 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocrates Loss: Unifying Confidence Calibration and Classification by Leveraging the Unknown
Apr 14, 2026Deep neural networks, despite their high accuracy, often exhibit poor confidence calibration, limiting their reliability in high-stakes applications. Current ad-hoc confidence calibration methods attempt to fix this during training but face a fundamental trade-off: two-phase training methods achieve strong classification performance at the cost of training instability and poorer confidence calibration, while single-loss methods are stable but underperform in classification. This paper addresses and mitigates this stability-performance trade-off. We propose Socrates Loss, a novel, unified loss function that explicitly leverages uncertainty by incorporating an auxiliary unknown class, whose predictions directly influence the loss function and a dynamic uncertainty penalty. This unified objective allows the model to be optimized for both classification and confidence calibration simultaneously, without the instability of complex, scheduled losses. We provide theoretical guarantees that our method regularizes the model to prevent miscalibration and overfitting. Across four benchmark datasets and multiple architectures, our comprehensive experiments demonstrate that Socrates Loss consistently improves training stability while achieving more favorable accuracy-calibration trade-off, often converging faster than existing methods.
* Published at TMLR 2026. https://openreview.net/forum?id=DONqw1KhHq Video: https://youtu.be/7WuSkC-aWW8?si=9fgq5ZN7euIyGZGU Code: https://github.com/sandruskyi/SocratesLoss
HoRD: Robust Humanoid Control via History-Conditioned Reinforcement Learning and Online Distillation
Feb 05, 2026Humanoid robots can suffer significant performance drops under small changes in dynamics, task specifications, or environment setup. We propose HoRD, a two-stage learning framework for robust humanoid control under domain shift. First, we train a high-performance teacher policy via history-conditioned reinforcement learning, where the policy infers latent dynamics context from recent state--action trajectories to adapt online to diverse randomized dynamics. Second, we perform online distillation to transfer the teacher's robust control capabilities into a transformer-based student policy that operates on sparse root-relative 3D joint keypoint trajectories. By combining history-conditioned adaptation with online distillation, HoRD enables a single policy to adapt zero-shot to unseen domains without per-domain retraining. Extensive experiments show HoRD outperforms strong baselines in robustness and transfer, especially under unseen domains and external perturbations. Code and project page are available at https://tonywang-0517.github.io/hord/.
Causally-Grounded Dual-Path Attention Intervention for Object Hallucination Mitigation in LVLMs
Nov 12, 2025Object hallucination remains a critical challenge in Large Vision-Language Models (LVLMs), where models generate content inconsistent with visual inputs. Existing language-decoder based mitigation approaches often regulate visual or textual attention independently, overlooking their interaction as two key causal factors. To address this, we propose Owl (Bi-mOdal attention reWeighting for Layer-wise hallucination mitigation), a causally-grounded framework that models hallucination process via a structural causal graph, treating decomposed visual and textual attentions as mediators. We introduce VTACR (Visual-to-Textual Attention Contribution Ratio), a novel metric that quantifies the modality contribution imbalance during decoding. Our analysis reveals that hallucinations frequently occur in low-VTACR scenarios, where textual priors dominate and visual grounding is weakened. To mitigate this, we design a fine-grained attention intervention mechanism that dynamically adjusts token- and layer-wise attention guided by VTACR signals. Finally, we propose a dual-path contrastive decoding strategy: one path emphasizes visually grounded predictions, while the other amplifies hallucinated ones -- letting visual truth shine and hallucination collapse. Experimental results on the POPE and CHAIR benchmarks show that Owl achieves significant hallucination reduction, setting a new SOTA in faithfulness while preserving vision-language understanding capability. Our code is available at https://github.com/CikZ2023/OWL
Causal Cartographer: From Mapping to Reasoning Over Counterfactual Worlds
May 20, 2025Causal world models are systems that can answer counterfactual questions about an environment of interest, i.e. predict how it would have evolved if an arbitrary subset of events had been realized differently. It requires understanding the underlying causes behind chains of events and conducting causal inference for arbitrary unseen distributions. So far, this task eludes foundation models, notably large language models (LLMs), which do not have demonstrated causal reasoning capabilities beyond the memorization of existing causal relationships. Furthermore, evaluating counterfactuals in real-world applications is challenging since only the factual world is observed, limiting evaluation to synthetic datasets. We address these problems by explicitly extracting and modeling causal relationships and propose the Causal Cartographer framework. First, we introduce a graph retrieval-augmented generation agent tasked to retrieve causal relationships from data. This approach allows us to construct a large network of real-world causal relationships that can serve as a repository of causal knowledge and build real-world counterfactuals. In addition, we create a counterfactual reasoning agent constrained by causal relationships to perform reliable step-by-step causal inference. We show that our approach can extract causal knowledge and improve the robustness of LLMs for causal reasoning tasks while reducing inference costs and spurious correlations.
