 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDRNet: Large Deformation Registration Model for Chest CT Registration
Feb 02, 2026Most of the deep learning based medical image registration algorithms focus on brain image registration tasks.Compared with brain registration, the chest CT registration has larger deformation, more complex background and region over-lap. In this paper, we propose a fast unsupervised deep learning method, LDRNet, for large deformation image registration of chest CT images. We first predict a coarse resolution registration field, then refine it from coarse to fine. We propose two innovative technical components: 1) a refine block that is used to refine the registration field in different resolutions, 2) a rigid block that is used to learn transformation matrix from high-level features. We train and evaluate our model on the private dataset and public dataset SegTHOR. We compare our performance with state-of-the-art traditional registration methods as well as deep learning registration models VoxelMorph, RCN, and LapIRN. The results demonstrate that our model achieves state-of-the-art performance for large deformation images registration and is much faster.
Off-Policy Actor-Critic with Sigmoid-Bounded Entropy for Real-World Robot Learning
Jan 22, 2026Deploying reinforcement learning in the real world remains challenging due to sample inefficiency, sparse rewards, and noisy visual observations. Prior work leverages demonstrations and human feedback to improve learning efficiency and robustness. However, offline-to-online methods need large datasets and can be unstable, while VLA-assisted RL relies on large-scale pretraining and fine-tuning. As a result, a low-cost real-world RL method with minimal data requirements has yet to emerge. We introduce \textbf{SigEnt-SAC}, an off-policy actor-critic method that learns from scratch using a single expert trajectory. Our key design is a sigmoid-bounded entropy term that prevents negative-entropy-driven optimization toward out-of-distribution actions and reduces Q-function oscillations. We benchmark SigEnt-SAC on D4RL tasks against representative baselines. Experiments show that SigEnt-SAC substantially alleviates Q-function oscillations and reaches a 100\% success rate faster than prior methods. Finally, we validate SigEnt-SAC on four real-world robotic tasks across multiple embodiments, where agents learn from raw images and sparse rewards; results demonstrate that SigEnt-SAC can learn successful policies with only a small number of real-world interactions, suggesting a low-cost and practical pathway for real-world RL deployment.
EchoFoley: Event-Centric Hierarchical Control for Video Grounded Creative Sound Generation
Dec 31, 2025Sound effects build an essential layer of multimodal storytelling, shaping the emotional atmosphere and the narrative semantics of videos. Despite recent advancement in video-text-to-audio (VT2A), the current formulation faces three key limitations: First, an imbalance between visual and textual conditioning that leads to visual dominance; Second, the absence of a concrete definition for fine-grained controllable generation; Third, weak instruction understanding and following, as existing datasets rely on brief categorical tags. To address these limitations, we introduce EchoFoley, a new task designed for video-grounded sound generation with both event level local control and hierarchical semantic control. Our symbolic representation for sounding events specifies when, what, and how each sound is produced within a video or instruction, enabling fine-grained controls like sound generation, insertion, and editing. To support this task, we construct EchoFoley-6k, a large-scale, expert-curated benchmark containing over 6,000 video-instruction-annotation triplets. Building upon this foundation, we propose EchoVidia a sounding-event-centric agentic generation framework with slow-fast thinking strategy. Experiments show that EchoVidia surpasses recent VT2A models by 40.7% in controllability and 12.5% in perceptual quality.
Research on Evaluation Methods for Patent Novelty Search Systems and Empirical Analysis
Aug 25, 2025Patent novelty search systems are critical to IP protection and innovation assessment; their retrieval accuracy directly impacts patent quality. We propose a comprehensive evaluation methodology that builds high-quality, reproducible datasets from examiner citations and X-type citations extracted from technically consistent family patents, and evaluates systems using invention descriptions as inputs. Using Top-k Detection Rate and Recall as core metrics, we further conduct multi-dimensional analyses by language, technical field (IPC), and filing jurisdiction. Experiments show the method effectively exposes performance differences across scenarios and offers actionable evidence for system improvement. The framework is scalable and practical, providing a useful reference for development and optimization of patent novelty search systems
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
Long Term Memory: The Foundation of AI Self-Evolution
Oct 21, 2024



