 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers As Approximations of Solomonoff Induction
Aug 22, 2024Solomonoff Induction is an optimal-in-the-limit unbounded algorithm for sequence prediction, representing a Bayesian mixture of every computable probability distribution and performing close to optimally in predicting any computable sequence. Being an optimal form of computational sequence prediction, it seems plausible that it may be used as a model against which other methods of sequence prediction might be compared. We put forth and explore the hypothesis that Transformer models - the basis of Large Language Models - approximate Solomonoff Induction better than any other extant sequence prediction method. We explore evidence for and against this hypothesis, give alternate hypotheses that take this evidence into account, and outline next steps for modelling Transformers and other kinds of AI in this way.
Contrastive Learning with Logic-driven Data Augmentation for Logical Reasoning over Text
May 21, 2023Pre-trained large language model (LLM) is under exploration to perform NLP tasks that may require logical reasoning. Logic-driven data augmentation for representation learning has been shown to improve the performance of tasks requiring logical reasoning, but most of these data rely on designed templates and therefore lack generalization. In this regard, we propose an AMR-based logical equivalence-driven data augmentation method (AMR-LE) for generating logically equivalent data. Specifically, we first parse a text into the form of an AMR graph, next apply four logical equivalence laws (contraposition, double negation, commutative and implication laws) on the AMR graph to construct a logically equivalent/inequivalent AMR graph, and then convert it into a logically equivalent/inequivalent sentence. To help the model to better learn these logical equivalence laws, we propose a logical equivalence-driven contrastive learning training paradigm, which aims to distinguish the difference between logical equivalence and inequivalence. Our AMR-LE (Ensemble) achieves #2 on the ReClor leaderboard https://eval.ai/web/challenges/challenge-page/503/leaderboard/1347 . Our model shows better performance on seven downstream tasks, including ReClor, LogiQA, MNLI, MRPC, RTE, QNLI, and QQP. The source code and dataset are public at https://github.com/Strong-AI-Lab/Logical-Equivalence-driven-AMR-Data-Augmentation-for-Representation-Learning .
AbductionRules: Training Transformers to Explain Unexpected Inputs
Mar 23, 2022
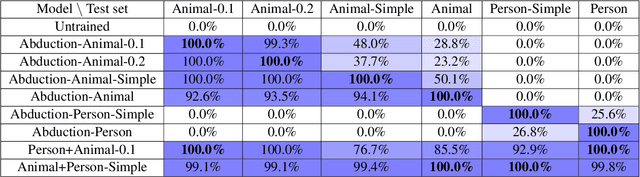
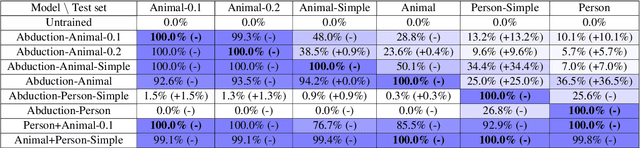
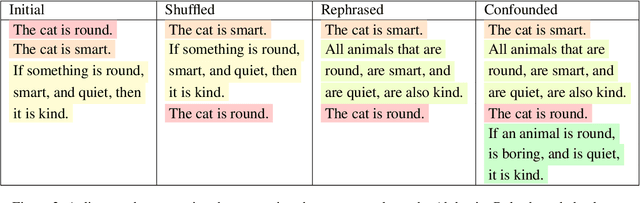
Transformers have recently been shown to be capable of reliably performing logical reasoning over facts and rules expressed in natural language, but abductive reasoning - inference to the best explanation of an unexpected observation - has been underexplored despite significant applications to scientific discovery, common-sense reasoning, and model interpretability. We present AbductionRules, a group of natural language datasets designed to train and test generalisable abduction over natural-language knowledge bases. We use these datasets to finetune pretrained Transformers and discuss their performance, finding that our models learned generalisable abductive techniques but also learned to exploit the structure of our data. Finally, we discuss the viability of this approach to abductive reasoning and ways in which it may be improved in future work.
Decentralized Control Systems Laboratory Using Human Centered Robotic Actuators
Apr 09, 2019



University laboratories deliver unique hands-on experimentation for STEM students but often lack state-of-the-art equipment and provide limited access to their equipment. The University of Texas Cloud Laboratory provides remote access to a cutting-edge series elastic actuators for student experimentation regarding human-centered robotics, dynamical systems, and controls. Through a browser-based interface, students are provided with various learning materials using the remote hardware-in-the-loop system for effective experiment-based education. This paper discusses the methods used to connect remote hardware to mobile browsers, the adaptation of textbook materials regarding system identification and feedback control, data processing to generate clean and useful results for student interpretation, and initial usage of the end-to-end system for individual and group learning.