 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuEqNet: Dual-Equivariance Network in Outdoor 3D Object Detection for Autonomous Driving
Feb 27, 2023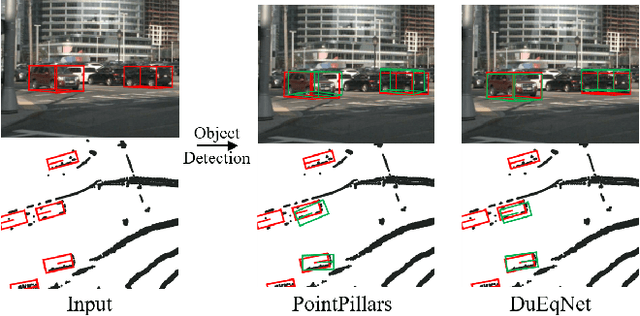
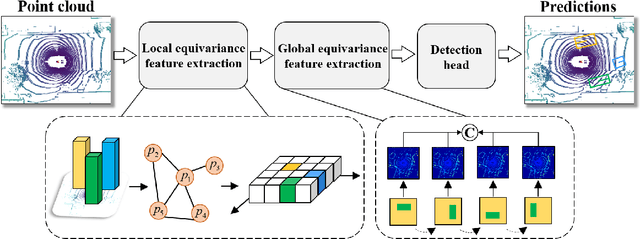
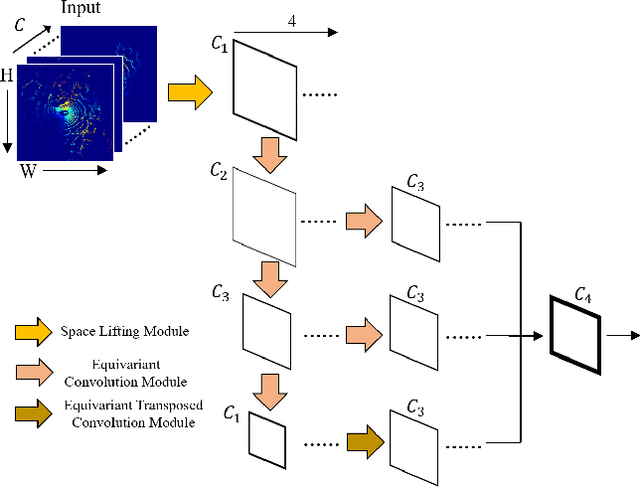
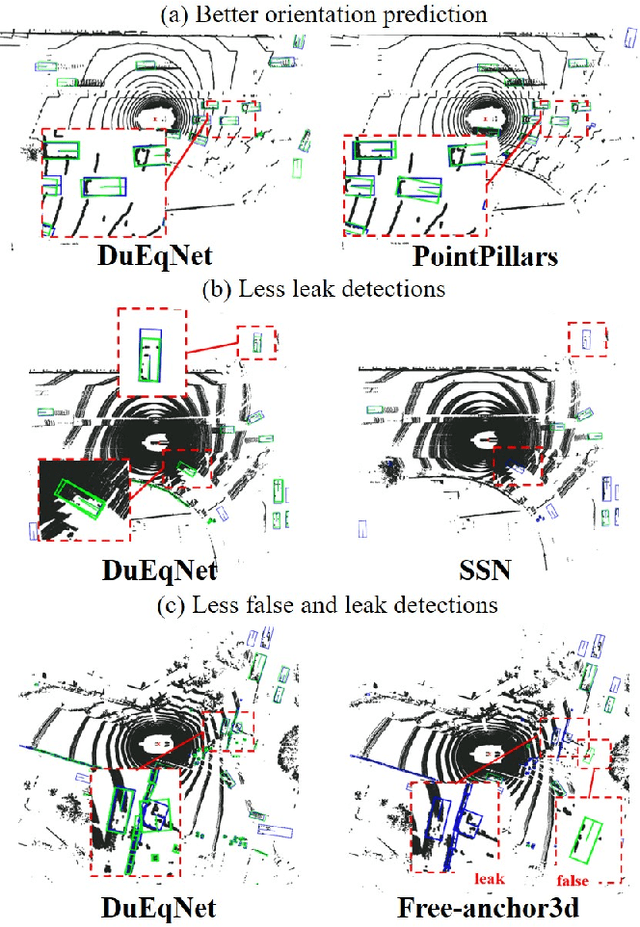
Outdoor 3D object detection has played an essential role in the environment perception of autonomous driving. In complicated traffic situations, precise object recognition provides indispensable information for prediction and planning in the dynamic system, improving self-driving safety and reliability. However, with the vehicle's veering, the constant rotation of the surrounding scenario makes a challenge for the perception systems. Yet most existing methods have not focused on alleviating the detection accuracy impairment brought by the vehicle's rotation, especially in outdoor 3D detection. In this paper, we propose DuEqNet, which first introduces the concept of equivariance into 3D object detection network by leveraging a hierarchical embedded framework. The dual-equivariance of our model can extract the equivariant features at both local and global levels, respectively. For the local feature, we utilize the graph-based strategy to guarantee the equivariance of the feature in point cloud pillars. In terms of the global feature, the group equivariant convolution layers are adopted to aggregate the local feature to achieve the global equivariance. In the experiment part, we evaluate our approach with different baselines in 3D object detection tasks and obtain State-Of-The-Art performance. According to the results, our model presents higher accuracy on orientation and better prediction efficiency. Moreover, our dual-equivariance strategy exhibits the satisfied plug-and-play ability on various popular object detection frameworks to improve their performance.
