 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Smaller Language Models Answer Contextualised Questions Through Memorisation Or Generalisation?
Nov 21, 2023

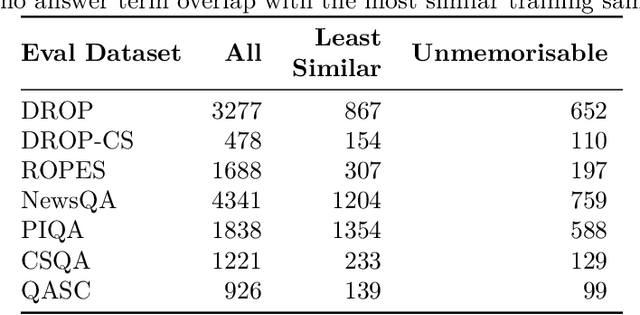

A distinction is often drawn between a model's ability to predict a label for an evaluation sample that is directly memorised from highly similar training samples versus an ability to predict the label via some method of generalisation. In the context of using Language Models for question-answering, discussion continues to occur as to the extent to which questions are answered through memorisation. We consider this issue for questions that would ideally be answered through reasoning over an associated context. We propose a method of identifying evaluation samples for which it is very unlikely our model would have memorised the answers. Our method is based on semantic similarity of input tokens and label tokens between training and evaluation samples. We show that our method offers advantages upon some prior approaches in that it is able to surface evaluation-train pairs that have overlap in either contiguous or discontiguous sequences of tokens. We use this method to identify unmemorisable subsets of our evaluation datasets. We train two Language Models in a multitask fashion whereby the second model differs from the first only in that it has two additional datasets added to the training regime that are designed to impart simple numerical reasoning strategies of a sort known to improve performance on some of our evaluation datasets but not on others. We then show that there is performance improvement between the two models on the unmemorisable subsets of the evaluation datasets that were expected to benefit from the additional training datasets. Specifically, performance on unmemorisable subsets of two of our evaluation datasets, DROP and ROPES significantly improves by 9.0%, and 25.7% respectively while other evaluation datasets have no significant change in performance.
Challenges in Annotating Datasets to Quantify Bias in Under-represented Society
Sep 11, 2023
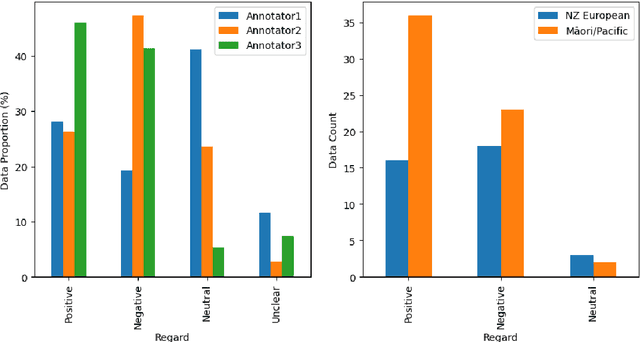


