 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sketch+Text Composed Image Retrieval Dataset for Thangka
Feb 09, 2026Composed Image Retrieval (CIR) enables image retrieval by combining multiple query modalities, but existing benchmarks predominantly focus on general-domain imagery and rely on reference images with short textual modifications. As a result, they provide limited support for retrieval scenarios that require fine-grained semantic reasoning, structured visual understanding, and domain-specific knowledge. In this work, we introduce CIRThan, a sketch+text Composed Image Retrieval dataset for Thangka imagery, a culturally grounded and knowledge-specific visual domain characterized by complex structures, dense symbolic elements, and domain-dependent semantic conventions. CIRThan contains 2,287 high-quality Thangka images, each paired with a human-drawn sketch and hierarchical textual descriptions at three semantic levels, enabling composed queries that jointly express structural intent and multi-level semantic specification. We provide standardized data splits, comprehensive dataset analysis, and benchmark evaluations of representative supervised and zero-shot CIR methods. Experimental results reveal that existing CIR approaches, largely developed for general-domain imagery, struggle to effectively align sketch-based abstractions and hierarchical textual semantics with fine-grained Thangka images, particularly without in-domain supervision. We believe CIRThan offers a valuable benchmark for advancing sketch+text CIR, hierarchical semantic modeling, and multimodal retrieval in cultural heritage and other knowledge-specific visual domains. The dataset is publicly available at https://github.com/jinyuxu-whut/CIRThan.
Enhancing Transferability and Consistency in Cross-Domain Recommendations via Supervised Disentanglement
Jul 23, 2025Cross-domain recommendation (CDR) aims to alleviate the data sparsity by transferring knowledge across domains. Disentangled representation learning provides an effective solution to model complex user preferences by separating intra-domain features (domain-shared and domain-specific features), thereby enhancing robustness and interpretability. However, disentanglement-based CDR methods employing generative modeling or GNNs with contrastive objectives face two key challenges: (i) pre-separation strategies decouple features before extracting collaborative signals, disrupting intra-domain interactions and introducing noise; (ii) unsupervised disentanglement objectives lack explicit task-specific guidance, resulting in limited consistency and suboptimal alignment. To address these challenges, we propose DGCDR, a GNN-enhanced encoder-decoder framework. To handle challenge (i), DGCDR first applies GNN to extract high-order collaborative signals, providing enriched representations as a robust foundation for disentanglement. The encoder then dynamically disentangles features into domain-shared and -specific spaces, preserving collaborative information during the separation process. To handle challenge (ii), the decoder introduces an anchor-based supervision that leverages hierarchical feature relationships to enhance intra-domain consistency and cross-domain alignment. Extensive experiments on real-world datasets demonstrate that DGCDR achieves state-of-the-art performance, with improvements of up to 11.59% across key metrics. Qualitative analyses further validate its superior disentanglement quality and transferability. Our source code and datasets are available on GitHub for further comparison.
Robust Table Integration in Data Lakes
Nov 30, 2024In this paper, we investigate the challenge of integrating tables from data lakes, focusing on three core tasks: 1) pairwise integrability judgment, which determines whether a tuple pair in a table is integrable, accounting for any occurrences of semantic equivalence or typographical errors; 2) integrable set discovery, which aims to identify all integrable sets in a table based on pairwise integrability judgments established in the first task; 3) multi-tuple conflict resolution, which resolves conflicts among multiple tuples during integration. We train a binary classifier to address the task of pairwise integrability judgment. Given the scarcity of labeled data, we propose a self-supervised adversarial contrastive learning algorithm to perform classification, which incorporates data augmentation methods and adversarial examples to autonomously generate new training data. Upon the output of pairwise integrability judgment, each integrable set is considered as a community, a densely connected sub-graph where nodes and edges correspond to tuples in the table and their pairwise integrability, respectively. We proceed to investigate various community detection algorithms to address the integrable set discovery objective. Moving forward to tackle multi-tuple conflict resolution, we introduce an novel in-context learning methodology. This approach capitalizes on the knowledge embedded within pretrained large language models to effectively resolve conflicts that arise when integrating multiple tuples. Notably, our method minimizes the need for annotated data. Since no suitable test collections are available for our tasks, we develop our own benchmarks using two real-word dataset repositories: Real and Join. We conduct extensive experiments on these benchmarks to validate the robustness and applicability of our methodologies in the context of integrating tables within data lakes.