Synthesizing Tensor Transformations for Visual Self-attention
Jan 05, 2022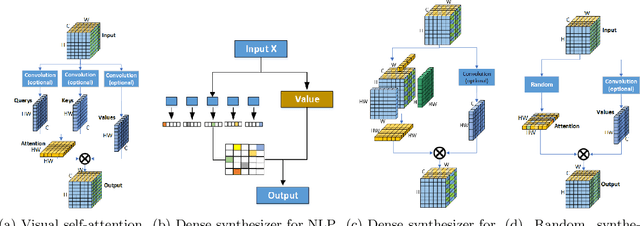
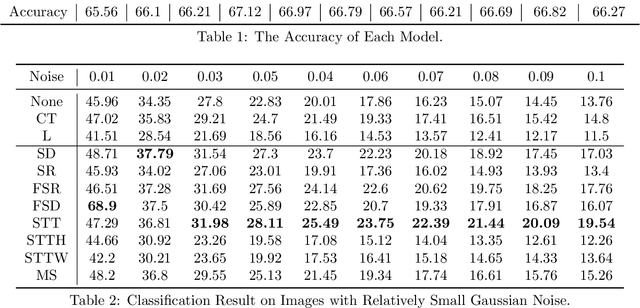
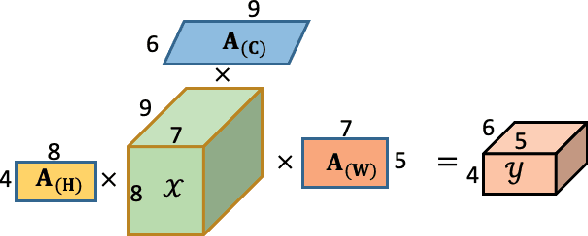
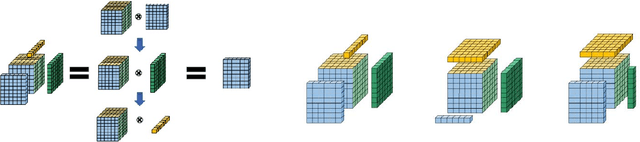
Self-attention shows outstanding competence in capturing long-range relationships while enhancing performance on vision tasks, such as image classification and image captioning. However, the self-attention module highly relies on the dot product multiplication and dimension alignment among query-key-value features, which cause two problems: (1) The dot product multiplication results in exhaustive and redundant computation. (2) Due to the visual feature map often appearing as a multi-dimensional tensor, reshaping the scale of the tensor feature to adapt to the dimension alignment might destroy the internal structure of the tensor feature map. To address these problems, this paper proposes a self-attention plug-in module with its variants, namely, Synthesizing Tensor Transformations (STT), for directly processing image tensor features. Without computing the dot-product multiplication among query-key-value, the basic STT is composed of the tensor transformation to learn the synthetic attention weight from visual information. The effectiveness of STT series is validated on the image classification and image caption. Experiments show that the proposed STT achieves competitive performance while keeping robustness compared to self-attention based above vision tasks.
