual differences for advancing screenshot-to-code generation.
EgoReAct: Egocentric Video-Driven 3D Human Reaction Generation
Dec 28, 2025Humans exhibit adaptive, context-sensitive responses to egocentric visual input. However, faithfully modeling such reactions from egocentric video remains challenging due to the dual requirements of strictly causal generation and precise 3D spatial alignment. To tackle this problem, we first construct the Human Reaction Dataset (HRD) to address data scarcity and misalignment by building a spatially aligned egocentric video-reaction dataset, as existing datasets (e.g., ViMo) suffer from significant spatial inconsistency between the egocentric video and reaction motion, e.g., dynamically moving motions are always paired with fixed-camera videos. Leveraging HRD, we present EgoReAct, the first autoregressive framework that generates 3D-aligned human reaction motions from egocentric video streams in real-time. We first compress the reaction motion into a compact yet expressive latent space via a Vector Quantised-Variational AutoEncoder and then train a Generative Pre-trained Transformer for reaction generation from the visual input. EgoReAct incorporates 3D dynamic features, i.e., metric depth, and head dynamics during the generation, which effectively enhance spatial grounding. Extensive experiments demonstrate that EgoReAct achieves remarkably higher realism, spatial consistency, and generation efficiency compared with prior methods, while maintaining strict causality during generation. We will release code, models, and data upon acceptance.
Nightjar: Dynamic Adaptive Speculative Decoding for Large Language Models Serving
Dec 27, 2025Speculative decoding (SD) accelerates LLM inference by verifying draft tokens in parallel. However, this method presents a critical trade-off: it improves throughput in low-load, memory-bound systems but degrades performance in high-load, compute-bound environments due to verification overhead. Current SD implementations use a fixed speculative length, failing to adapt to dynamic request rates and creating a significant performance bottleneck in real-world serving scenarios. To overcome this, we propose Nightjar, a novel learning-based algorithm for adaptive speculative inference that adjusts to request load by dynamically selecting the optimal speculative length for different batch sizes and even disabling speculative decoding when it provides no benefit. Experiments show that Nightjar achieves up to 14.8% higher throughput and 20.2% lower latency compared to standard speculative decoding, demonstrating robust efficiency for real-time serving.
G3CN: Gaussian Topology Refinement Gated Graph Convolutional Network for Skeleton-Based Action Recognition
Sep 09, 2025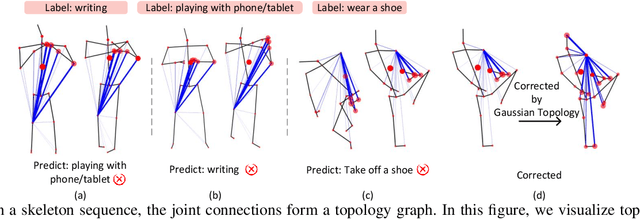
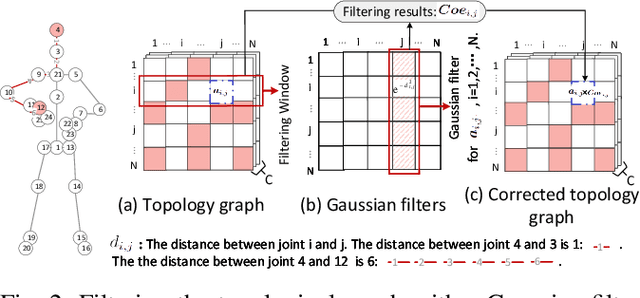
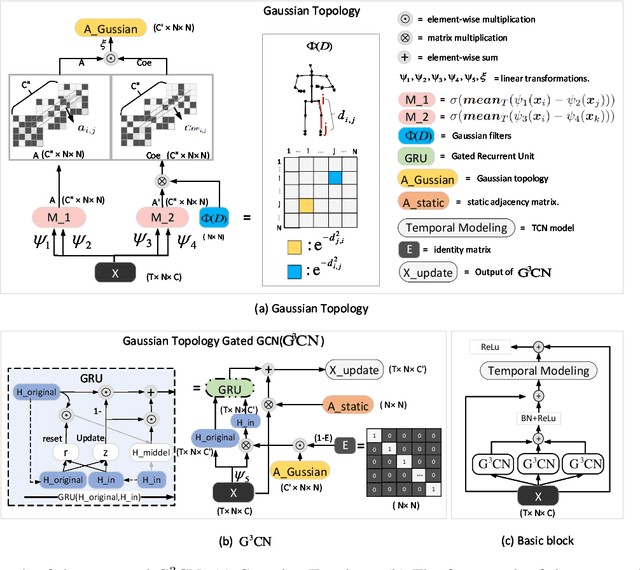
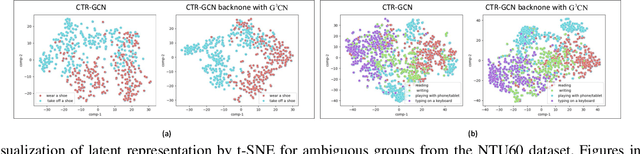
Graph Convolutional Networks (GCNs) have proven to be highly effective for skeleton-based action recognition, primarily due to their ability to leverage graph topology for feature aggregation, a key factor in extracting meaningful representations. However, despite their success, GCNs often struggle to effectively distinguish between ambiguous actions, revealing limitations in the representation of learned topological and spatial features. To address this challenge, we propose a novel approach, Gaussian Topology Refinement Gated Graph Convolution (G$^{3}$CN), to address the challenge of distinguishing ambiguous actions in skeleton-based action recognition. G$^{3}$CN incorporates a Gaussian filter to refine the skeleton topology graph, improving the representation of ambiguous actions. Additionally, Gated Recurrent Units (GRUs) are integrated into the GCN framework to enhance information propagation between skeleton points. Our method shows strong generalization across various GCN backbones. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA benchmarks demonstrate that G$^{3}$CN effectively improves action recognition, particularly for ambiguous samples.