Urban Traffic Accident Risk Prediction Revisited: Regionality, Proximity, Similarity and Sparsity
Jul 29, 2024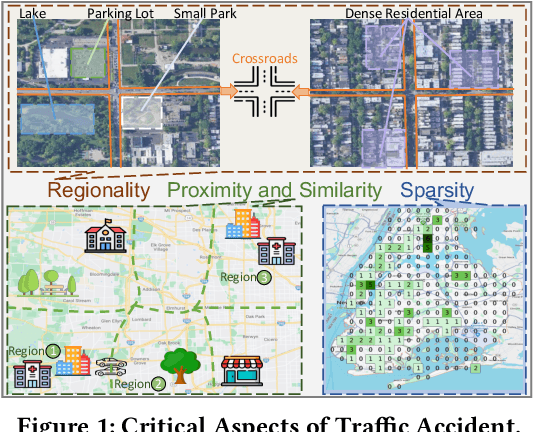
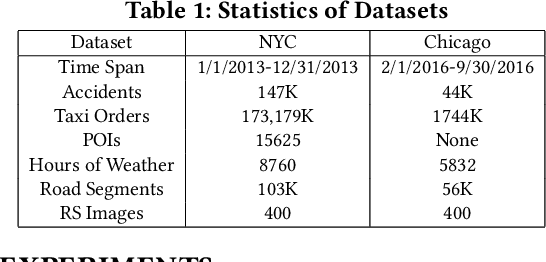
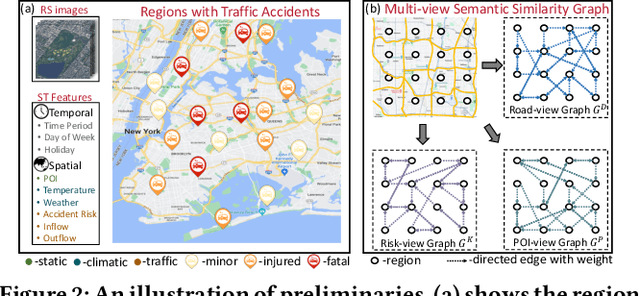
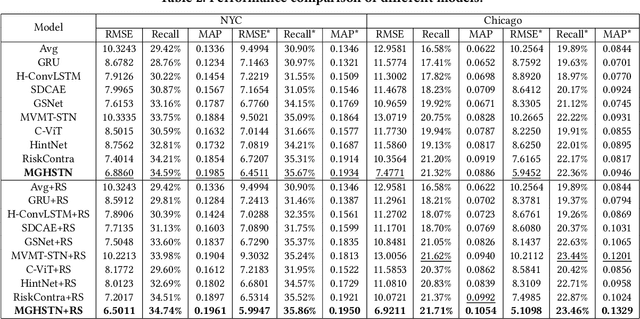
Traffic accidents pose a significant risk to human health and property safety. Therefore, to prevent traffic accidents, predicting their risks has garnered growing interest. We argue that a desired prediction solution should demonstrate resilience to the complexity of traffic accidents. In particular, it should adequately consider the regional background, accurately capture both spatial proximity and semantic similarity, and effectively address the sparsity of traffic accidents. However, these factors are often overlooked or difficult to incorporate. In this paper, we propose a novel multi-granularity hierarchical spatio-temporal network. Initially, we innovate by incorporating remote sensing data, facilitating the creation of hierarchical multi-granularity structure and the comprehension of regional background. We construct multiple high-level risk prediction tasks to enhance model's ability to cope with sparsity. Subsequently, to capture both spatial proximity and semantic similarity, region feature and multi-view graph undergo encoding processes to distill effective representations. Additionally, we propose message passing and adaptive temporal attention module that bridges different granularities and dynamically captures time correlations inherent in traffic accident patterns. At last, a multivariate hierarchical loss function is devised considering the complexity of the prediction purpose. Extensive experiments on two real datasets verify the superiority of our model against the state-of-the-art methods.
