 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEduRABSA: An Education Review Dataset for Aspect-based Sentiment Analysis Tasks
Aug 23, 2025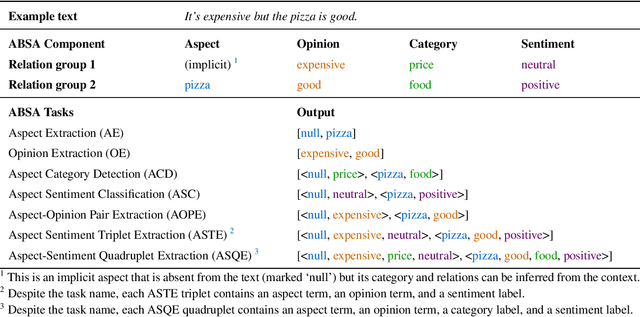
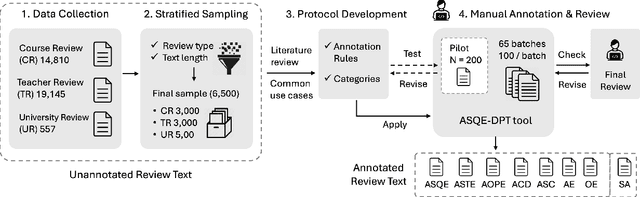
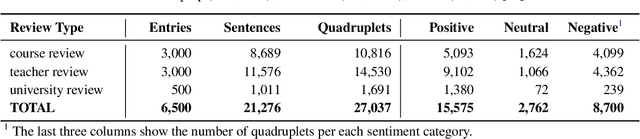
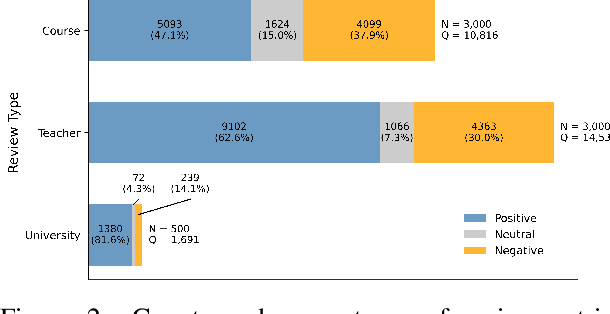
Every year, most educational institutions seek and receive an enormous volume of text feedback from students on courses, teaching, and overall experience. Yet, turning this raw feedback into useful insights is far from straightforward. It has been a long-standing challenge to adopt automatic opinion mining solutions for such education review text data due to the content complexity and low-granularity reporting requirements. Aspect-based Sentiment Analysis (ABSA) offers a promising solution with its rich, sub-sentence-level opinion mining capabilities. However, existing ABSA research and resources are very heavily focused on the commercial domain. In education, they are scarce and hard to develop due to limited public datasets and strict data protection. A high-quality, annotated dataset is urgently needed to advance research in this under-resourced area. In this work, we present EduRABSA (Education Review ABSA), the first public, annotated ABSA education review dataset that covers three review subject types (course, teaching staff, university) in the English language and all main ABSA tasks, including the under-explored implicit aspect and implicit opinion extraction. We also share ASQE-DPT (Data Processing Tool), an offline, lightweight, installation-free manual data annotation tool that generates labelled datasets for comprehensive ABSA tasks from a single-task annotation. Together, these resources contribute to the ABSA community and education domain by removing the dataset barrier, supporting research transparency and reproducibility, and enabling the creation and sharing of further resources. The dataset, annotation tool, and scripts and statistics for dataset processing and sampling are available at https://github.com/yhua219/edurabsa_dataset_and_annotation_tool.
