 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Debater: Retrieval-Augmented Debate Generation through Argumentative Memory
Dec 31, 2025We present R-Debater, an agentic framework for generating multi-turn debates built on argumentative memory. Grounded in rhetoric and memory studies, the system views debate as a process of recalling and adapting prior arguments to maintain stance consistency, respond to opponents, and support claims with evidence. Specifically, R-Debater integrates a debate knowledge base for retrieving case-like evidence and prior debate moves with a role-based agent that composes coherent utterances across turns. We evaluate on standardized ORCHID debates, constructing a 1,000-item retrieval corpus and a held-out set of 32 debates across seven domains. Two tasks are evaluated: next-utterance generation, assessed by InspireScore (subjective, logical, and factual), and adversarial multi-turn simulations, judged by Debatrix (argument, source, language, and overall). Compared with strong LLM baselines, R-Debater achieves higher single-turn and multi-turn scores. Human evaluation with 20 experienced debaters further confirms its consistency and evidence use, showing that combining retrieval grounding with structured planning yields more faithful, stance-aligned, and coherent debates across turns.
FinMR: A Knowledge-Intensive Multimodal Benchmark for Advanced Financial Reasoning
Oct 09, 2025Multimodal Large Language Models (MLLMs) have made substantial progress in recent years. However, their rigorous evaluation within specialized domains like finance is hindered by the absence of datasets characterized by professional-level knowledge intensity, detailed annotations, and advanced reasoning complexity. To address this critical gap, we introduce FinMR, a high-quality, knowledge-intensive multimodal dataset explicitly designed to evaluate expert-level financial reasoning capabilities at a professional analyst's standard. FinMR comprises over 3,200 meticulously curated and expertly annotated question-answer pairs across 15 diverse financial topics, ensuring broad domain diversity and integrating sophisticated mathematical reasoning, advanced financial knowledge, and nuanced visual interpretation tasks across multiple image types. Through comprehensive benchmarking with leading closed-source and open-source MLLMs, we highlight significant performance disparities between these models and professional financial analysts, uncovering key areas for model advancement, such as precise image analysis, accurate application of complex financial formulas, and deeper contextual financial understanding. By providing richly varied visual content and thorough explanatory annotations, FinMR establishes itself as an essential benchmark tool for assessing and advancing multimodal financial reasoning toward professional analyst-level competence.
Meta-Inverse Reinforcement Learning for Mean Field Games via Probabilistic Context Variables
Sep 04, 2025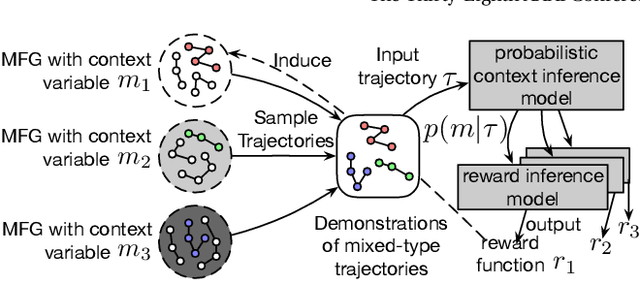


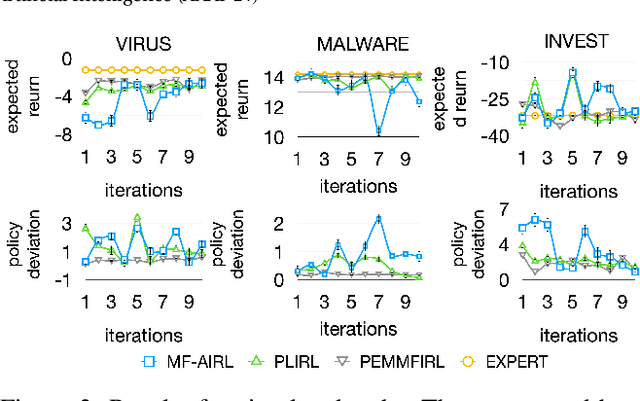
Designing suitable reward functions for numerous interacting intelligent agents is challenging in real-world applications. Inverse reinforcement learning (IRL) in mean field games (MFGs) offers a practical framework to infer reward functions from expert demonstrations. While promising, the assumption of agent homogeneity limits the capability of existing methods to handle demonstrations with heterogeneous and unknown objectives, which are common in practice. To this end, we propose a deep latent variable MFG model and an associated IRL method. Critically, our method can infer rewards from different yet structurally similar tasks without prior knowledge about underlying contexts or modifying the MFG model itself. Our experiments, conducted on simulated scenarios and a real-world spatial taxi-ride pricing problem, demonstrate the superiority of our approach over state-of-the-art IRL methods in MFGs.