Enabling Roll-up and Drill-down Operations in News Exploration with Knowledge Graphs for Due Diligence and Risk Management
May 08, 2024

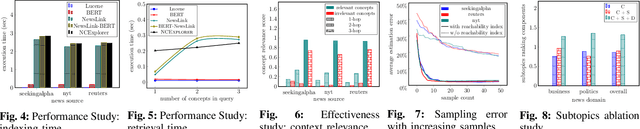

Efficient news exploration is crucial in real-world applications, particularly within the financial sector, where numerous control and risk assessment tasks rely on the analysis of public news reports. The current processes in this domain predominantly rely on manual efforts, often involving keywordbased searches and the compilation of extensive keyword lists. In this paper, we introduce NCEXPLORER, a framework designed with OLAP-like operations to enhance the news exploration experience. NCEXPLORER empowers users to use roll-up operations for a broader content overview and drill-down operations for detailed insights. These operations are achieved through integration with external knowledge graphs (KGs), encompassing both fact-based and ontology-based structures. This integration significantly augments exploration capabilities, offering a more comprehensive and efficient approach to unveiling the underlying structures and nuances embedded in news content. Extensive empirical studies through master-qualified evaluators on Amazon Mechanical Turk demonstrate NCEXPLORER's superiority over existing state-of-the-art news search methodologies across an array of topic domains, using real-world news datasets.
Semantic-Enhanced Representation Learning for Road Networks with Temporal Dynamics
Mar 18, 2024
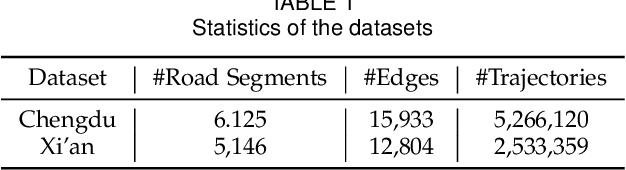
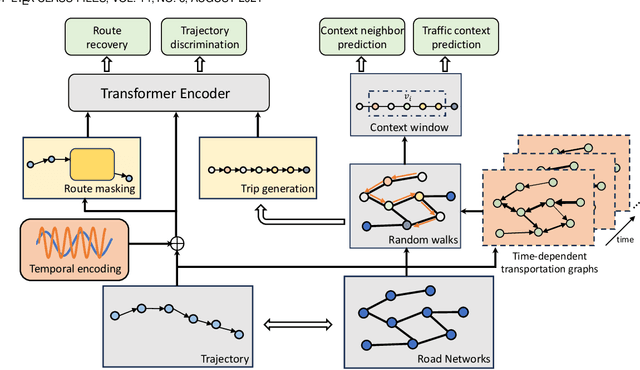

In this study, we introduce a novel framework called Toast for learning general-purpose representations of road networks, along with its advanced counterpart DyToast, designed to enhance the integration of temporal dynamics to boost the performance of various time-sensitive downstream tasks. Specifically, we propose to encode two pivotal semantic characteristics intrinsic to road networks: traffic patterns and traveling semantics. To achieve this, we refine the skip-gram module by incorporating auxiliary objectives aimed at predicting the traffic context associated with a target road segment. Moreover, we leverage trajectory data and design pre-training strategies based on Transformer to distill traveling semantics on road networks. DyToast further augments this framework by employing unified trigonometric functions characterized by their beneficial properties, enabling the capture of temporal evolution and dynamic nature of road networks more effectively. With these proposed techniques, we can obtain representations that encode multi-faceted aspects of knowledge within road networks, applicable across both road segment-based applications and trajectory-based applications. Extensive experiments on two real-world datasets across three tasks demonstrate that our proposed framework consistently outperforms the state-of-the-art baselines by a significant margin.
GraphRARE: Reinforcement Learning Enhanced Graph Neural Network with Relative Entropy
Dec 15, 2023



Graph neural networks (GNNs) have shown advantages in graph-based analysis tasks. However, most existing methods have the homogeneity assumption and show poor performance on heterophilic graphs, where the linked nodes have dissimilar features and different class labels, and the semantically related nodes might be multi-hop away. To address this limitation, this paper presents GraphRARE, a general framework built upon node relative entropy and deep reinforcement learning, to strengthen the expressive capability of GNNs. An innovative node relative entropy, which considers node features and structural similarity, is used to measure mutual information between node pairs. In addition, to avoid the sub-optimal solutions caused by mixing useful information and noises of remote nodes, a deep reinforcement learning-based algorithm is developed to optimize the graph topology. This algorithm selects informative nodes and discards noisy nodes based on the defined node relative entropy. Extensive experiments are conducted on seven real-world datasets. The experimental results demonstrate the superiority of GraphRARE in node classification and its capability to optimize the original graph topology.
