 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistently Informative Soft-Label Temperature for Knowledge Distillation
May 19, 2026Knowledge distillation (KD) transfers knowledge from a high-capacity teacher to a compact student by matching their predictive distributions, with temperature scaling serving as a central mechanism for smoothing teacher predictions and exposing informative "dark knowledge" beyond the hard label. However, the standard fixed-temperature design is inherently sample-agnostic. Since samples differ in logit scale and learning difficulty, a single global temperature produces teacher soft labels with highly inconsistent entropy: some predictions remain overly sharp and provide limited inter-class information, whereas others become over-smoothed and lose class-discriminative information. Moreover, sharing the same temperature between teacher and student further imposes rigid logit-scale alignment despite their capacity mismatch. To address these limitations, we propose CIST (Consistently Informative Soft-label Temperature), which assigns separate sample-wise adaptive temperatures to the teacher and student. This design produces consistently informative teacher soft labels while relaxing rigid teacher--student logit-scale matching. It also reweights the distillation objective according to teacher confidence and student learning difficulty. Theoretically, we show that teacher-label entropy is largely governed by the ratio between the maximum teacher logit and the temperature, providing a principled basis for adaptive smoothing. Empirically, CIST mitigates the inconsistency induced by fixed temperature, and experiments on both vision and language distillation tasks show consistent improvements over standard KD and strong baselines with negligible computational overhead.
Urban-ImageNet: A Large-Scale Multi-Modal Dataset and Evaluation Framework for Urban Space Perception
May 11, 2026We present Urban-ImageNet, a large-scale multi-modal dataset and evaluation benchmark for urban space perception from user-generated social media imagery. The corpus contains over 2 Million public social media images and paired textual posts collected from Weibo across 61 urban sites in 24 Chinese cities across 2019-2025, with controlled benchmark subsets at 1K, 10K, and 100K scale and a full 2M corpus for large-scale training and evaluation. Urban-ImageNet is organized by HUSIC, a Hierarchical Urban Space Image Classification framework that defines a 10-class taxonomy grounded in urban theory. The taxonomy is designed to distinguish activated and non-activated public spaces, exterior and interior urban environments, accommodation spaces, consumption content, portraits, and non-spatial social-media content. Rather than treating urban imagery as generic scene data, Urban-ImageNet evaluates whether machine perception models can capture spatial, social, and functional distinctions that are central to urban studies. The benchmark supports three tasks within one standardized library: (T1) urban scene semantic classification, (T2) cross-modal image-text retrieval, and (T3) instance segmentation. Our experiments evaluate representative vision, vision-language, and segmentation models, revealing strong performance on supervised scene classification but more challenging behavior in cross-modal retrieval and instance-level urban object segmentation. A multi-scale study further examines how model performance changes as balanced training data increases from 1K, 10K to 100K images. Urban-ImageNet provides a unified, theory-grounded, multi-city benchmark for evaluating how AI systems perceive and interpret contemporary urban spaces across modalities, scales, and task formulations. Dataset and benchmark are available at: huggingface.co/datasets/Yiwei-Ou/Urban-ImageNet and github.com/yiasun/dataset-2.
AnchorGK: Anchor-based Incremental and Stratified Graph Learning Framework for Inductive Spatio-Temporal Kriging
Dec 25, 2025Spatio-temporal kriging is a fundamental problem in sensor networks, driven by the sparsity of deployed sensors and the resulting missing observations. Although recent approaches model spatial and temporal correlations, they often under-exploit two practical characteristics of real deployments: the sparse spatial distribution of locations and the heterogeneous availability of auxiliary features across locations. To address these challenges, we propose AnchorGK, an Anchor-based Incremental and Stratified Graph Learning framework for inductive spatio-temporal kriging. AnchorGK introduces anchor locations to stratify the data in a principled manner. Anchors are constructed according to feature availability, and strata are then formed around these anchors. This stratification serves two complementary roles. First, it explicitly represents and continuously updates correlations between unobserved regions and surrounding observed locations within a graph learning framework. Second, it enables the systematic use of all available features across strata via an incremental representation mechanism, mitigating feature incompleteness without discarding informative signals. Building on the stratified structure, we design a dual-view graph learning layer that jointly aggregates feature-relevant and location-relevant information, learning stratum-specific representations that support accurate inference under inductive settings. Extensive experiments on multiple benchmark datasets demonstrate that AnchorGK consistently outperforms state-of-the-art baselines for spatio-temporal kriging.
Data-Augmented Quantization-Aware Knowledge Distillation
Sep 04, 2025Quantization-aware training (QAT) and Knowledge Distillation (KD) are combined to achieve competitive performance in creating low-bit deep learning models. Existing KD and QAT works focus on improving the accuracy of quantized models from the network output perspective by designing better KD loss functions or optimizing QAT's forward and backward propagation. However, limited attention has been given to understanding the impact of input transformations, such as data augmentation (DA). The relationship between quantization-aware KD and DA remains unexplored. In this paper, we address the question: how to select a good DA in quantization-aware KD, especially for the models with low precisions? We propose a novel metric which evaluates DAs according to their capacity to maximize the Contextual Mutual Information--the information not directly related to an image's label--while also ensuring the predictions for each class are close to the ground truth labels on average. The proposed method automatically ranks and selects DAs, requiring minimal training overhead, and it is compatible with any KD or QAT algorithm. Extensive evaluations demonstrate that selecting DA strategies using our metric significantly improves state-of-the-art QAT and KD works across various model architectures and datasets.
Situational-Constrained Sequential Resources Allocation via Reinforcement Learning
Jun 17, 2025