Situational-Constrained Sequential Resources Allocation via Reinforcement Learning
Jun 17, 2025



Sequential Resource Allocation with situational constraints presents a significant challenge in real-world applications, where resource demands and priorities are context-dependent. This paper introduces a novel framework, SCRL, to address this problem. We formalize situational constraints as logic implications and develop a new algorithm that dynamically penalizes constraint violations. To handle situational constraints effectively, we propose a probabilistic selection mechanism to overcome limitations of traditional constraint reinforcement learning (CRL) approaches. We evaluate SCRL across two scenarios: medical resource allocation during a pandemic and pesticide distribution in agriculture. Experiments demonstrate that SCRL outperforms existing baselines in satisfying constraints while maintaining high resource efficiency, showcasing its potential for real-world, context-sensitive decision-making tasks.
Data Pricing for Graph Neural Networks without Pre-purchased Inspection
Feb 12, 2025



Machine learning (ML) models have become essential tools in various scenarios. Their effectiveness, however, hinges on a substantial volume of data for satisfactory performance. Model marketplaces have thus emerged as crucial platforms bridging model consumers seeking ML solutions and data owners possessing valuable data. These marketplaces leverage model trading mechanisms to properly incentive data owners to contribute their data, and return a well performing ML model to the model consumers. However, existing model trading mechanisms often assume the data owners are willing to share their data before being paid, which is not reasonable in real world. Given that, we propose a novel mechanism, named Structural Importance based Model Trading (SIMT) mechanism, that assesses the data importance and compensates data owners accordingly without disclosing the data. Specifically, SIMT procures feature and label data from data owners according to their structural importance, and then trains a graph neural network for model consumers. Theoretically, SIMT ensures incentive compatible, individual rational and budget feasible. The experiments on five popular datasets validate that SIMT consistently outperforms vanilla baselines by up to $40\%$ in both MacroF1 and MicroF1.
CoRA: Optimizing Low-Rank Adaptation with Common Subspace of Large Language Models
Aug 31, 2024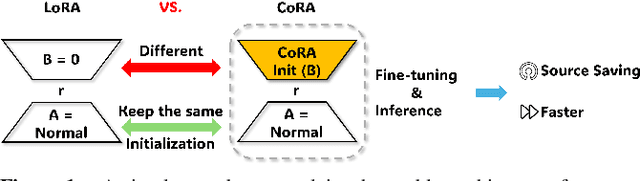
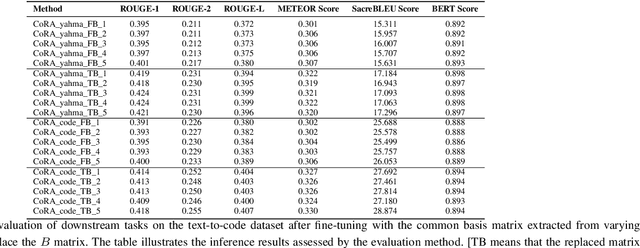
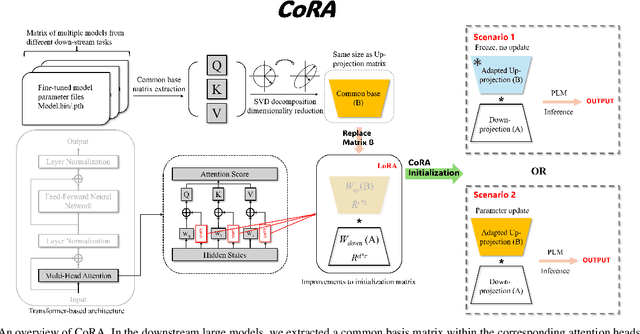
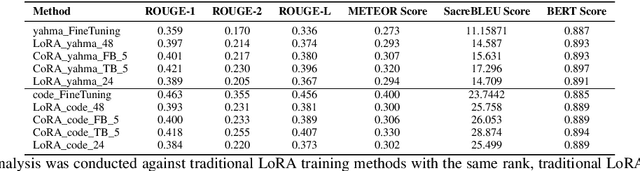
In fine-tuning large language models (LLMs), conserving computational resources while maintaining effectiveness and improving outcomes within the same computational constraints is crucial. The Low-Rank Adaptation (LoRA) strategy balances efficiency and performance in fine-tuning large models by reducing the number of trainable parameters and computational costs. However, current advancements in LoRA might be focused on its fine-tuning methodologies, with not as much exploration as might be expected into further compression of LoRA. Since most of LoRA's parameters might still be superfluous, this may lead to unnecessary wastage of computational resources. In this paper, we propose \textbf{CoRA}: leveraging shared knowledge to optimize LoRA training by substituting its matrix $B$ with a common subspace from large models. Our two-fold method includes (1) Freezing the substitute matrix $B$ to halve parameters while training matrix $A$ for specific tasks and (2) Using the substitute matrix $B$ as an enhanced initial state for the original matrix $B$, achieving improved results with the same parameters. Our experiments show that the first approach achieves the same efficacy as the original LoRA fine-tuning while being more efficient than halving parameters. At the same time, the second approach has some improvements compared to LoRA's original fine-tuning performance. They generally attest to the effectiveness of our work.