ViR:the Vision Reservoir
Dec 29, 2021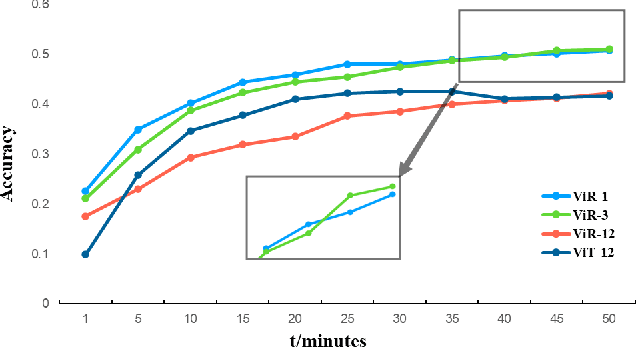
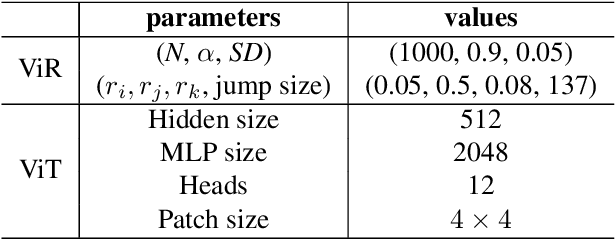

The most recent year has witnessed the success of applying the Vision Transformer (ViT) for image classification. However, there are still evidences indicating that ViT often suffers following two aspects, i) the high computation and the memory burden from applying the multiple Transformer layers for pre-training on a large-scale dataset, ii) the over-fitting when training on small datasets from scratch. To address these problems, a novel method, namely, Vision Reservoir computing (ViR), is proposed here for image classification, as a parallel to ViT. By splitting each image into a sequence of tokens with fixed length, the ViR constructs a pure reservoir with a nearly fully connected topology to replace the Transformer module in ViT. Two kinds of deep ViR models are subsequently proposed to enhance the network performance. Comparative experiments between the ViR and the ViT are carried out on several image classification benchmarks. Without any pre-training process, the ViR outperforms the ViT in terms of both model and computational complexity. Specifically, the number of parameters of the ViR is about 15% even 5% of the ViT, and the memory footprint is about 20% to 40% of the ViT. The superiority of the ViR performance is explained by Small-World characteristics, Lyapunov exponents, and memory capacity.
Learning Robust and Lightweight Model through Separable Structured Transformations
Dec 29, 2021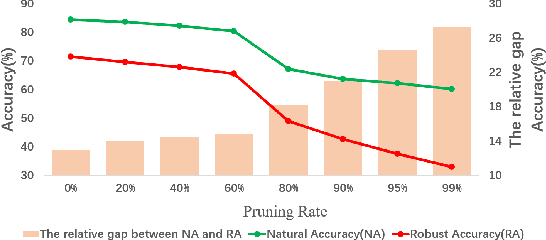

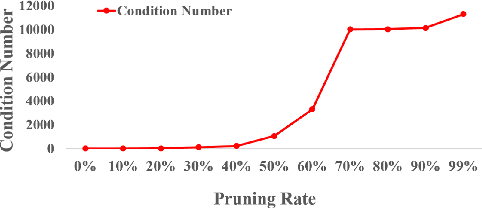
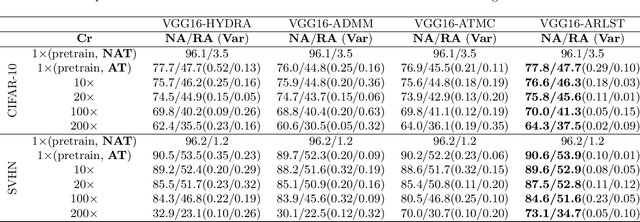
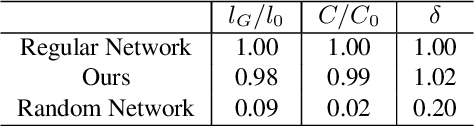
With the proliferation of mobile devices and the Internet of Things, deep learning models are increasingly deployed on devices with limited computing resources and memory, and are exposed to the threat of adversarial noise. Learning deep models with both lightweight and robustness is necessary for these equipments. However, current deep learning solutions are difficult to learn a model that possesses these two properties without degrading one or the other. As is well known, the fully-connected layers contribute most of the parameters of convolutional neural networks. We perform a separable structural transformation of the fully-connected layer to reduce