 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Guided Dual-Arm Humanoid Robotic Disassembly of End-of-Life 18650 Lithium-ion Battery Packs
Jun 06, 2026The growing volume of retired lithium-ion battery packs from electric vehicles and portable electronics calls for automated disassembly that is safe, flexible, and selective down to the individual cell. Existing robotic systems, however, mostly assume known pack poses, external fixtures, or specialised tooling, leaving fixture-free cell-level disassembly under pose uncertainty largely unsolved. This paper presents a vision-guided dual-arm pipeline that disassembles a 21-cell 18650 pack from an arbitrary initial pose using only general-purpose parallel-jaw grippers, RGB-D sensing, and a pre-trained grasp detector. Pose uncertainty is absorbed by a learn-and-filter perception stack with discrete look-and-move wrist-camera corrections, while a mid-task support transfer between the two arms extends the effective workspace without any external clamp. The pipeline achieves an 8/10 end-to-end success rate, a cell-localisation root-mean-square error of $2.4$\,mm, and a mean cycle time of 6.0\,minutes per pack, providing a practical, fixture-free building block for industrial battery recycling.
Bus-Conditioned Zero-Shot Trajectory Generation via Task Arithmetic
Feb 13, 2026Mobility trajectory data provide essential support for smart city applications. However, such data are often difficult to obtain. Meanwhile, most existing trajectory generation methods implicitly assume that at least a subset of real mobility data from target city is available, which limits their applicability in data-inaccessible scenarios. In this work, we propose a new problem setting, called bus-conditioned zero-shot trajectory generation, where no mobility trajectories from a target city are accessible. The generation process relies solely on source city mobility data and publicly available bus timetables from both cities. Under this setting, we propose MobTA, the first approach to introduce task arithmetic into trajectory generation. MobTA models the parameter shift from bus-timetable-based trajectory generation to mobility trajectory generation in source city, and applies this shift to target city through arithmetic operations on task vectors. This enables trajectory generation that reflects target-city mobility patterns without requiring any real mobility data from it. Furthermore, we theoretically analyze MobTA's stability across base and instruction-tuned LLMs. Extensive experiments show that MobTA significantly outperforms existing methods, and achieves performance close to models finetuned using target city mobility trajectories.
STRATA-TS: Selective Knowledge Transfer for Urban Time Series Forecasting with Retrieval-Guided Reasoning
Aug 26, 2025Urban forecasting models often face a severe data imbalance problem: only a few cities have dense, long-span records, while many others expose short or incomplete histories. Direct transfer from data-rich to data-scarce cities is unreliable because only a limited subset of source patterns truly benefits the target domain, whereas indiscriminate transfer risks introducing noise and negative transfer. We present STRATA-TS (Selective TRAnsfer via TArget-aware retrieval for Time Series), a framework that combines domain-adapted retrieval with reasoning-capable large models to improve forecasting in scarce data regimes. STRATA-TS employs a patch-based temporal encoder to identify source subsequences that are semantically and dynamically aligned with the target query. These