 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Learn Independent Causal Mechanisms?
Feb 04, 2024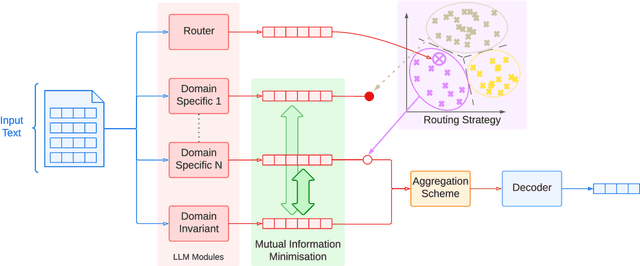
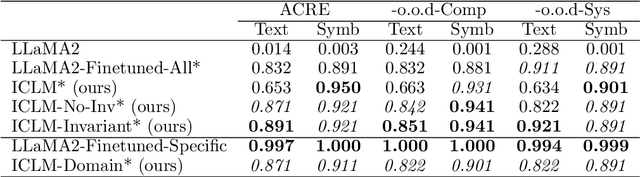
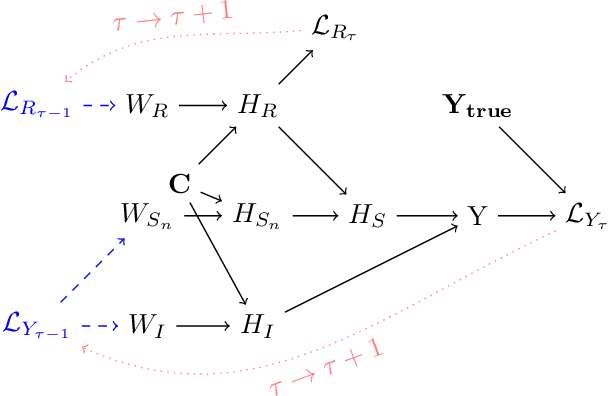
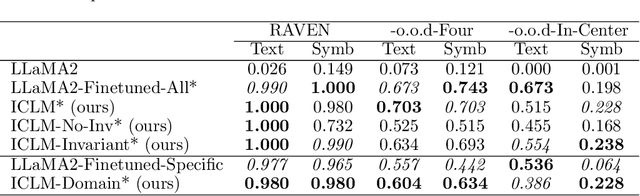
Despite impressive performance on language modelling and complex reasoning tasks, Large Language Models (LLMs) fall short on the same tasks in uncommon settings or with distribution shifts, exhibiting some lack of generalisation ability. This issue has usually been alleviated by feeding more training data into the LLM. However, this method is brittle, as the scope of tasks may not be readily predictable or may evolve, and updating the model with new data generally requires extensive additional training. By contrast, systems, such as causal models, that learn abstract variables and causal relationships can demonstrate increased robustness against changes in the distribution. One reason for this success is the existence and use of Independent Causal Mechanisms (ICMs) representing high-level concepts that only sparsely interact. In this work, we apply two concepts from causality to learn ICMs within LLMs. We develop a new LLM architecture composed of multiple sparsely interacting language modelling modules. We introduce a routing scheme to induce specialisation of the network into domain-specific modules. We also present a Mutual Information minimisation objective that trains a separate module to learn abstraction and domain-invariant mechanisms. We show that such causal constraints can improve out-of-distribution performance on abstract and causal reasoning tasks.
A Systematic Evaluation of Large Language Models on Out-of-Distribution Logical Reasoning Tasks
Oct 18, 2023

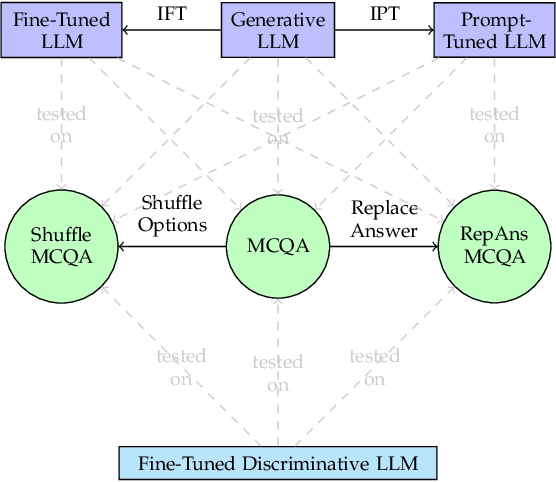

Large language models (LLMs), such as GPT-3.5 and GPT-4, have greatly advanced the performance of artificial systems on various natural language processing tasks to human-like levels. However, their generalisation and robustness to perform logical reasoning remain under-evaluated. To probe this ability, we propose three new logical reasoning datasets named "ReClor-plus", "LogiQA-plus" and "LogiQAv2-plus", each featuring three subsets: the first with randomly shuffled options, the second with the correct choices replaced by "none of the other options are correct", and a combination of the previous two subsets. We carry out experiments on these datasets with both discriminative and generative LLMs and show that these simple tricks greatly hinder the performance of the language models. Despite their superior performance on the original publicly available datasets, we find that all models struggle to answer our newly constructed datasets. We show that introducing task variations by perturbing a sizable training set can markedly improve the model's generalisation and robustness in logical reasoning tasks. Moreover, applying logic-driven data augmentation for fine-tuning, combined with prompting can enhance the generalisation performance of both discriminative large language models and generative large language models. These results offer insights into assessing and improving the generalisation and robustness of large language models for logical reasoning tasks. We make our source code and data publicly available \url{https://github.com/Strong-AI-Lab/Logical-and-abstract-reasoning}.
