 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
Label What Matters: Modality-Balanced and Difficulty-Aware Multimodal Active Learning
Mar 26, 2026Multimodal learning integrates complementary information from different modalities such as image, text, and audio to improve model performance, but its success relies on large-scale labeled data, which is costly to obtain. Active learning (AL) mitigates this challenge by selectively annotating informative samples. In multimodal settings, many approaches implicitly assume that modality importance is stable across rounds and keep selection rules fixed at the fusion stage, which leaves them insensitive to the dynamic nature of multimodal learning, where the relative value of modalities and the difficulty of instances shift as training proceeds. To address this issue, we propose RL-MBA, a reinforcement-learning framework for modality-balanced, difficulty-aware multimodal active learning. RL-MBA models sample selection as a Markov Decision Process, where the policy adapts to modality contributions, uncertainty, and diversity, and the reward encourages accuracy gains and balance. Two key components drive this adaptability: (1) Adaptive Modality Contribution Balancing (AMCB), which dynamically adjusts modality weights via reinforcement feedback, and (2) Evidential Fusion for DifficultyAware Policy Adjustment (EFDA), which estimates sample difficulty via uncertainty-based evidential fusion to prioritize informative samples. Experiments on Food101, KineticsSound, and VGGSound demonstrate that RL-MBA consistently outperforms strong baselines, improving both classification accuracy and modality fairness under limited labeling budgets.
SelfieAvatar: Real-time Head Avatar reenactment from a Selfie Video
Jan 26, 2026Head avatar reenactment focuses on creating animatable personal avatars from monocular videos, serving as a foundational element for applications like social signal understanding, gaming, human-machine interaction, and computer vision. Recent advances in 3D Morphable Model (3DMM)-based facial reconstruction methods have achieved remarkable high-fidelity face estimation. However, on the one hand, they struggle to capture the entire head, including non-facial regions and background details in real time, which is an essential aspect for producing realistic, high-fidelity head avatars. On the other hand, recent approaches leveraging generative adversarial networks (GANs) for head avatar generation from videos can achieve high-quality reenactments but encounter limitations in reproducing fine-grained head details, such as wrinkles and hair textures. In addition, existing methods generally rely on a large amount of training data, and rarely focus on using only a simple selfie video to achieve avatar reenactment. To address these challenges, this study introduces a method for detailed head avatar reenactment using a selfie video. The approach combines 3DMMs with a StyleGAN-based generator. A detailed reconstruction model is proposed, incorporating mixed loss functions for foreground reconstruction and avatar image generation during adversarial training to recover high-frequency details. Qualitative and quantitative evaluations on self-reenactment and cross-reenactment tasks demonstrate that the proposed method achieves superior head avatar reconstruction with rich and intricate textures compared to existing approaches.
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
CAG-Avatar: Cross-Attention Guided Gaussian Avatars for High-Fidelity Head Reconstruction
Jan 21, 2026Creating high-fidelity, real-time drivable 3D head avatars is a core challenge in digital animation. While 3D Gaussian Splashing (3D-GS) offers unprecedented rendering speed and quality, current animation techniques often rely on a "one-size-fits-all" global tuning approach, where all Gaussian primitives are uniformly driven by a single expression code. This simplistic approach fails to unravel the distinct dynamics of different facial regions, such as deformable skin versus rigid teeth, leading to significant blurring and distortion artifacts. We introduce Conditionally-Adaptive Gaussian Avatars (CAG-Avatar), a framework that resolves this key limitation. At its core is a Conditionally Adaptive Fusion Module built on cross-attention. This mechanism empowers each 3D Gaussian to act as a query, adaptively extracting relevant driving signals from the global expression code based on its canonical position. This "tailor-made" conditioning strategy drastically enhances the modeling of fine-grained, localized dynamics. Our experiments confirm a significant improvement in reconstruction fidelity, particularly for challenging regions such as teeth, while preserving real-time rendering performance.