Large language models (LLMs) like GPTs, trained on vast datasets, have demonstrated impressive capabilities in language understanding, reasoning, and planning, achieving human-level performance in various tasks. Most studies focus on enhancing these models by training on ever-larger datasets to build more powerful foundation models. While training stronger models is important, enabling models to evolve during inference is equally crucial, a process we refer to as AI self-evolution. Unlike large-scale training, self-evolution may rely on limited data or interactions. Inspired by the columnar organization of the human cerebral cortex, we hypothesize that AI models could develop cognitive abilities and build internal representations through iterative interactions with their environment. To achieve this, models need long-term memory (LTM) to store and manage processed interaction data. LTM supports self-evolution by representing diverse experiences across environments and agents. In this report, we explore AI self-evolution and its potential to enhance models during inference. We examine LTM's role in lifelong learning, allowing models to evolve based on accumulated interactions. We outline the structure of LTM and the systems needed for effective data retention and representation. We also classify approaches for building personalized models with LTM data and show how these models achieve self-evolution through interaction. Using LTM, our multi-agent framework OMNE achieved first place on the GAIA benchmark, demonstrating LTM's potential for AI self-evolution. Finally, we present a roadmap for future research, emphasizing the importance of LTM for advancing AI technology and its practical applications.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024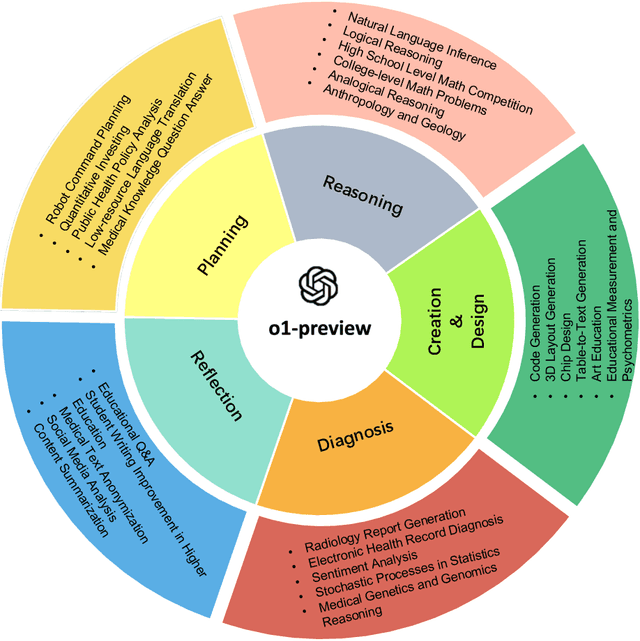


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
HARP: Human-Assisted Regrouping with Permutation Invariant Critic for Multi-Agent Reinforcement Learning
Sep 18, 2024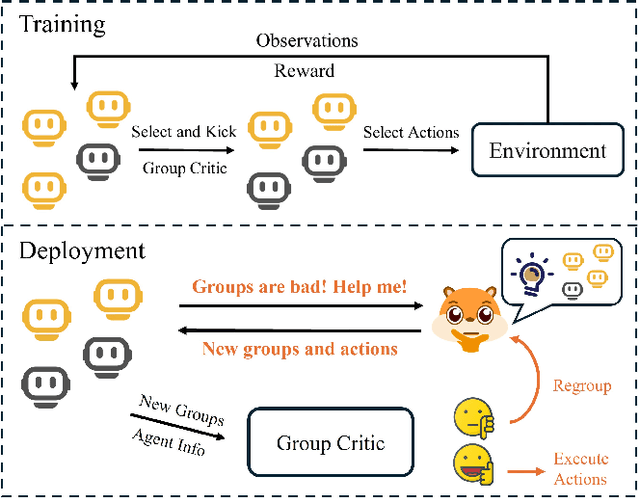
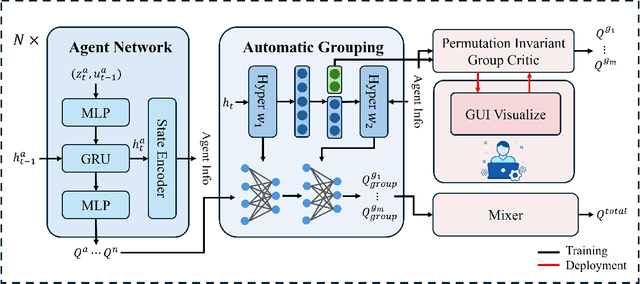
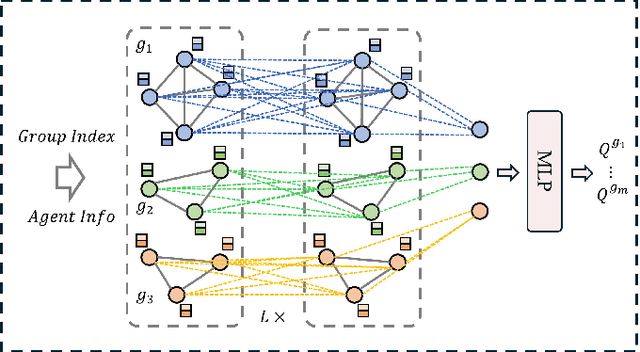

Human-in-the-loop reinforcement learning integrates human expertise to accelerate agent learning and provide critical guidance and feedback in complex fields. However, many existing approaches focus on single-agent tasks and require continuous human involvement during the training process, significantly increasing the human workload and limiting scalability. In this paper, we propose HARP (Human-Assisted Regrouping with Permutation Invariant Critic), a multi-agent reinforcement learning framework designed for group-oriented tasks. HARP integrates automatic agent regrouping with strategic human assistance during deployment, enabling and allowing non-experts to offer effective guidance with minimal intervention. During training, agents dynamically adjust their groupings to optimize collaborative task completion. When deployed, they actively seek human assistance and utilize the Permutation Invariant Group Critic to evaluate and refine human-proposed groupings, allowing non-expert users to contribute valuable suggestions. In multiple collaboration scenarios, our approach is able to leverage limited guidance from non-experts and enhance performance. The project can be found at https://github.com/huawen-hu/HARP.
Identifying Influential nodes in Brain Networks via Self-Supervised Graph-Transformer
Sep 17, 2024