A Systematic Review of Aspect-based Sentiment Analysis : Domains, Methods, and Trends
Dec 03, 2023Aspect-based Sentiment Analysis (ABSA) is a type of fine-grained sentiment analysis (SA) that identifies aspects and the associated opinions from a given text. In the digital era, ABSA gained increasing popularity and applications in mining opinionated text data to obtain insights and support decisions. ABSA research employs linguistic, statistical, and machine-learning approaches and utilises resources such as labelled datasets, aspect and sentiment lexicons and ontology. By its nature, ABSA is domain-dependent and can be sensitive to the impact of misalignment between the resource and application domains. However, to our knowledge, this topic has not been explored by the existing ABSA literature reviews. In this paper, we present a Systematic Literature Review (SLR) of ABSA studies with a focus on the research application domain, dataset domain, and the research methods to examine their relationships and identify trends over time. Our results suggest a number of potential systemic issues in the ABSA research literature, including the predominance of the ``product/service review'' dataset domain among the majority of studies that did not have a specific research application domain, coupled with the prevalence of dataset-reliant methods such as supervised machine learning. This review makes a number of unique contributions to the ABSA research field: 1) To our knowledge, it is the first SLR that links the research domain, dataset domain, and research method through a systematic perspective; 2) it is one of the largest scoped SLR on ABSA, with 519 eligible studies filtered from 4191 search results without time constraint; and 3) our review methodology adopted an innovative automatic filtering process based on PDF-mining, which enhanced screening quality and reliability. Suggestions and our review limitations are also discussed.
Poison is Not Traceless: Fully-Agnostic Detection of Poisoning Attacks
Oct 24, 2023
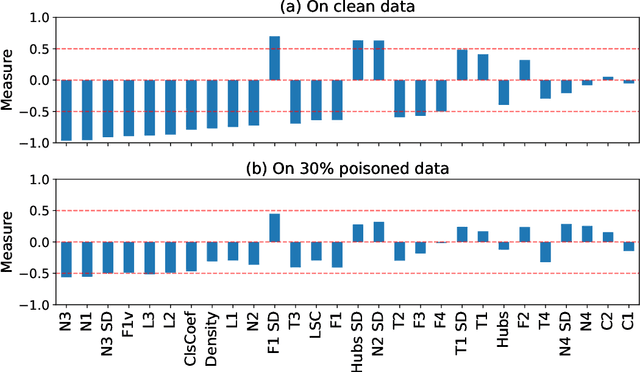
The performance of machine learning models depends on the quality of the underlying data. Malicious actors can attack the model by poisoning the training data. Current detectors are tied to either specific data types, models, or attacks, and therefore have limited applicability in real-world scenarios. This paper presents a novel fully-agnostic framework, DIVA (Detecting InVisible Attacks), that detects attacks solely relying on analyzing the potentially poisoned data set. DIVA is based on the idea that poisoning attacks can be detected by comparing the classifier's accuracy on poisoned and clean data and pre-trains a meta-learner using Complexity Measures to estimate the otherwise unknown accuracy on a hypothetical clean dataset. The framework applies to generic poisoning attacks. For evaluation purposes, in this paper, we test DIVA on label-flipping attacks.
Fast Adversarial Label-Flipping Attack on Tabular Data
Oct 16, 2023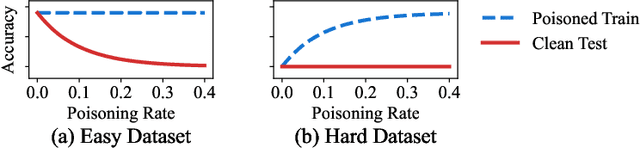
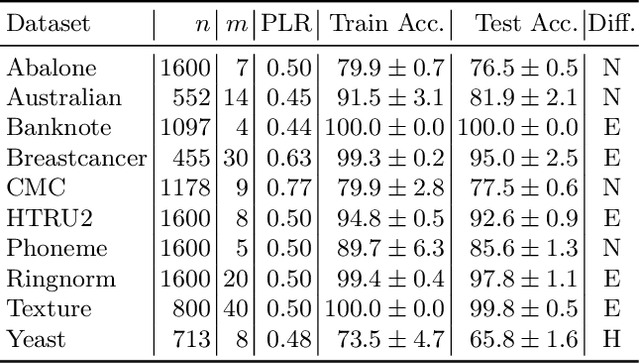
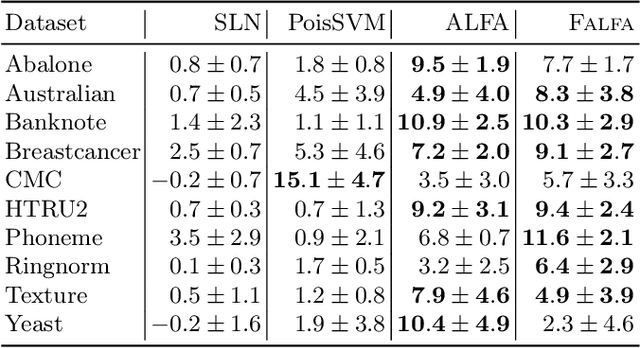
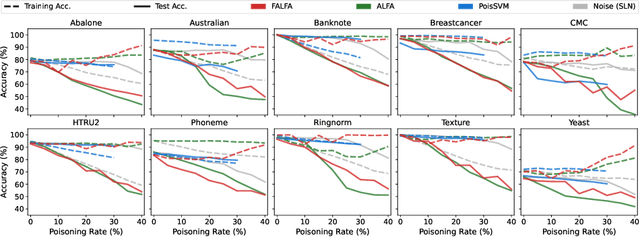
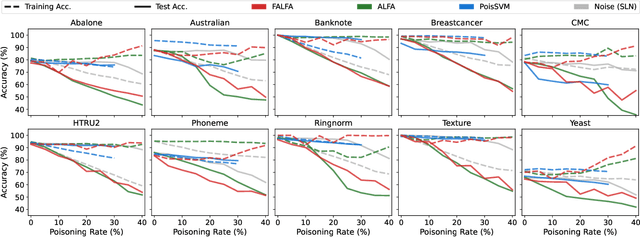