Exploring Self-Reinforcement for Improving Learnersourced Multiple-Choice Question Explanations with Large Language Models
Sep 19, 2023
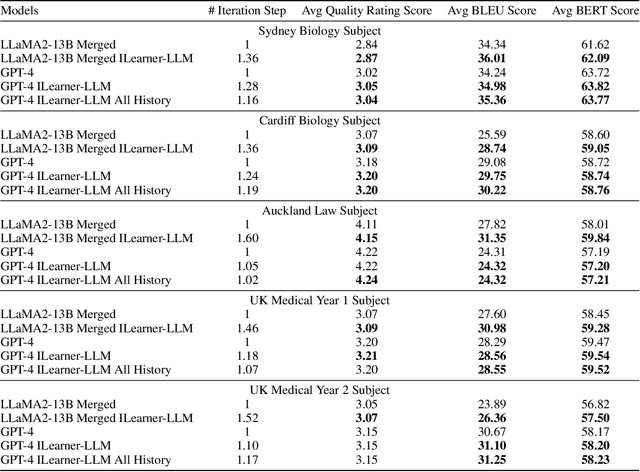
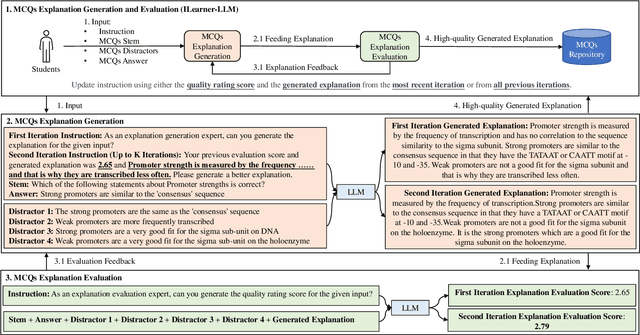
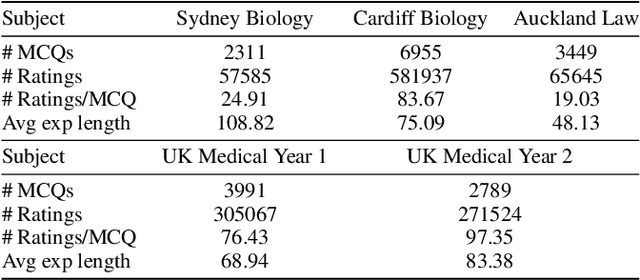
Learnersourcing involves students generating and sharing learning resources with their peers. When learnersourcing multiple-choice questions, creating explanations for the generated questions is a crucial step as it facilitates a deeper understanding of the related concepts. However, it is often difficult for students to craft effective explanations due to limited subject understanding and a tendency to merely restate the question stem, distractors, and correct answer. To help scaffold this task, in this work we propose a self-reinforcement large-language-model framework, with the goal of generating and evaluating explanations automatically. Comprising three modules, the framework generates student-aligned explanations, evaluates these explanations to ensure their quality and iteratively enhances the explanations. If an explanation's evaluation score falls below a defined threshold, the framework iteratively refines and reassesses the explanation. Importantly, our framework emulates the manner in which students compose explanations at the relevant grade level. For evaluation, we had a human subject-matter expert compare the explanations generated by students with the explanations created by the open-source large language model Vicuna-13B, a version of Vicuna-13B that had been fine-tuned using our method, and by GPT-4. We observed that, when compared to other large language models, GPT-4 exhibited a higher level of creativity in generating explanations. We also found that explanations generated by GPT-4 were ranked higher by the human expert than both those created by the other models and the original student-created explanations. Our findings represent a significant advancement in enriching the learnersourcing experience for students and enhancing the capabilities of large language models in educational applications.