Robust Domain Generalisation with Causal Invariant Bayesian Neural Networks
Oct 08, 2024
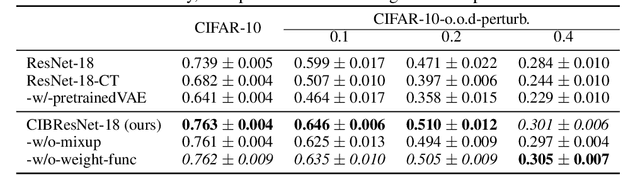
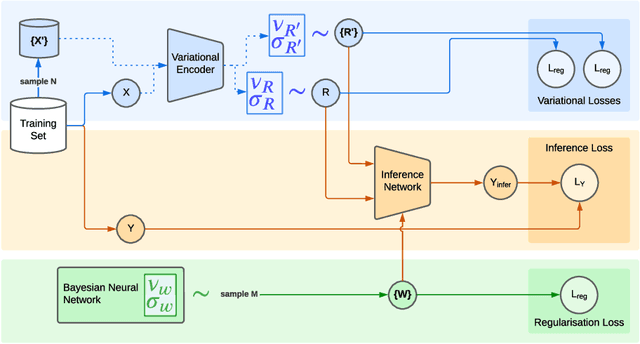

Deep neural networks can obtain impressive performance on various tasks under the assumption that their training domain is identical to their target domain. Performance can drop dramatically when this assumption does not hold. One explanation for this discrepancy is the presence of spurious domain-specific correlations in the training data that the network exploits. Causal mechanisms, in the other hand, can be made invariant under distribution changes as they allow disentangling the factors of distribution underlying the data generation. Yet, learning causal mechanisms to improve out-of-distribution generalisation remains an under-explored area. We propose a Bayesian neural architecture that disentangles the learning of the the data distribution from the inference process mechanisms. We show theoretically and experimentally that our model approximates reasoning under causal interventions. We demonstrate the performance of our method, outperforming point estimate-counterparts, on out-of-distribution image recognition tasks where the data distribution acts as strong adversarial confounders.
Counterfactual Causal Inference in Natural Language with Large Language Models
Oct 08, 2024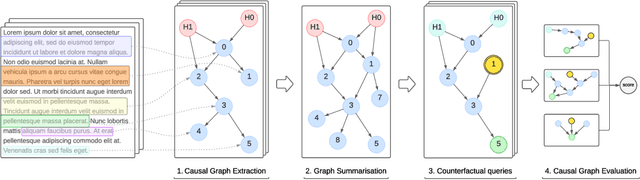

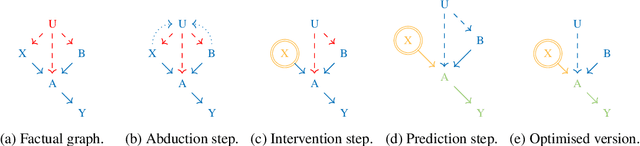
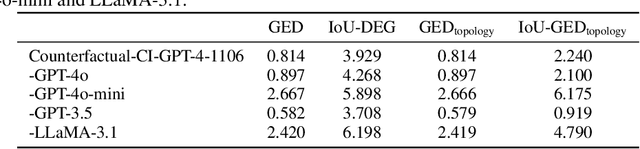
Causal structure discovery methods are commonly applied to structured data where the causal variables are known and where statistical testing can be used to assess the causal relationships. By contrast, recovering a causal structure from unstructured natural language data such as news articles contains numerous challenges due to the absence of known variables or counterfactual data to estimate the causal links. Large Language Models (LLMs) have shown promising results in this direction but also exhibit limitations. This work investigates LLM's abilities to build causal graphs from text documents and perform counterfactual causal inference. We propose an end-to-end causal structure discovery and causal inference method from natural language: we first use an LLM to extract the instantiated causal variables from text data and build a causal graph. We merge causal graphs from multiple data sources to represent the most exhaustive set of causes possible. We then conduct counterfactual inference on the estimated graph. The causal graph conditioning allows reduction of LLM biases and better represents the causal estimands. We use our method to show that the limitations of LLMs in counterfactual causal reasoning come from prediction errors and propose directions to mitigate them. We demonstrate the applicability of our method on real-world news articles.