the parameters, where the large-scale weight matrix of the fully-connected layer is decoupled by the tensor product of several separable small-sized matrices. Note that data, such as images, no longer need to be flattened before being fed to the fully-connected layer, retaining the valuable spatial geometric information of the data. Moreover, in order to further enhance both lightweight and robustness, we propose a joint constraint of sparsity and differentiable condition number, which is imposed on these separable matrices. We evaluate the proposed approach on MLP, VGG-16 and Vision Transformer. The experimental results on datasets such as ImageNet, SVHN, CIFAR-100 and CIFAR10 show that we successfully reduce the amount of network parameters by 90%, while the robust accuracy loss is less than 1.5%, which is better than the SOTA methods based on the original fully-connected layer. Interestingly, it can achieve an overwhelming advantage even at a high compression rate, e.g., 200 times.
Couplformer:Rethinking Vision Transformer with Coupling Attention Map
Dec 10, 2021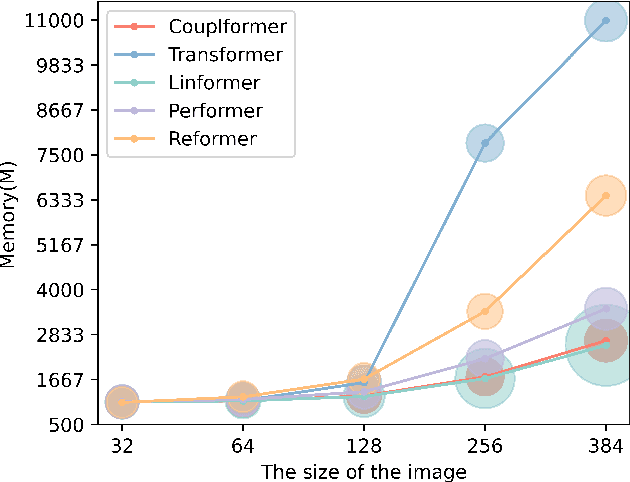

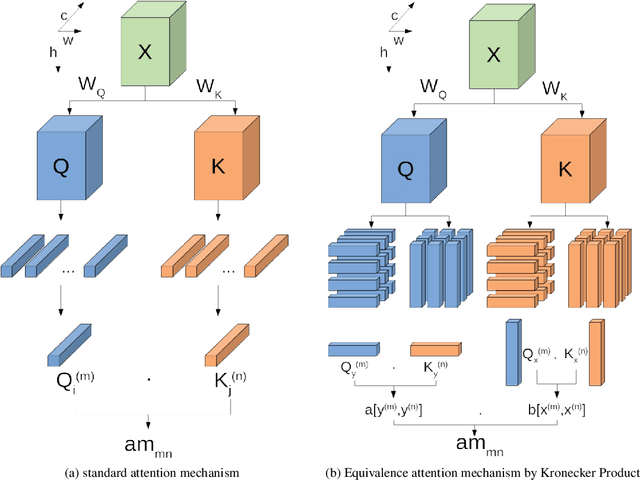
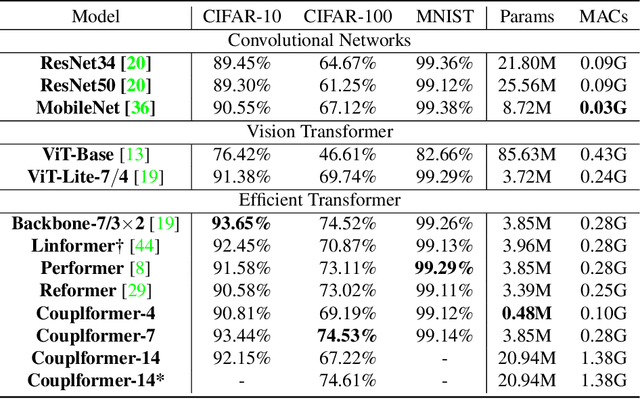
With the development of the self-attention mechanism, the Transformer model has demonstrated its outstanding performance in the computer vision domain. However, the massive computation brought from the full attention mechanism became a heavy burden for memory consumption. Sequentially, the limitation of memory reduces the possibility of improving the Transformer model. To remedy this problem, we propose a novel memory economy attention mechanism named Couplformer, which decouples the attention map into two sub-matrices and generates the alignment scores from spatial information. A series of different scale image classification tasks are applied to evaluate the effectiveness of our model. The result of experiments shows that on the ImageNet-1k classification task, the Couplformer can significantly decrease 28% memory consumption compared with regular Transformer while accessing sufficient accuracy requirements and outperforming 0.92% on Top-1 accuracy while occupying the same memory footprint. As a result, the Couplformer can serve as an efficient backbone in visual tasks, and provide a novel perspective on the attention mechanism for researchers.