Meta-Inverse Reinforcement Learning for Mean Field Games via Probabilistic Context Variables
Sep 04, 2025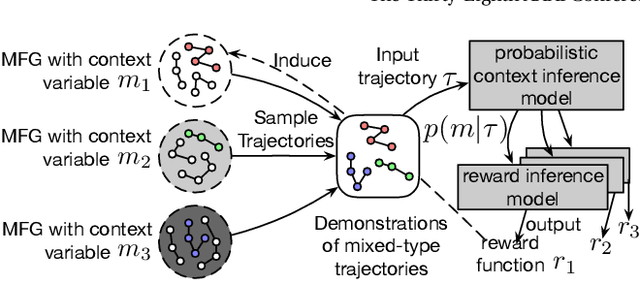


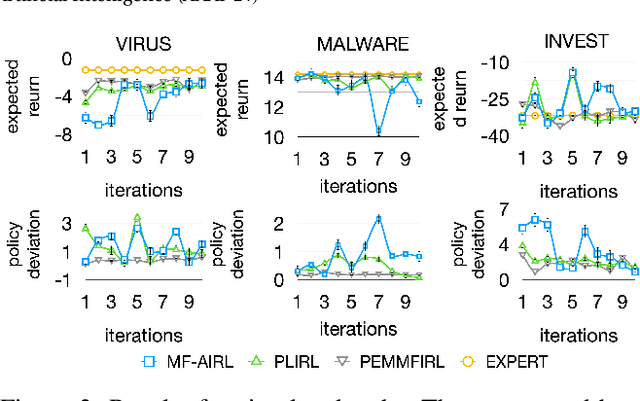
Designing suitable reward functions for numerous interacting intelligent agents is challenging in real-world applications. Inverse reinforcement learning (IRL) in mean field games (MFGs) offers a practical framework to infer reward functions from expert demonstrations. While promising, the assumption of agent homogeneity limits the capability of existing methods to handle demonstrations with heterogeneous and unknown objectives, which are common in practice. To this end, we propose a deep latent variable MFG model and an associated IRL method. Critically, our method can infer rewards from different yet structurally similar tasks without prior knowledge about underlying contexts or modifying the MFG model itself. Our experiments, conducted on simulated scenarios and a real-world spatial taxi-ride pricing problem, demonstrate the superiority of our approach over state-of-the-art IRL methods in MFGs.
OS-R1: Agentic Operating System Kernel Tuning with Reinforcement Learning
Aug 18, 2025Linux kernel tuning is essential for optimizing operating system (OS) performance. However, existing methods often face challenges in terms of efficiency, scalability, and generalization. This paper introduces OS-R1, an agentic Linux kernel tuning framework powered by rule-based reinforcement learning (RL). By abstracting the kernel configuration space as an RL environment, OS-R1 facilitates efficient exploration by large language models (LLMs) and ensures accurate configuration modifications. Additionally, custom reward functions are designed to enhance reasoning standardization, configuration modification accuracy, and system performance awareness of the LLMs. Furthermore, we propose a two-phase training process that accelerates convergence and minimizes retraining across diverse tuning scenarios. Experimental results show that OS-R1 significantly outperforms existing baseline methods, achieving up to 5.6% performance improvement over heuristic tuning and maintaining high data efficiency. Notably, OS-R1 is adaptable across various real-world applications, demonstrating its potential for practical deployment in diverse environments. Our dataset and code are publicly available at https://github.com/LHY-24/OS-R1.
Situational-Constrained Sequential Resources Allocation via Reinforcement Learning
Jun 17, 2025



Sequential Resource Allocation with situational constraints presents a significant challenge in real-world applications, where resource demands and priorities are context-dependent. This paper introduces a novel framework, SCRL, to address this problem. We formalize situational constraints as logic implications and develop a new algorithm that dynamically penalizes constraint violations. To handle situational constraints effectively, we propose a probabilistic selection mechanism to overcome limitations of traditional constraint reinforcement learning (CRL) approaches. We evaluate SCRL across two scenarios: medical resource allocation during a pandemic and pesticide distribution in agriculture. Experiments demonstrate that SCRL outperforms existing baselines in satisfying constraints while maintaining high resource efficiency, showcasing its potential for real-world, context-sensitive decision-making tasks.