GAT-NeRF: Geometry-Aware-Transformer Enhanced Neural Radiance Fields for High-Fidelity 4D Facial Avatars
Jan 21, 2026High-fidelity 4D dynamic facial avatar reconstruction from monocular video is a critical yet challenging task, driven by increasing demands for immersive virtual human applications. While Neural Radiance Fields (NeRF) have advanced scene representation, their capacity to capture high-frequency facial details, such as dynamic wrinkles and subtle textures from information-constrained monocular streams, requires significant enhancement. To tackle this challenge, we propose a novel hybrid neural radiance field framework, called Geometry-Aware-Transformer Enhanced NeRF (GAT-NeRF) for high-fidelity and controllable 4D facial avatar reconstruction, which integrates the Transformer mechanism into the NeRF pipeline. GAT-NeRF synergistically combines a coordinate-aligned Multilayer Perceptron (MLP) with a lightweight Transformer module, termed as Geometry-Aware-Transformer (GAT) due to its processing of multi-modal inputs containing explicit geometric priors. The GAT module is enabled by fusing multi-modal input features, including 3D spatial coordinates, 3D Morphable Model (3DMM) expression parameters, and learnable latent codes to effectively learn and enhance feature representations pertinent to fine-grained geometry. The Transformer's effective feature learning capabilities are leveraged to significantly augment the modeling of complex local facial patterns like dynamic wrinkles and acne scars. Comprehensive experiments unequivocally demonstrate GAT-NeRF's state-of-the-art performance in visual fidelity and high-frequency detail recovery, forging new pathways for creating realistic dynamic digital humans for multimedia applications.
READ-Net: Clarifying Emotional Ambiguity via Adaptive Feature Recalibration for Audio-Visual Depression Detection
Jan 21, 2026Depression is a severe global mental health issue that impairs daily functioning and overall quality of life. Although recent audio-visual approaches have improved automatic depression detection, methods that ignore emotional cues often fail to capture subtle depressive signals hidden within emotional expressions. Conversely, those incorporating emotions frequently confuse transient emotional expressions with stable depressive symptoms in feature representations, a phenomenon termed \emph{Emotional Ambiguity}, thereby leading to detection errors. To address this critical issue, we propose READ-Net, the first audio-visual depression detection framework explicitly designed to resolve Emotional Ambiguity through Adaptive Feature Recalibration (AFR). The core insight of AFR is to dynamically adjust the weights of emotional features to enhance depression-related signals. Rather than merely overlooking or naively combining emotional information, READ-Net innovatively identifies and preserves depressive-relevant cues within emotional features, while adaptively filtering out irrelevant emotional noise. This recalibration strategy significantly clarifies feature representations, and effectively mitigates the persistent challenge of emotional interference. Additionally, READ-Net can be easily integrated into existing frameworks for improved performance. Extensive evaluations on three publicly available datasets show that READ-Net outperforms state-of-the-art methods, with average gains of 4.55\% in accuracy and 1.26\% in F1-score, demonstrating its robustness to emotional disturbances and improving audio-visual depression detection.
Semantic-Guided Unsupervised Video Summarization
Jan 21, 2026Video summarization is a crucial technique for social understanding, enabling efficient browsing of massive multimedia content and extraction of key information from social platforms. Most existing unsupervised summarization methods rely on Generative Adversarial Networks (GANs) to enhance keyframe selection and generate coherent, video summaries through adversarial training. However, such approaches primarily exploit unimodal features, overlooking the guiding role of semantic information in keyframe selection, and often suffer from unstable training. To address these limitations, we propose a novel Semantic-Guided Unsupervised Video Summarization method. Specifically, we design a novel frame-level semantic alignment attention mechanism and integrate it into a keyframe selector, which guides the Transformer-based generator within the adversarial framework to better reconstruct videos. In addition, we adopt an incremental training strategy to progressively update the model components, effectively mitigating the instability of GAN training. Experimental results demonstrate that our approach achieves superior performance on multiple benchmark datasets.
