 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Annotating Datasets to Quantify Bias in Under-represented Society
Paper and Code
Sep 11, 2023
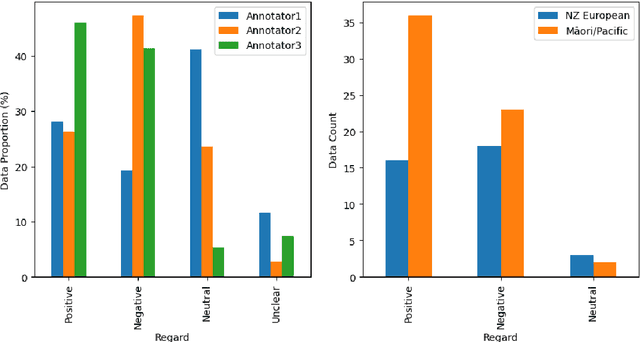


Recent advances in artificial intelligence, including the development of highly sophisticated large language models (LLM), have proven beneficial in many real-world applications. However, evidence of inherent bias encoded in these LLMs has raised concerns about equity. In response, there has been an increase in research dealing with bias, including studies focusing on quantifying bias and developing debiasing techniques. Benchmark bias datasets have also been developed for binary gender classification and ethical/racial considerations, focusing predominantly on American demographics. However, there is minimal research in understanding and quantifying bias related to under-represented societies. Motivated by the lack of annotated datasets for quantifying bias in under-represented societies, we endeavoured to create benchmark datasets for the New Zealand (NZ) population. We faced many challenges in this process, despite the availability of three annotators. This research outlines the manual annotation process, provides an overview of the challenges we encountered and lessons learnt, and presents recommendations for future research.