 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Tensor Transformations for Visual Self-attention
Jan 05, 2022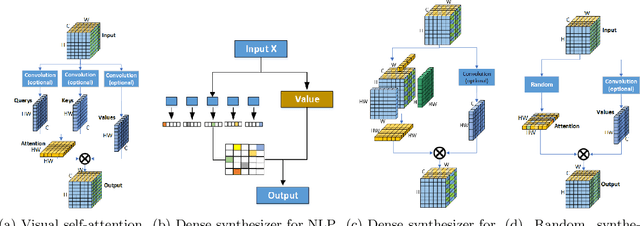
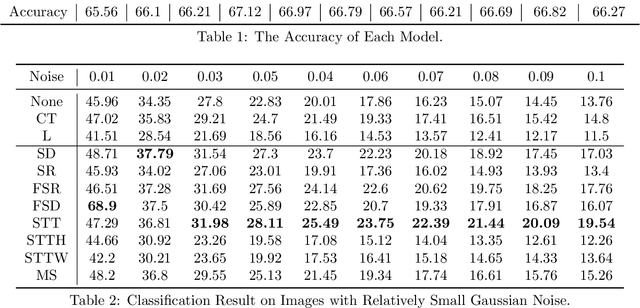
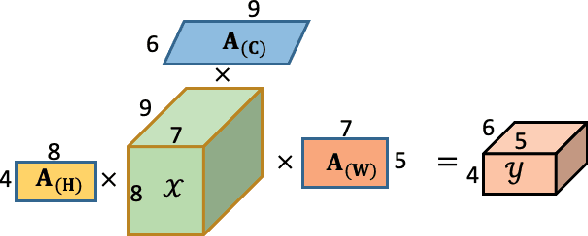
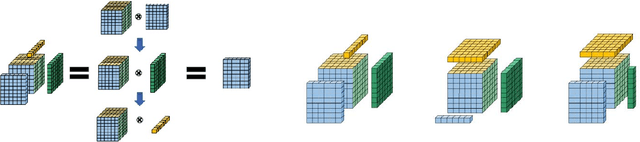
Self-attention shows outstanding competence in capturing long-range relationships while enhancing performance on vision tasks, such as image classification and image captioning. However, the self-attention module highly relies on the dot product multiplication and dimension alignment among query-key-value features, which cause two problems: (1) The dot product multiplication results in exhaustive and redundant computation. (2) Due to the visual feature map often appearing as a multi-dimensional tensor, reshaping the scale of the tensor feature to adapt to the dimension alignment might destroy the internal structure of the tensor feature map. To address these problems, this paper proposes a self-attention plug-in module with its variants, namely, Synthesizing Tensor Transformations (STT), for directly processing image tensor features. Without computing the dot-product multiplication among query-key-value, the basic STT is composed of the tensor transformation to learn the synthetic attention weight from visual information. The effectiveness of STT series is validated on the image classification and image caption. Experiments show that the proposed STT achieves competitive performance while keeping robustness compared to self-attention based above vision tasks.