Double Banking on Knowledge: Customized Modulation and Prototypes for Multi-Modality Semi-supervised Medical Image Segmentation
Oct 23, 2024



Multi-modality (MM) semi-supervised learning (SSL) based medical image segmentation has recently gained increasing attention for its ability to utilize MM data and reduce reliance on labeled images. However, current methods face several challenges: (1) Complex network designs hinder scalability to scenarios with more than two modalities. (2) Focusing solely on modality-invariant representation while neglecting modality-specific features, leads to incomplete MM learning. (3) Leveraging unlabeled data with generative methods can be unreliable for SSL. To address these problems, we propose Double Bank Dual Consistency (DBDC), a novel MM-SSL approach for medical image segmentation. To address challenge (1), we propose a modality all-in-one segmentation network that accommodates data from any number of modalities, removing the limitation on modality count. To address challenge (2), we design two learnable plug-in banks, Modality-Level Modulation bank (MLMB) and Modality-Level Prototype (MLPB) bank, to capture both modality-invariant and modality-specific knowledge. These banks are updated using our proposed Modality Prototype Contrastive Learning (MPCL). Additionally, we design Modality Adaptive Weighting (MAW) to dynamically adjust learning weights for each modality, ensuring balanced MM learning as different modalities learn at different rates. Finally, to address challenge (3), we introduce a Dual Consistency (DC) strategy that enforces consistency at both the image and feature levels without relying on generative methods. We evaluate our method on a 2-to-4 modality segmentation task using three open-source datasets, and extensive experiments show that our method outperforms state-of-the-art approaches.
UWStereo: A Large Synthetic Dataset for Underwater Stereo Matching
Sep 03, 2024
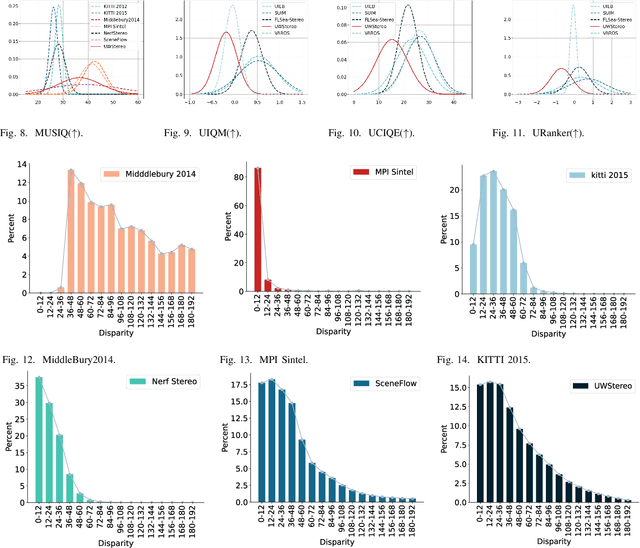

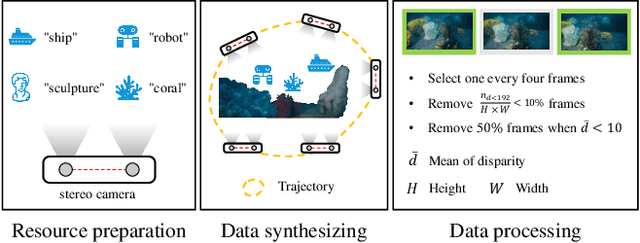
Despite recent advances in stereo matching, the extension to intricate underwater settings remains unexplored, primarily owing to: 1) the reduced visibility, low contrast, and other adverse effects of underwater images; 2) the difficulty in obtaining ground truth data for training deep learning models, i.e. simultaneously capturing an image and estimating its corresponding pixel-wise depth information in underwater environments. To enable further advance in underwater stereo matching, we introduce a large synthetic dataset called UWStereo. Our dataset includes 29,568 synthetic stereo image pairs with dense and accurate disparity annotations for left view. We design four distinct underwater scenes filled with diverse objects such as corals, ships and robots. We also induce additional variations in camera model, lighting, and environmental effects. In comparison with existing underwater datasets, UWStereo is superior in terms of scale, variation, annotation, and photo-realistic image quality. To substantiate the efficacy of the UWStereo dataset, we undertake a comprehensive evaluation compared with nine state-of-the-art algorithms as benchmarks. The results indicate that current models still struggle to generalize to new domains. Hence, we design a new strategy that learns to reconstruct cross domain masked images before stereo matching training and integrate a cross view attention enhancement module that aggregates long-range content information to enhance the generalization ability.