Machine learning models are increasingly used in fields that require high reliability such as cybersecurity. However, these models remain vulnerable to various attacks, among which the adversarial label-flipping attack poses significant threats. In label-flipping attacks, the adversary maliciously flips a portion of training labels to compromise the machine learning model. This paper raises significant concerns as these attacks can camouflage a highly skewed dataset as an easily solvable classification problem, often misleading machine learning practitioners into lower defenses and miscalculations of potential risks. This concern amplifies in tabular data settings, where identifying true labels requires expertise, allowing malicious label-flipping attacks to easily slip under the radar. To demonstrate this risk is inherited in the adversary's objective, we propose FALFA (Fast Adversarial Label-Flipping Attack), a novel efficient attack for crafting adversarial labels. FALFA is based on transforming the adversary's objective and employs linear programming to reduce computational complexity. Using ten real-world tabular datasets, we demonstrate FALFA's superior attack potential, highlighting the need for robust defenses against such threats.
Memento: Facilitating Effortless, Efficient, and Reliable ML Experiments
Apr 17, 2023Running complex sets of machine learning experiments is challenging and time-consuming due to the lack of a unified framework. This leaves researchers forced to spend time implementing necessary features such as parallelization, caching, and checkpointing themselves instead of focussing on their project. To simplify the process, in this paper, we introduce Memento, a Python package that is designed to aid researchers and data scientists in the efficient management and execution of computationally intensive experiments. Memento has the capacity to streamline any experimental pipeline by providing a straightforward configuration matrix and the ability to concurrently run experiments across multiple threads. A demonstration of Memento is available at: https://wickerlab.org/publication/memento.
Hitting the Target: Stopping Active Learning at the Cost-Based Optimum
Oct 07, 2021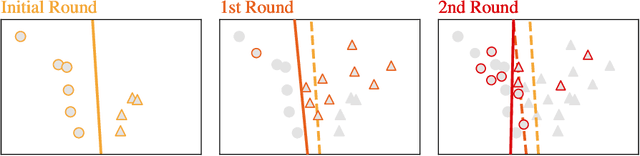

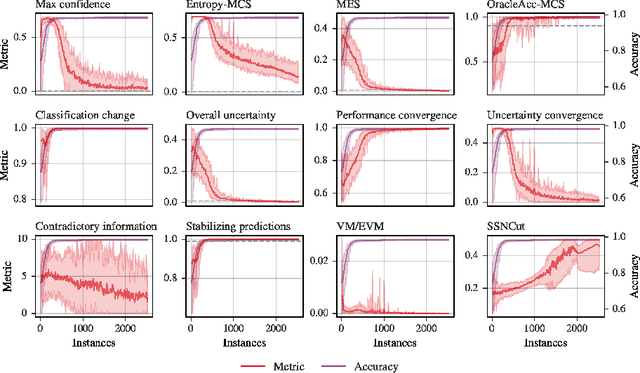
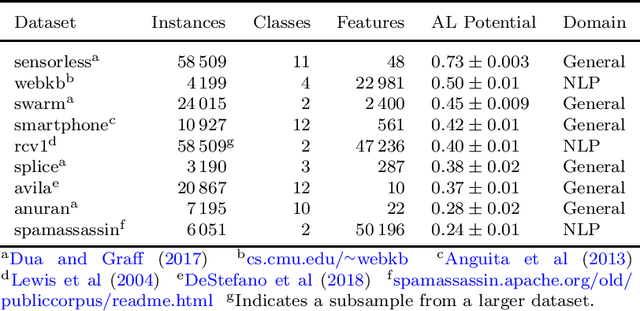
Active learning allows machine learning models to be trained using fewer labels while retaining similar performance to traditional fully supervised learning. An active learner selects the most informative data points, requests their labels, and retrains itself. While this approach is promising, it leaves an open problem of how to determine when the model is `good enough' without the additional labels required for traditional evaluation. In the past, different stopping criteria have been proposed aiming to identify the optimal stopping point. However, optimality can only be expressed as a domain-dependent trade-off between accuracy and the number of labels, and no criterion is superior in all applications. This paper is the first to give actionable advice to practitioners on what stopping criteria they should use in a given real-world scenario. We contribute the first large-scale comparison of stopping criteria, using a cost measure to quantify the accuracy/label trade-off, public implementations of all stopping criteria we evaluate, and an open-source framework for evaluating stopping criteria. Our research enables practitioners to substantially reduce labelling costs by utilizing the stopping criterion which best suits their domain.