retrieved exemplars are then injected into a retrieval-guided reasoning stage, where an LLM performs structured inference over target inputs and retrieved support. To enable efficient deployment, we distill the reasoning process into a compact open model via supervised fine-tuning. Extensive experiments on three parking availability datasets across Singapore, Nottingham, and Glasgow demonstrate that STRATA-TS consistently outperforms strong forecasting and transfer baselines, while providing interpretable knowledge transfer pathways.
Mixture-of-Experts for Personalized and Semantic-Aware Next Location Prediction
May 30, 2025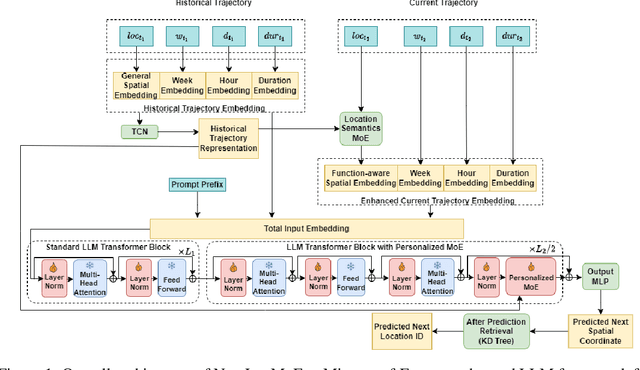
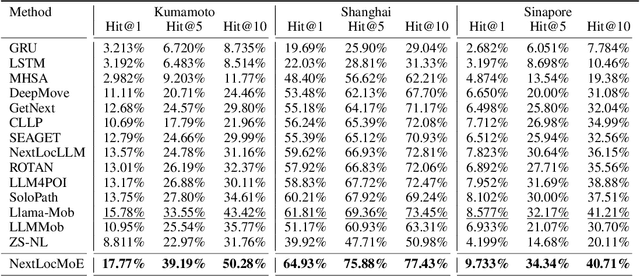
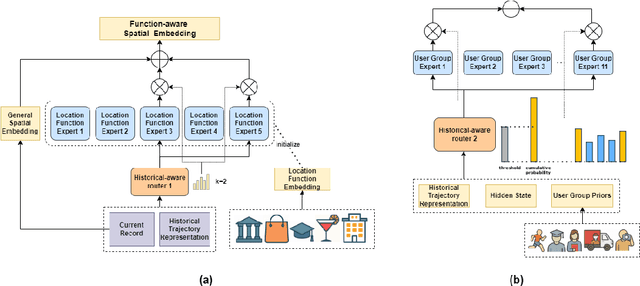
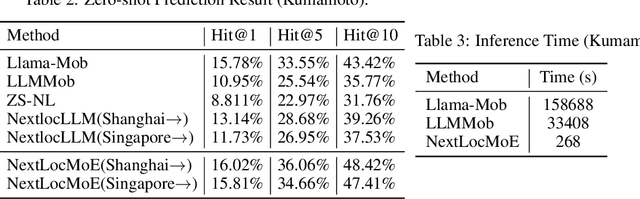
Next location prediction plays a critical role in understanding human mobility patterns. However, existing approaches face two core limitations: (1) they fall short in capturing the complex, multi-functional semantics of real-world locations; and (2) they lack the capacity to model heterogeneous behavioral dynamics across diverse user groups. To tackle these challenges, we introduce NextLocMoE, a novel framework built upon large language models (LLMs) and structured around a dual-level Mixture-of-Experts (MoE) design. Our architecture comprises two specialized modules: a Location Semantics MoE that operates at the embedding level to encode rich functional semantics of locations, and a Personalized MoE embedded within the Transformer backbone to dynamically adapt to individual user mobility patterns. In addition, we incorporate a history-aware routing mechanism that leverages long-term trajectory data to enhance expert selection and ensure prediction stability. Empirical evaluations across several real-world urban datasets show that NextLocMoE achieves superior performance in terms of predictive accuracy, cross-domain generalization, and interpretability
FlexTSF: A Universal Forecasting Model for Time Series with Variable Regularities
Oct 30, 2024Developing a foundation model for time series forecasting across diverse domains has attracted significant attention in recent years. Existing works typically assume regularly sampled, well-structured data, limiting their applicability to more generalized scenarios where time series often contain missing values, unequal sequence lengths, and irregular time intervals between measurements. To cover diverse domains and handle variable regularities, we propose FlexTSF, a universal time series forecasting model that possesses better generalization and natively support both regular and irregular time series. FlexTSF produces forecasts in an autoregressive manner and incorporates three novel designs: VT-Norm, a normalization strategy to ablate data domain barriers, IVP Patcher, a patching module to learn representations from flexibly structured time series, and LED attention, an attention mechanism to seamlessly integrate these two and propagate forecasts with awareness of domain and time information. Experiments on 12 datasets show that FlexTSF outperforms state-of-the-art forecasting models respectively designed for regular and irregular time series. Furthermore, after self-supervised pre-training, FlexTSF shows exceptional performance in both zero-shot and few-show settings for time series forecasting.
Context-Enhanced Multi-View Trajectory Representation Learning: Bridging the Gap through Self-Supervised Models
Oct 17, 2024
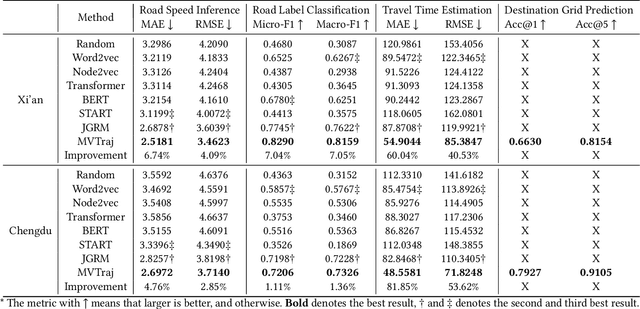
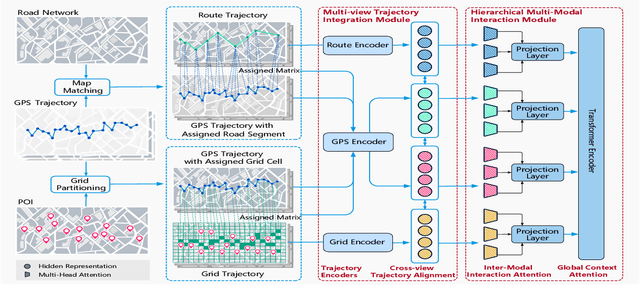