Towards Data-centric Graph Machine Learning: Review and Outlook
Sep 20, 2023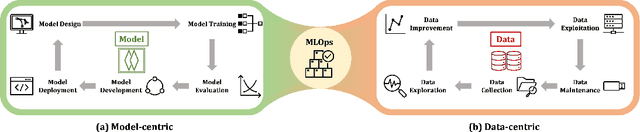
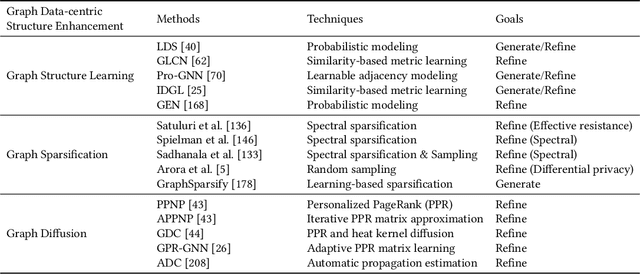
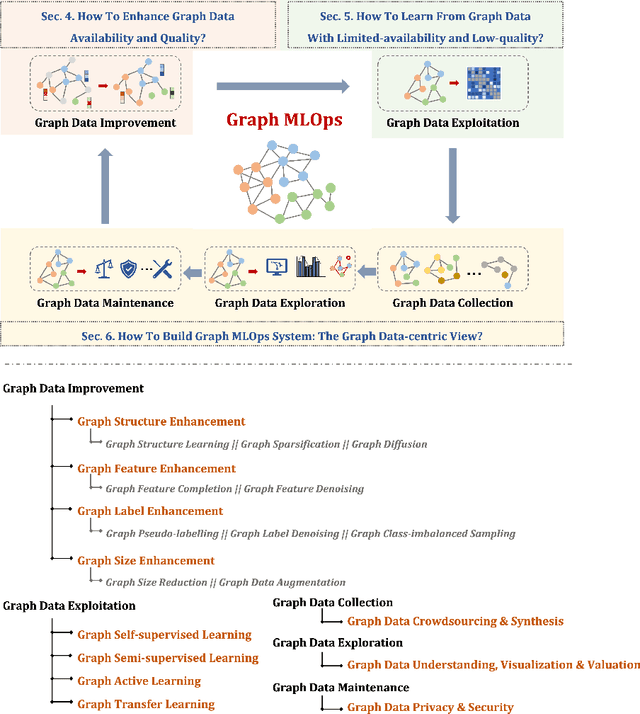
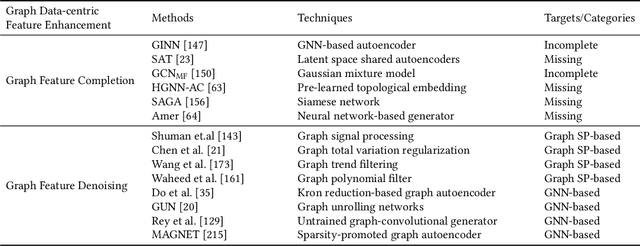
Data-centric AI, with its primary focus on the collection, management, and utilization of data to drive AI models and applications, has attracted increasing attention in recent years. In this article, we conduct an in-depth and comprehensive review, offering a forward-looking outlook on the current efforts in data-centric AI pertaining to graph data-the fundamental data structure for representing and capturing intricate dependencies among massive and diverse real-life entities. We introduce a systematic framework, Data-centric Graph Machine Learning (DC-GML), that encompasses all stages of the graph data lifecycle, including graph data collection, exploration, improvement, exploitation, and maintenance. A thorough taxonomy of each stage is presented to answer three critical graph-centric questions: (1) how to enhance graph data availability and quality; (2) how to learn from graph data with limited-availability and low-quality; (3) how to build graph MLOps systems from the graph data-centric view. Lastly, we pinpoint the future prospects of the DC-GML domain, providing insights to navigate its advancements and applications.