Contrastive Learning with Logic-driven Data Augmentation for Logical Reasoning over Text
May 21, 2023Pre-trained large language model (LLM) is under exploration to perform NLP tasks that may require logical reasoning. Logic-driven data augmentation for representation learning has been shown to improve the performance of tasks requiring logical reasoning, but most of these data rely on designed templates and therefore lack generalization. In this regard, we propose an AMR-based logical equivalence-driven data augmentation method (AMR-LE) for generating logically equivalent data. Specifically, we first parse a text into the form of an AMR graph, next apply four logical equivalence laws (contraposition, double negation, commutative and implication laws) on the AMR graph to construct a logically equivalent/inequivalent AMR graph, and then convert it into a logically equivalent/inequivalent sentence. To help the model to better learn these logical equivalence laws, we propose a logical equivalence-driven contrastive learning training paradigm, which aims to distinguish the difference between logical equivalence and inequivalence. Our AMR-LE (Ensemble) achieves #2 on the ReClor leaderboard https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347 . Our model shows better performance on seven downstream tasks, including ReClor, LogiQA, MNLI, MRPC, RTE, QNLI, and QQP. The source code and dataset are public at https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning .
Input-length-shortening and text generation via attention values
Mar 14, 2023Identifying words that impact a task's performance more than others is a challenge in natural language processing. Transformers models have recently addressed this issue by incorporating an attention mechanism that assigns greater attention (i.e., relevance) scores to some words than others. Because of the attention mechanism's high computational cost, transformer models usually have an input-length limitation caused by hardware constraints. This limitation applies to many transformers, including the well-known bidirectional encoder representations of the transformer (BERT) model. In this paper, we examined BERT's attention assignment mechanism, focusing on two questions: (1) How can attention be employed to reduce input length? (2) How can attention be used as a control mechanism for conditional text generation? We investigated these questions in the context of a text classification task. We discovered that BERT's early layers assign more critical attention scores for text classification tasks compared to later layers. We demonstrated that the first layer's attention sums could be used to filter tokens in a given sequence, considerably decreasing the input length while maintaining good test accuracy. We also applied filtering, which uses a compute-efficient semantic similarities algorithm, and discovered that retaining approximately 6\% of the original sequence is sufficient to obtain 86.5\% accuracy. Finally, we showed that we could generate data in a stable manner and indistinguishable from the original one by only using a small percentage (10\%) of the tokens with high attention scores according to BERT's first layer.
Multi-Step Deductive Reasoning Over Natural Language: An Empirical Study on Out-of-Distribution Generalisation
Jul 28, 2022
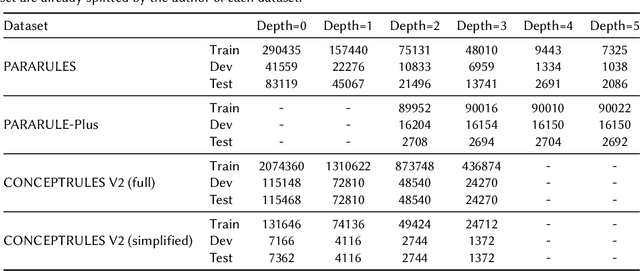
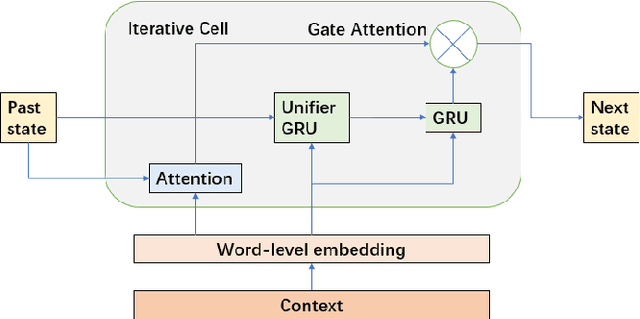
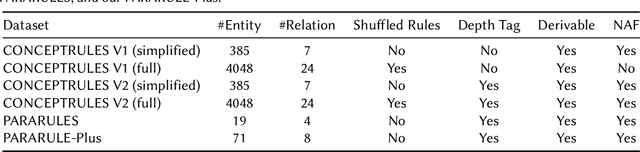
Combining deep learning with symbolic logic reasoning aims to capitalize on the success of both fields and is drawing increasing attention. Inspired by DeepLogic, an end-to-end model trained to perform inference on logic programs, we introduce IMA-GloVe-GA, an iterative neural inference network for multi-step reasoning expressed in natural language. In our model, reasoning is performed using an iterative memory neural network based on RNN with a gate attention mechanism. We evaluate IMA-GloVe-GA on three datasets: PARARULES, CONCEPTRULES V1 and CONCEPTRULES V2. Experimental results show DeepLogic with gate attention can achieve higher test accuracy than DeepLogic and other RNN baseline models. Our model achieves better out-of-distribution generalisation than RoBERTa-Large when the rules have been shuffled. Furthermore, to address the issue of unbalanced distribution of reasoning depths in the current multi-step reasoning datasets, we develop PARARULE-Plus, a large dataset with more examples that require deeper reasoning steps. Experimental results show that the addition of PARARULE-Plus can increase the model's performance on examples requiring deeper reasoning depths. The source code and data are available at https://github.com/Strong-AI-Lab/Multi-Step-Deductive-Reasoning-Over-Natural-Language.