Can Large Language Models Learn Independent Causal Mechanisms?
Feb 04, 2024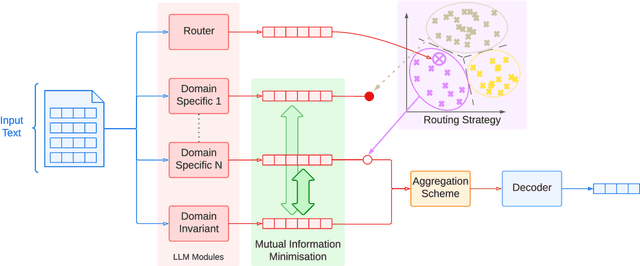
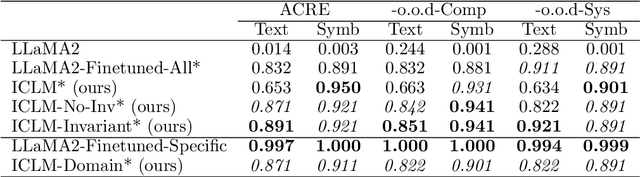
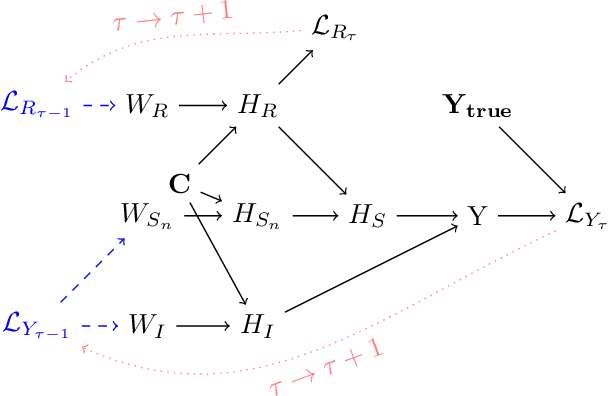
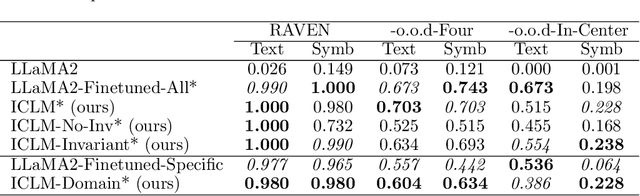
Despite impressive performance on language modelling and complex reasoning tasks, Large Language Models (LLMs) fall short on the same tasks in uncommon settings or with distribution shifts, exhibiting some lack of generalisation ability. This issue has usually been alleviated by feeding more training data into the LLM. However, this method is brittle, as the scope of tasks may not be readily predictable or may evolve, and updating the model with new data generally requires extensive additional training. By contrast, systems, such as causal models, that learn abstract variables and causal relationships can demonstrate increased robustness against changes in the distribution. One reason for this success is the existence and use of Independent Causal Mechanisms (ICMs) representing high-level concepts that only sparsely interact. In this work, we apply two concepts from causality to learn ICMs within LLMs. We develop a new LLM architecture composed of multiple sparsely interacting language modelling modules. We introduce a routing scheme to induce specialisation of the network into domain-specific modules. We also present a Mutual Information minimisation objective that trains a separate module to learn abstraction and domain-invariant mechanisms. We show that such causal constraints can improve out-of-distribution performance on abstract and causal reasoning tasks.
Behaviour Modelling of Social Animals via Causal Structure Discovery and Graph Neural Networks
Dec 21, 2023

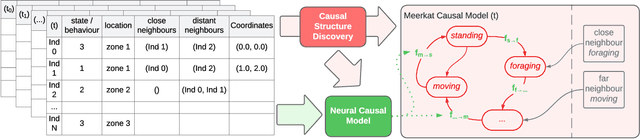
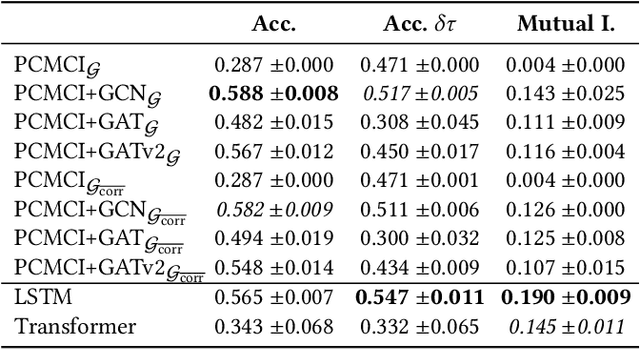
Better understanding the natural world is a crucial task with a wide range of applications. In environments with close proximity between humans and animals, such as zoos, it is essential to better understand the causes behind animal behaviour and what interventions are responsible for changes in their behaviours. This can help to predict unusual behaviours, mitigate detrimental effects and increase the well-being of animals. There has been work on modelling the dynamics behind swarms of birds and insects but the complex social behaviours of mammalian groups remain less explored. In this work, we propose a method to build behavioural models using causal structure discovery and graph neural networks for time series. We apply this method to a mob of meerkats in a zoo environment and study its ability to predict future actions and model the behaviour distribution at an individual-level and at a group level. We show that our method can match and outperform standard deep learning architectures and generate more realistic data, while using fewer parameters and providing increased interpretability.