Points-of-Interest Relationship Inference with Spatial-enriched Graph Neural Networks
Feb 28, 2022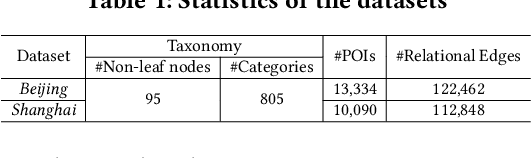
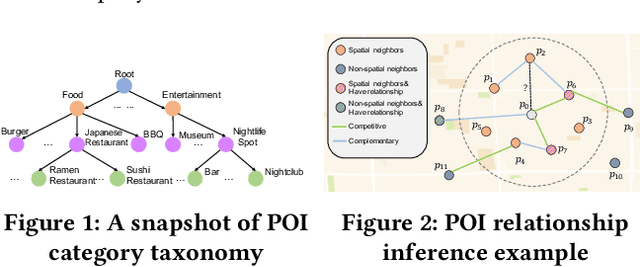
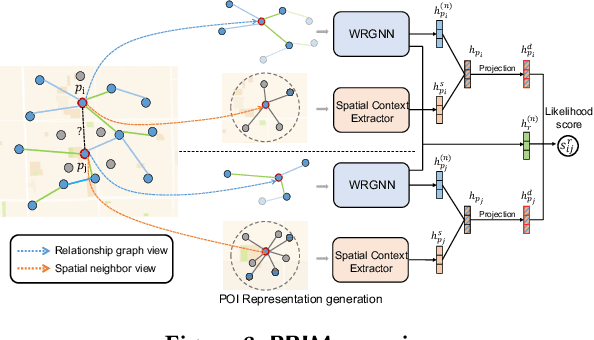
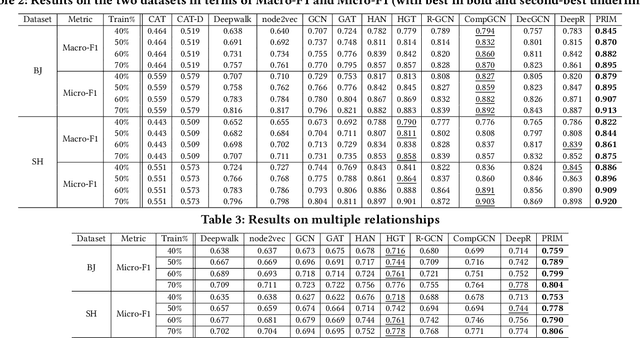
As a fundamental component in location-based services, inferring the relationship between points-of-interests (POIs) is very critical for service providers to offer good user experience to business owners and customers. Most of the existing methods for relationship inference are not targeted at POI, thus failing to capture unique spatial characteristics that have huge effects on POI relationships. In this work we propose PRIM to tackle POI relationship inference for multiple relation types. PRIM features four novel components, including a weighted relational graph neural network, category taxonomy integration, a self-attentive spatial context extractor, and a distance-specific scoring function. Extensive experiments on two real-world datasets show that PRIM achieves the best results compared to state-of-the-art baselines and it is robust against data sparsity and is applicable to unseen cases in practice.
Spatial Object Recommendation with Hints: When Spatial Granularity Matters
Jan 08, 2021

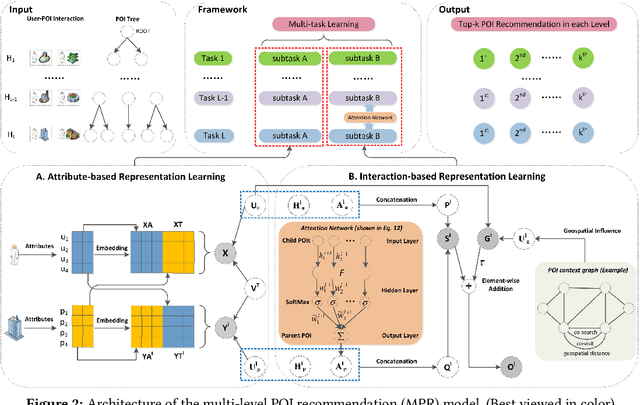

Existing spatial object recommendation algorithms generally treat objects identically when ranking them. However, spatial objects often cover different levels of spatial granularity and thereby are heterogeneous. For example, one user may prefer to be recommended a region (say Manhattan), while another user might prefer a venue (say a restaurant). Even for the same user, preferences can change at different stages of data exploration. In this paper, we study how to support top-k spatial object recommendations at varying levels of spatial granularity, enabling spatial objects at varying granularity, such as a city, suburb, or building, as a Point of Interest (POI). To solve this problem, we propose the use of a POI tree, which captures spatial containment relationships between POIs. We design a novel multi-task learning model called MPR (short for Multi-level POI Recommendation), where each task aims to return the top-k POIs at a certain spatial granularity level. Each task consists of two subtasks: (i) attribute-based representation learning; (ii) interaction-based representation learning. The first subtask learns the feature representations for both users and POIs, capturing attributes directly from their profiles. The second subtask incorporates user-POI interactions into the model. Additionally, MPR can provide insights into why certain recommendations are being made to a user based on three types of hints: user-aspect, POI-aspect, and interaction-aspect. We empirically validate our approach using two real-life datasets, and show promising performance improvements over several state-of-the-art methods.