ChatLogic: Integrating Logic Programming with Large Language Models for Multi-Step Reasoning
Jul 14, 2024

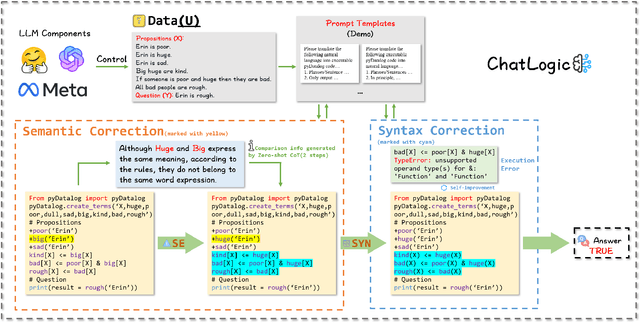
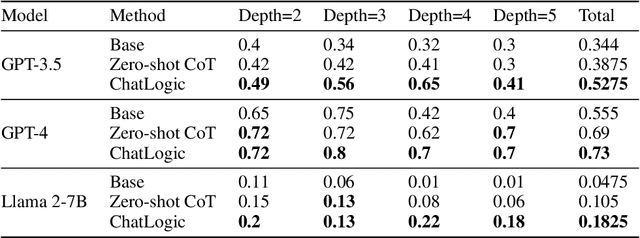
Large language models (LLMs) such as ChatGPT and GPT-4 have demonstrated impressive capabilities in various generative tasks. However, their performance is often hampered by limitations in accessing and leveraging long-term memory, leading to specific vulnerabilities and biases, especially during long interactions. This paper introduces ChatLogic, an innovative framework specifically targeted at LLM reasoning tasks that can enhance the performance of LLMs in multi-step deductive reasoning tasks by integrating logic programming. In ChatLogic, the language model plays a central role, acting as a controller and participating in every system operation stage. We propose a novel method of converting logic problems into symbolic integration with an inference engine. This approach leverages large language models' situational understanding and imitation skills and uses symbolic memory to enhance multi-step deductive reasoning capabilities. Our results show that the ChatLogic framework significantly improves the multi-step reasoning capabilities of LLMs. The source code and data are available at \url{https://github.com/Strong-AI-Lab/ChatLogic}
No Vandalism: Privacy-Preserving and Byzantine-Robust Federated Learning
Jun 03, 2024



Federated learning allows several clients to train one machine learning model jointly without sharing private data, providing privacy protection. However, traditional federated learning is vulnerable to poisoning attacks, which can not only decrease the model performance, but also implant malicious backdoors. In addition, direct submission of local model parameters can also lead to the privacy leakage of the training dataset. In this paper, we aim to build a privacy-preserving and Byzantine-robust federated learning scheme to provide an environment with no vandalism (NoV) against attacks from malicious participants. Specifically, we construct a model filter for poisoned local models, protecting the global model from data and model poisoning attacks. This model filter combines zero-knowledge proofs to provide further privacy protection. Then, we adopt secret sharing to provide verifiable secure aggregation, removing malicious clients that disrupting the aggregation process. Our formal analysis proves that NoV can protect data privacy and weed out Byzantine attackers. Our experiments illustrate that NoV can effectively address data and model poisoning attacks, including PGD, and outperforms other related schemes.