Intriguing Usage of Applicability Domain: Lessons from Cheminformatics Applied to Adversarial Learning
May 02, 2021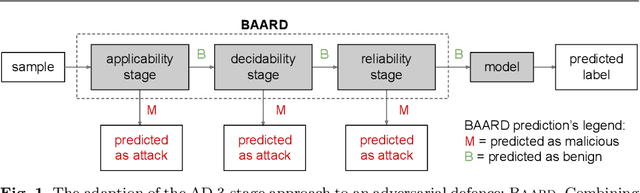
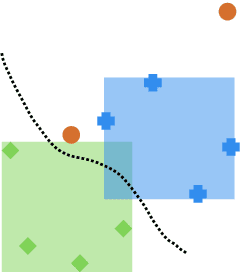
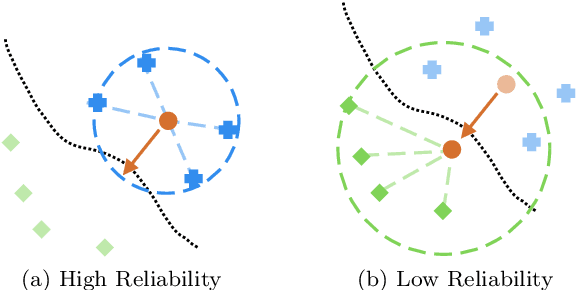
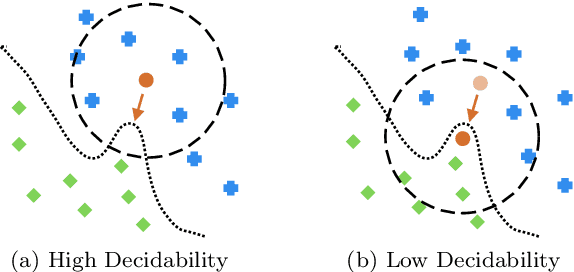
Defending machine learning models from adversarial attacks is still a challenge: none of the robust models is utterly immune to adversarial examples to date. Different defences have been proposed; however, most of them are tailored to particular ML models and adversarial attacks, therefore their effectiveness and applicability are strongly limited. A similar problem plagues cheminformatics: Quantitative Structure-Activity Relationship (QSAR) models struggle to predict biological activity for the entire chemical space because they are trained on a very limited amount of compounds with known effects. This problem is relieved with a technique called Applicability Domain (AD), which rejects the unsuitable compounds for the model. Adversarial examples are intentionally crafted inputs that exploit the blind spots which the model has not learned to classify, and adversarial defences try to make the classifier more robust by covering these blind spots. There is an apparent similarity between AD and adversarial defences. Inspired by the concept of AD, we propose a multi-stage data-driven defence that is testing for: Applicability: abnormal values, namely inputs not compliant with the intended use case of the model; Reliability: samples far from the training data; and Decidability: samples whose predictions contradict the predictions of their neighbours.It can be applied to any classification model and is not limited to specific types of adversarial attacks. With an empirical analysis, this paper demonstrates how Applicability Domain can effectively reduce the vulnerability of ML models to adversarial examples.