Modeling trajectory data with generic-purpose dense representations has become a prevalent paradigm for various downstream applications, such as trajectory classification, travel time estimation and similarity computation. However, existing methods typically rely on trajectories from a single spatial view, limiting their ability to capture the rich contextual information that is crucial for gaining deeper insights into movement patterns across different geospatial contexts. To this end, we propose MVTraj, a novel multi-view modeling method for trajectory representation learning. MVTraj integrates diverse contextual knowledge, from GPS to road network and points-of-interest to provide a more comprehensive understanding of trajectory data. To align the learning process across multiple views, we utilize GPS trajectories as a bridge and employ self-supervised pretext tasks to capture and distinguish movement patterns across different spatial views. Following this, we treat trajectories from different views as distinct modalities and apply a hierarchical cross-modal interaction module to fuse the representations, thereby enriching the knowledge derived from multiple sources. Extensive experiments on real-world datasets demonstrate that MVTraj significantly outperforms existing baselines in tasks associated with various spatial views, validating its effectiveness and practical utility in spatio-temporal modeling.
nextlocllm: next location prediction using LLMs
Oct 11, 2024



Next location prediction is a critical task in human mobility analysis and serves as a foundation for various downstream applications. Existing methods typically rely on discrete IDs to represent locations, which inherently overlook spatial relationships and cannot generalize across cities. In this paper, we propose NextLocLLM, which leverages the advantages of large language models (LLMs) in processing natural language descriptions and their strong generalization capabilities for next location prediction. Specifically, instead of using IDs, NextLocLLM encodes locations based on continuous spatial coordinates to better model spatial relationships. These coordinates are further normalized to enable robust cross-city generalization. Another highlight of NextlocLLM is its LLM-enhanced POI embeddings. It utilizes LLMs' ability to encode each POI category's natural language description into embeddings. These embeddings are then integrated via nonlinear projections to form this LLM-enhanced POI embeddings, effectively capturing locations' functional attributes. Furthermore, task and data prompt prefix, together with trajectory embeddings, are incorporated as input for partly-frozen LLM backbone. NextLocLLM further introduces prediction retrieval module to ensure structural consistency in prediction. Experiments show that NextLocLLM outperforms existing models in next location prediction, excelling in both supervised and zero-shot settings.
Self-supervised Learning for Geospatial AI: A Survey
Aug 22, 2024



The proliferation of geospatial data in urban and territorial environments has significantly facilitated the development of geospatial artificial intelligence (GeoAI) across various urban applications. Given the vast yet inherently sparse labeled nature of geospatial data, there is a critical need for techniques that can effectively leverage such data without heavy reliance on labeled datasets. This requirement aligns with the principles of self-supervised learning (SSL), which has attracted increasing attention for its adoption in geospatial data. This paper conducts a comprehensive and up-to-date survey of SSL techniques applied to or developed for three primary data (geometric) types prevalent in geospatial vector data: points, polylines, and polygons. We systematically categorize various SSL techniques into predictive and contrastive methods, discussing their application with respect to each data type in enhancing generalization across various downstream tasks. Furthermore, we review the emerging trends of SSL for GeoAI, and several task-specific SSL techniques. Finally, we discuss several key challenges in the current research and outline promising directions for future investigation. By presenting a structured analysis of relevant studies, this paper aims to inspire continued advancements in the integration of SSL with GeoAI, encouraging innovative methods to harnessing the power of geospatial data.
SAGDFN: A Scalable Adaptive Graph Diffusion Forecasting Network for Multivariate Time Series Forecasting
Jun 18, 2024


Time series forecasting is essential for our daily activities and precise modeling of the complex correlations and shared patterns among multiple time series is essential for improving forecasting performance. Spatial-Temporal Graph Neural Networks (STGNNs) are widely used in multivariate time series forecasting tasks and have achieved promising performance on multiple real-world datasets for their ability to model the underlying complex spatial and temporal dependencies. However, existing studies have mainly focused on datasets comprising only a few hundred sensors due to the heavy computational cost and memory cost of spatial-temporal GNNs. When applied to larger datasets, these methods fail to capture the underlying complex spatial dependencies and exhibit limited scalability and performance. To this end, we present a Scalable Adaptive Graph Diffusion Forecasting Network (SAGDFN) to capture complex spatial-temporal correlation for large-scale multivariate time series and thereby, leading to exceptional performance in multivariate time series forecasting tasks. The proposed SAGDFN is scalable to datasets of thousands of nodes without the need of prior knowledge of spatial correlation. Extensive experiments demonstrate that SAGDFN achieves comparable performance with state-of-the-art baselines on one real-world dataset of 207 nodes and outperforms all state-of-the-art baselines by a significant margin on three real-world datasets of 2000 nodes.
UrbanLLM: Autonomous Urban Activity Planning and Management with Large Language Models
Jun 18, 2024



Location-based services play an critical role in improving the quality of our daily lives. Despite the proliferation of numerous specialized AI models within spatio-temporal context of location-based services, these models struggle to autonomously tackle problems regarding complex urban planing and management. To bridge this gap, we introduce UrbanLLM, a fine-tuned large language model (LLM) designed to tackle diverse problems in urban scenarios. UrbanLLM functions as a problem-solver by decomposing urban-related queries into manageable sub-tasks, identifying suitable spatio-temporal AI models for each sub-task, and generating comprehensive responses to the given queries. Our experimental results indicate that UrbanLLM significantly outperforms other established LLMs, such as Llama and the GPT series, in handling problems concerning complex urban activity planning and management. UrbanLLM exhibits considerable potential in enhancing the effectiveness of solving problems in urban scenarios, reducing the workload and reliance for human experts.