Sequential Resource Allocation with situational constraints presents a significant challenge in real-world applications, where resource demands and priorities are context-dependent. This paper introduces a novel framework, SCRL, to address this problem. We formalize situational constraints as logic implications and develop a new algorithm that dynamically penalizes constraint violations. To handle situational constraints effectively, we propose a probabilistic selection mechanism to overcome limitations of traditional constraint reinforcement learning (CRL) approaches. We evaluate SCRL across two scenarios: medical resource allocation during a pandemic and pesticide distribution in agriculture. Experiments demonstrate that SCRL outperforms existing baselines in satisfying constraints while maintaining high resource efficiency, showcasing its potential for real-world, context-sensitive decision-making tasks.
MMS-VPR: Multimodal Street-Level Visual Place Recognition Dataset and Benchmark
May 18, 2025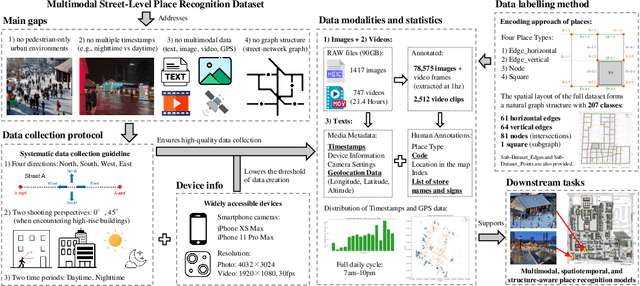


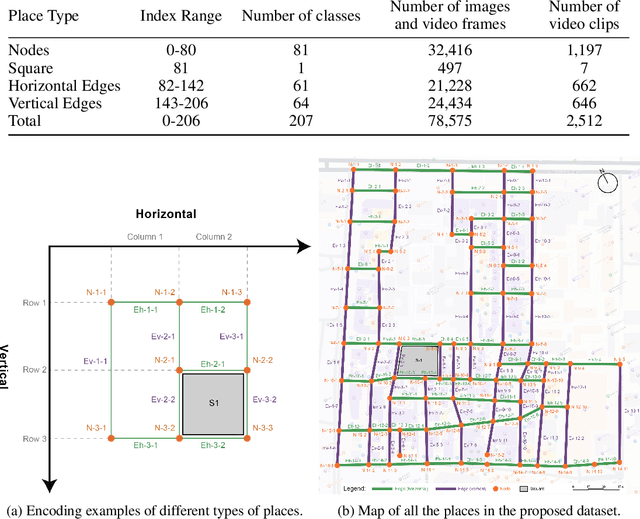
Existing visual place recognition (VPR) datasets predominantly rely on vehicle-mounted imagery, lack multimodal diversity and underrepresent dense, mixed-use street-level spaces, especially in non-Western urban contexts. To address these gaps, we introduce MMS-VPR, a large-scale multimodal dataset for street-level place recognition in complex, pedestrian-only environments. The dataset comprises 78,575 annotated images and 2,512 video clips captured across 207 locations in a ~70,800 $\mathrm{m}^2$ open-air commercial district in Chengdu, China. Each image is labeled with precise GPS coordinates, timestamp, and textual metadata, and covers varied lighting conditions, viewpoints, and timeframes. MMS-VPR follows a systematic and replicable data collection protocol with minimal device requirements, lowering the barrier for scalable dataset creation. Importantly, the dataset forms an inherent spatial graph with 125 edges, 81 nodes, and 1 subgraph, enabling structure-aware place recognition. We further define two application-specific subsets -- Dataset_Edges and Dataset_Points -- to support fine-grained and graph-based evaluation tasks. Extensive benchmarks using conventional VPR models, graph neural networks, and multimodal baselines show substantial improvements when leveraging multimodal and structural cues. MMS-VPR facilitates future research at the intersection of computer vision, geospatial understanding, and multimodal reasoning. The dataset is publicly available at https://huggingface.co/datasets/Yiwei-Ou/MMS-VPR.
ACE: A Cardinality Estimator for Set-Valued Queries
Mar 19, 2025Cardinality estimation is a fundamental functionality in database systems. Most existing cardinality estimators focus on handling predicates over numeric or categorical data. They have largely omitted an important data type, set-valued data, which frequently occur in contemporary applications such as information retrieval and recommender systems. The few existing estimators for such data either favor high-frequency elements or rely on a partial independence assumption, which limits their practical applicability. We propose ACE, an Attention-based Cardinality Estimator for estimating the cardinality of queries over set-valued data. We first design a distillation-based data encoder to condense the dataset into a compact matrix. We then design an attention-based query analyzer to capture correlations among query elements. To handle variable-sized queries, a pooling module is introduced, followed by a regression model (MLP) to generate final cardinality estimates. We evaluate ACE on three datasets with varying query element distributions, demonstrating that ACE outperforms the state-of-the-art competitors in terms of both accuracy and efficiency.
Self-supervised Learning for Geospatial AI: A Survey
Aug 22, 2024