Recent advances in artificial intelligence, including the development of highly sophisticated large language models (LLM), have proven beneficial in many real-world applications. However, evidence of inherent bias encoded in these LLMs has raised concerns about equity. In response, there has been an increase in research dealing with bias, including studies focusing on quantifying bias and developing debiasing techniques. Benchmark bias datasets have also been developed for binary gender classification and ethical/racial considerations, focusing predominantly on American demographics. However, there is minimal research in understanding and quantifying bias related to under-represented societies. Motivated by the lack of annotated datasets for quantifying bias in under-represented societies, we endeavoured to create benchmark datasets for the New Zealand (NZ) population. We faced many challenges in this process, despite the availability of three annotators. This research outlines the manual annotation process, provides an overview of the challenges we encountered and lessons learnt, and presents recommendations for future research.
Neuromodulation Gated Transformer
May 11, 2023We introduce a novel architecture, the Neuromodulation Gated Transformer (NGT), which is a simple implementation of neuromodulation in transformers via a multiplicative effect. We compare it to baselines and show that it results in the best average performance on the SuperGLUE benchmark validation sets.
Input-length-shortening and text generation via attention values
Mar 14, 2023Identifying words that impact a task's performance more than others is a challenge in natural language processing. Transformers models have recently addressed this issue by incorporating an attention mechanism that assigns greater attention (i.e., relevance) scores to some words than others. Because of the attention mechanism's high computational cost, transformer models usually have an input-length limitation caused by hardware constraints. This limitation applies to many transformers, including the well-known bidirectional encoder representations of the transformer (BERT) model. In this paper, we examined BERT's attention assignment mechanism, focusing on two questions: (1) How can attention be employed to reduce input length? (2) How can attention be used as a control mechanism for conditional text generation? We investigated these questions in the context of a text classification task. We discovered that BERT's early layers assign more critical attention scores for text classification tasks compared to later layers. We demonstrated that the first layer's attention sums could be used to filter tokens in a given sequence, considerably decreasing the input length while maintaining good test accuracy. We also applied filtering, which uses a compute-efficient semantic similarities algorithm, and discovered that retaining approximately 6\% of the original sequence is sufficient to obtain 86.5\% accuracy. Finally, we showed that we could generate data in a stable manner and indistinguishable from the original one by only using a small percentage (10\%) of the tokens with high attention scores according to BERT's first layer.
AbductionRules: Training Transformers to Explain Unexpected Inputs
Mar 23, 2022
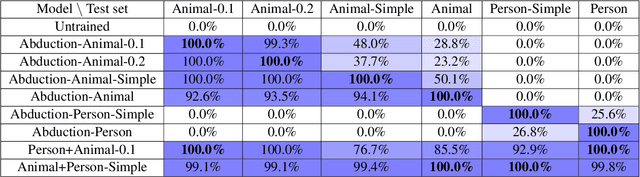
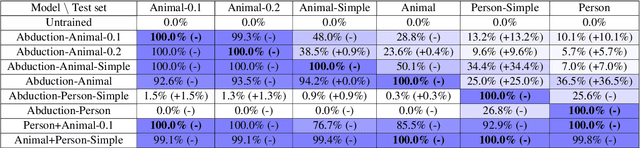
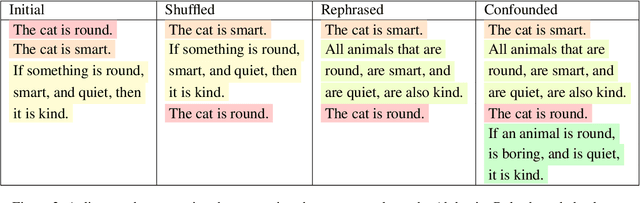
Transformers have recently been shown to be capable of reliably performing logical reasoning over facts and rules expressed in natural language, but abductive reasoning - inference to the best explanation of an unexpected observation - has been underexplored despite significant applications to scientific discovery, common-sense reasoning, and model interpretability. We present AbductionRules, a group of natural language datasets designed to train and test generalisable abduction over natural-language knowledge bases. We use these datasets to finetune pretrained Transformers and discuss their performance, finding that our models learned generalisable abductive techniques but also learned to exploit the structure of our data. Finally, we discuss the viability of this approach to abductive reasoning and ways in which it may be improved in future work.
Relating Blindsight and AI: A Review
Dec 09, 2021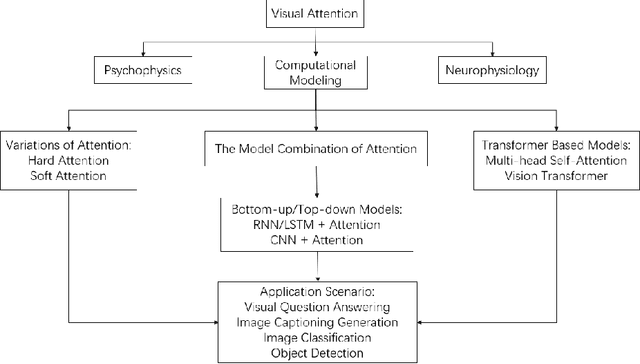
Processes occurring in brains, a.k.a. biological neural networks, can and have been modeled within artificial neural network architectures. Due to this, we have conducted a review of research on the phenomenon of blindsight in an attempt to generate ideas for artificial intelligence models. Blindsight can be considered as a diminished form of visual experience. If we assume that artificial networks have no form of visual experience, then deficits caused by blindsight give us insights into the processes occurring within visual experience that we can incorporate into artificial neural networks. This article has been structured into three parts. Section 2 is a review of blindsight research, looking specifically at the errors occurring during this condition compared to normal vision. Section 3 identifies overall patterns from Section 2 to generate insights for computational models of vision. Section 4 demonstrates the utility of examining biological research to inform artificial intelligence research by examining computation models of visual attention relevant to one of the insights generated in Section 3. The research covered in Section 4 shows that incorporating one of our insights into computational vision does benefit those models. Future research will be required to determine whether our other insights are as valuable.
* Preprint of an article published in Journal of Artificial Intelligence and Consciousness, 2021 doi.org/10.1142/S2705078521500156 \c{opyright} copyright World Scientific Publishing Company www.worldscientific.com/worldscinet/jaic