Studying influential nodes (I-nodes) in brain networks is of great significance in the field of brain imaging. Most existing studies consider brain connectivity hubs as I-nodes. However, this approach relies heavily on prior knowledge from graph theory, which may overlook the intrinsic characteristics of the brain network, especially when its architecture is not fully understood. In contrast, self-supervised deep learning can learn meaningful representations directly from the data. This approach enables the exploration of I-nodes for brain networks, which is also lacking in current studies. This paper proposes a Self-Supervised Graph Reconstruction framework based on Graph-Transformer (SSGR-GT) to identify I-nodes, which has three main characteristics. First, as a self-supervised model, SSGR-GT extracts the importance of brain nodes to the reconstruction. Second, SSGR-GT uses Graph-Transformer, which is well-suited for extracting features from brain graphs, combining both local and global characteristics. Third, multimodal analysis of I-nodes uses graph-based fusion technology, combining functional and structural brain information. The I-nodes we obtained are distributed in critical areas such as the superior frontal lobe, lateral parietal lobe, and lateral occipital lobe, with a total of 56 identified across different experiments. These I-nodes are involved in more brain networks than other regions, have longer fiber connections, and occupy more central positions in structural connectivity. They also exhibit strong connectivity and high node efficiency in both functional and structural networks. Furthermore, there is a significant overlap between the I-nodes and both the structural and functional rich-club. These findings enhance our understanding of the I-nodes within the brain network, and provide new insights for future research in further understanding the brain working mechanisms.
UWStereo: A Large Synthetic Dataset for Underwater Stereo Matching
Sep 03, 2024
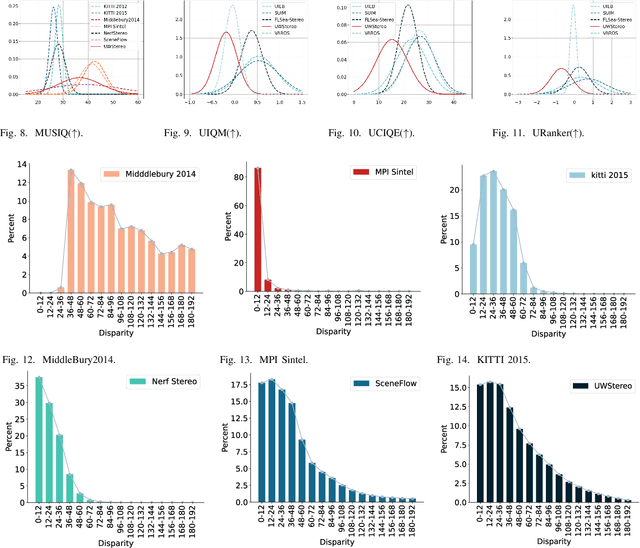

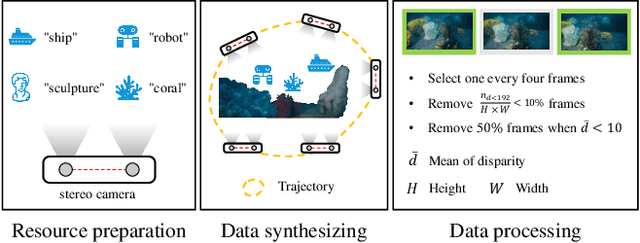
Despite recent advances in stereo matching, the extension to intricate underwater settings remains unexplored, primarily owing to: 1) the reduced visibility, low contrast, and other adverse effects of underwater images; 2) the difficulty in obtaining ground truth data for training deep learning models, i.e. simultaneously capturing an image and estimating its corresponding pixel-wise depth information in underwater environments. To enable further advance in underwater stereo matching, we introduce a large synthetic dataset called UWStereo. Our dataset includes 29,568 synthetic stereo image pairs with dense and accurate disparity annotations for left view. We design four distinct underwater scenes filled with diverse objects such as corals, ships and robots. We also induce additional variations in camera model, lighting, and environmental effects. In comparison with existing underwater datasets, UWStereo is superior in terms of scale, variation, annotation, and photo-realistic image quality. To substantiate the efficacy of the UWStereo dataset, we undertake a comprehensive evaluation compared with nine state-of-the-art algorithms as benchmarks. The results indicate that current models still struggle to generalize to new domains. Hence, we design a new strategy that learns to reconstruct cross domain masked images before stereo matching training and integrate a cross view attention enhancement module that aggregates long-range content information to enhance the generalization ability.