The proliferation of geospatial data in urban and territorial environments has significantly facilitated the development of geospatial artificial intelligence (GeoAI) across various urban applications. Given the vast yet inherently sparse labeled nature of geospatial data, there is a critical need for techniques that can effectively leverage such data without heavy reliance on labeled datasets. This requirement aligns with the principles of self-supervised learning (SSL), which has attracted increasing attention for its adoption in geospatial data. This paper conducts a comprehensive and up-to-date survey of SSL techniques applied to or developed for three primary data (geometric) types prevalent in geospatial vector data: points, polylines, and polygons. We systematically categorize various SSL techniques into predictive and contrastive methods, discussing their application with respect to each data type in enhancing generalization across various downstream tasks. Furthermore, we review the emerging trends of SSL for GeoAI, and several task-specific SSL techniques. Finally, we discuss several key challenges in the current research and outline promising directions for future investigation. By presenting a structured analysis of relevant studies, this paper aims to inspire continued advancements in the integration of SSL with GeoAI, encouraging innovative methods to harnessing the power of geospatial data.
Self-Supervised Quantization-Aware Knowledge Distillation
Mar 17, 2024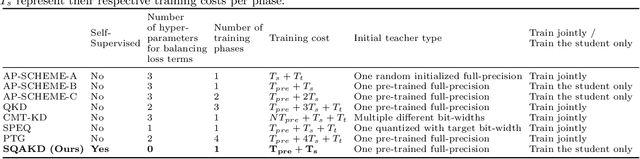
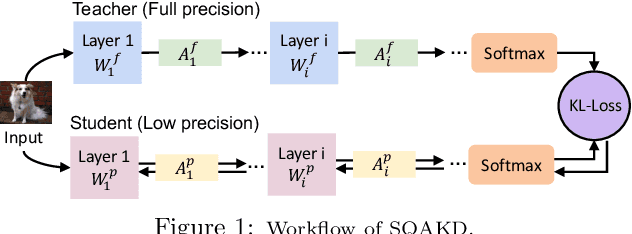
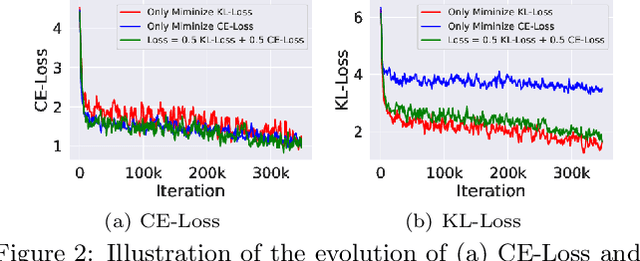

Quantization-aware training (QAT) and Knowledge Distillation (KD) are combined to achieve competitive performance in creating low-bit deep learning models. However, existing works applying KD to QAT require tedious hyper-parameter tuning to balance the weights of different loss terms, assume the availability of labeled training data, and require complex, computationally intensive training procedures for good performance. To address these limitations, this paper proposes a novel Self-Supervised Quantization-Aware Knowledge Distillation (SQAKD) framework. SQAKD first unifies the forward and backward dynamics of various quantization functions, making it flexible for incorporating various QAT works. Then it formulates QAT as a co-optimization problem that simultaneously minimizes the KL-Loss between the full-precision and low-bit models for KD and the discretization error for quantization, without supervision from labels. A comprehensive evaluation shows that SQAKD substantially outperforms the state-of-the-art QAT and KD works for a variety of model architectures. Our code is at: https://github.com/kaiqi123/SQAKD.git.
CSG: Curriculum Representation Learning for Signed Graph
Oct 17, 2023



Signed graphs are valuable for modeling complex relationships with positive and negative connections, and Signed Graph Neural Networks (SGNNs) have become crucial tools for their analysis. However, prior to our work, no specific training plan existed for SGNNs, and the conventional random sampling approach did not address varying learning difficulties within the graph's structure. We proposed a curriculum-based training approach, where samples progress from easy to complex, inspired by human learning. To measure learning difficulty, we introduced a lightweight mechanism and created the Curriculum representation learning framework for Signed Graphs (CSG). This framework optimizes the order in which samples are presented to the SGNN model. Empirical validation across six real-world datasets showed impressive results, enhancing SGNN model accuracy by up to 23.7% in link sign prediction (AUC) and significantly improving stability with an up to 8.4 reduction in the standard deviation of AUC scores.