Tackling Bias in Pre-trained Language Models: Current Trends and Under-represented Societies
Dec 03, 2023The benefits and capabilities of pre-trained language models (LLMs) in current and future innovations are vital to any society. However, introducing and using LLMs comes with biases and discrimination, resulting in concerns about equality, diversity and fairness, and must be addressed. While understanding and acknowledging bias in LLMs and developing mitigation strategies are crucial, the generalised assumptions towards societal needs can result in disadvantages towards under-represented societies and indigenous populations. Furthermore, the ongoing changes to actual and proposed amendments to regulations and laws worldwide also impact research capabilities in tackling the bias problem. This research presents a comprehensive survey synthesising the current trends and limitations in techniques used for identifying and mitigating bias in LLMs, where the overview of methods for tackling bias are grouped into metrics, benchmark datasets, and mitigation strategies. The importance and novelty of this survey are that it explores the perspective of under-represented societies. We argue that current practices tackling the bias problem cannot simply be 'plugged in' to address the needs of under-represented societies. We use examples from New Zealand to present requirements for adopting existing techniques to under-represented societies.
Poison is Not Traceless: Fully-Agnostic Detection of Poisoning Attacks
Oct 24, 2023
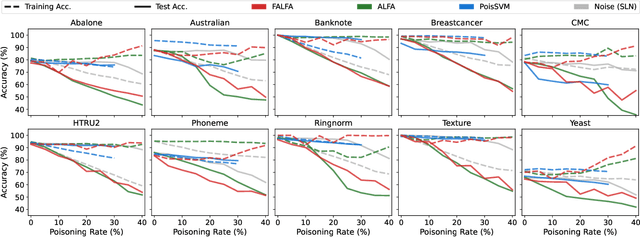
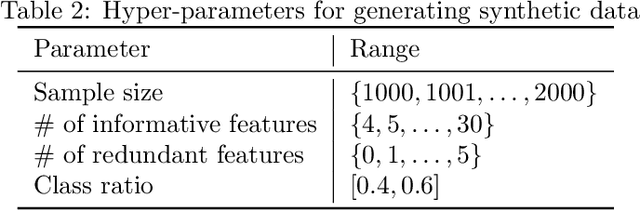
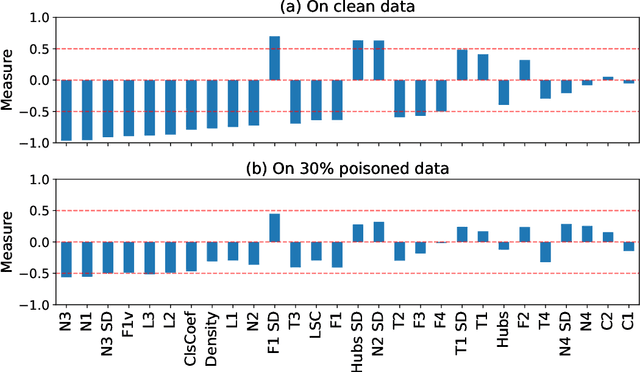
The performance of machine learning models depends on the quality of the underlying data. Malicious actors can attack the model by poisoning the training data. Current detectors are tied to either specific data types, models, or attacks, and therefore have limited applicability in real-world scenarios. This paper presents a novel fully-agnostic framework, DIVA (Detecting InVisible Attacks), that detects attacks solely relying on analyzing the potentially poisoned data set. DIVA is based on the idea that poisoning attacks can be detected by comparing the classifier's accuracy on poisoned and clean data and pre-trains a meta-learner using Complexity Measures to estimate the otherwise unknown accuracy on a hypothetical clean dataset. The framework applies to generic poisoning attacks. For evaluation purposes, in this paper, we test DIVA on label-flipping attacks.