A Survey on Advancing the DBMS Query Optimizer: Cardinality Estimation, Cost Model, and Plan Enumeration
Jan 05, 2021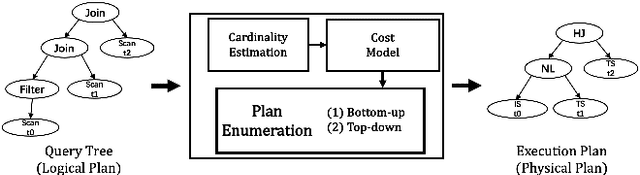
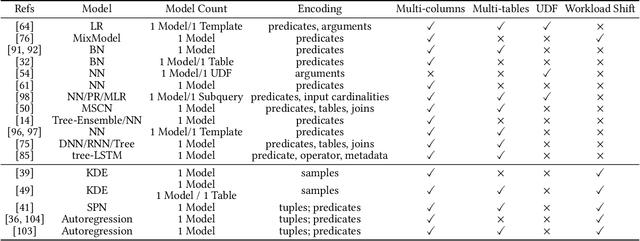
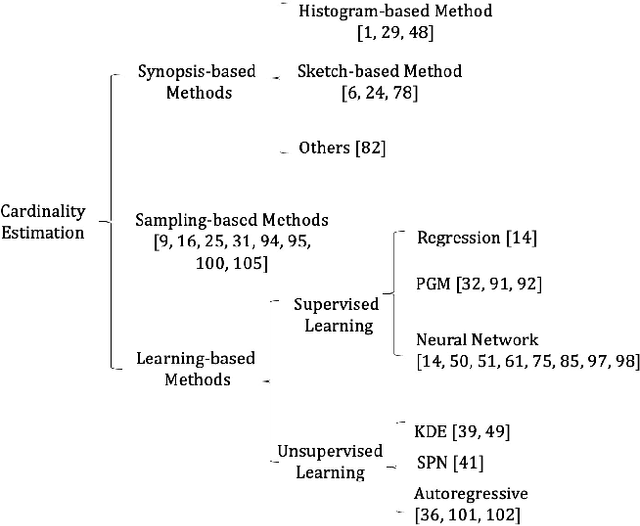

Query optimizer is at the heart of the database systems. Cost-based optimizer studied in this paper is adopted in almost all current database systems. A cost-based optimizer introduces a plan enumeration algorithm to find a (sub)plan, and then uses a cost model to obtain the cost of that plan, and selects the plan with the lowest cost. In the cost model, cardinality, the number of tuples through an operator, plays a crucial role. Due to the inaccuracy in cardinality estimation, errors in cost model, and the huge plan space, the optimizer cannot find the optimal execution plan for a complex query in a reasonable time. In this paper, we first deeply study the causes behind the limitations above. Next, we review the techniques used to improve the quality of the three key components in the cost-based optimizer, cardinality estimation, cost model, and plan enumeration. We also provide our insights on the future directions for each of the above aspects.