Behaviour Modelling of Social Animals via Causal Structure Discovery and Graph Neural Networks
Dec 21, 2023

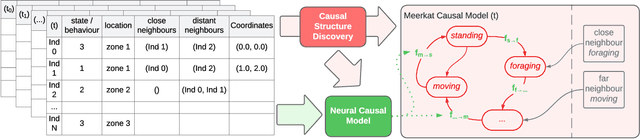
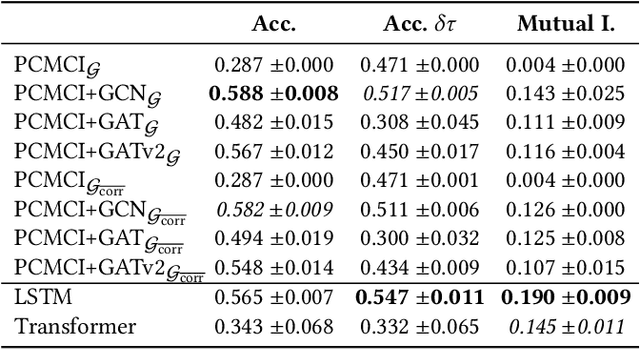
Better understanding the natural world is a crucial task with a wide range of applications. In environments with close proximity between humans and animals, such as zoos, it is essential to better understand the causes behind animal behaviour and what interventions are responsible for changes in their behaviours. This can help to predict unusual behaviours, mitigate detrimental effects and increase the well-being of animals. There has been work on modelling the dynamics behind swarms of birds and insects but the complex social behaviours of mammalian groups remain less explored. In this work, we propose a method to build behavioural models using causal structure discovery and graph neural networks for time series. We apply this method to a mob of meerkats in a zoo environment and study its ability to predict future actions and model the behaviour distribution at an individual-level and at a group level. We show that our method can match and outperform standard deep learning architectures and generate more realistic data, while using fewer parameters and providing increased interpretability.
S-T CRF: Spatial-Temporal Conditional Random Field for Human Trajectory Prediction
Nov 30, 2023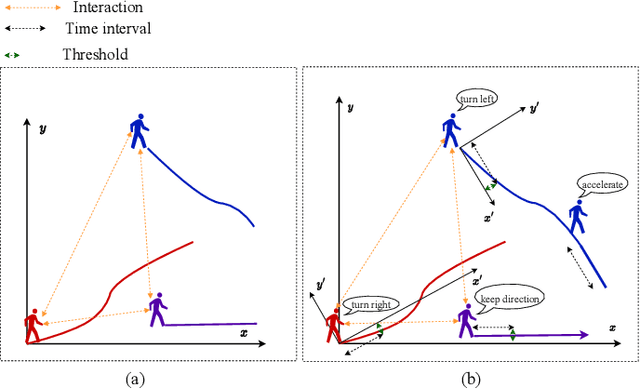
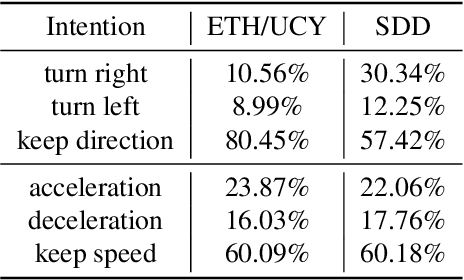
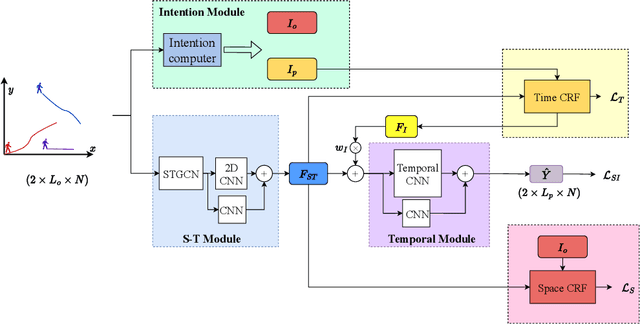
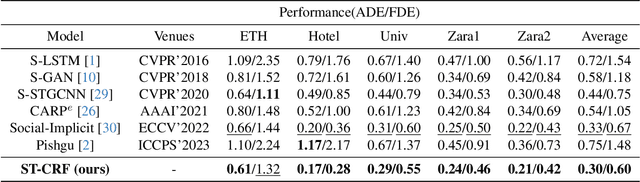
Trajectory prediction is of significant importance in computer vision. Accurate pedestrian trajectory prediction benefits autonomous vehicles and robots in planning their motion. Pedestrians' trajectories are greatly influenced by their intentions. Prior studies having introduced various deep learning methods only pay attention to the spatial and temporal information of trajectory, overlooking the explicit intention information. In this study, we introduce a novel model, termed the \textbf{S-T CRF}: \textbf{S}patial-\textbf{T}emporal \textbf{C}onditional \textbf{R}andom \textbf{F}ield, which judiciously incorporates intention information besides spatial and temporal information of trajectory. This model uses a Conditional Random Field (CRF) to generate a representation of future intentions, greatly improving the prediction of subsequent trajectories when combined with spatial-temporal representation. Furthermore, the study innovatively devises a space CRF loss and a time CRF loss, meticulously designed to enhance interaction constraints and temporal dynamics, respectively. Extensive experimental evaluations on dataset ETH/UCY and SDD demonstrate that the proposed method surpasses existing baseline approaches.