 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Aug 26, 2025Existing tasks fall short in evaluating reasoning ability of Large Language Models (LLMs) in an interactive, unknown environment. This deficiency leads to the isolated assessment of deductive, inductive, and abductive reasoning, neglecting the integrated reasoning process that is indispensable for humans discovery of real world. We introduce a novel evaluation paradigm, \textit{black-box interaction}, to tackle this challenge. A black-box is defined by a hidden function that maps a specific set of inputs to outputs. LLMs are required to unravel the hidden function behind the black-box by interacting with it in given exploration turns, and reasoning over observed input-output pairs. Leveraging this idea, we build the \textsc{Oracle} benchmark which comprises 6 types of black-box task and 96 black-boxes. 19 modern LLMs are benchmarked. o3 ranks first in 5 of the 6 tasks, achieving over 70\% accuracy on most easy black-boxes. But it still struggles with some hard black-box tasks, where its average performance drops below 40\%. Further analysis indicates a universal difficulty among LLMs: They lack the high-level planning capability to develop efficient and adaptive exploration strategies for hypothesis refinement.
Direct Behavior Optimization: Unlocking the Potential of Lightweight LLMs
Jun 06, 2025Lightweight Large Language Models (LwLLMs) are reduced-parameter, optimized models designed to run efficiently on consumer-grade hardware, offering significant advantages in resource efficiency, cost-effectiveness, and data privacy. However, these models often struggle with limited inference and reasoning capabilities, which restrict their performance on complex tasks and limit their practical applicability. Moreover, existing prompt optimization methods typically rely on extensive manual effort or the meta-cognitive abilities of state-of-the-art LLMs, making them less effective for LwLLMs. To address these challenges, we introduce DeBoP, a new Direct Behavior Optimization Paradigm, original from the Chain-of-Thought (CoT) prompting technique. Unlike CoT Prompting, DeBoP is an automatic optimization method, which focuses on the optimization directly on the behavior of LwLLMs. In particular, DeBoP transforms the optimization of complex prompts into the optimization of discrete, quantifiable execution sequences using a gradient-free Monte Carlo Tree Search. We evaluate DeBoP on seven challenging tasks where state-of-the-art LLMs excel but LwLLMs generally underperform. Experimental results demonstrate that DeBoP significantly outperforms recent prompt optimization methods on most tasks. In particular, DeBoP-optimized LwLLMs surpass GPT-3.5 on most tasks while reducing computational time by approximately 60% compared to other automatic prompt optimization methods.
Efficiently Achieving Secure Model Training and Secure Aggregation to Ensure Bidirectional Privacy-Preservation in Federated Learning
Dec 16, 2024
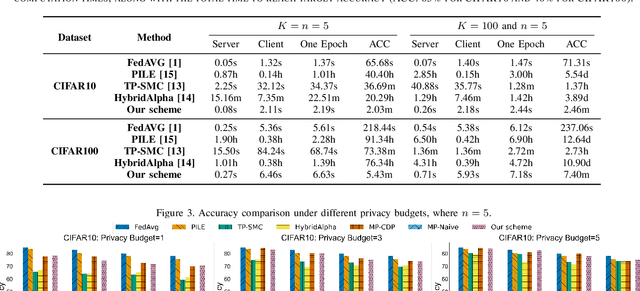
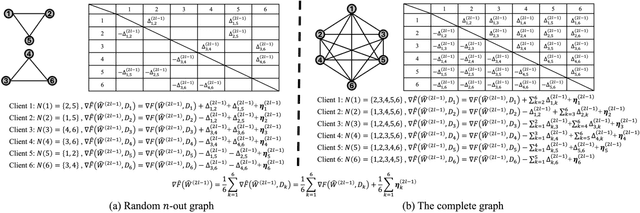

Bidirectional privacy-preservation federated learning is crucial as both local gradients and the global model may leak privacy. However, only a few works attempt to achieve it, and they often face challenges such as excessive communication and computational overheads, or significant degradation of model accuracy, which hinders their practical applications. In this paper, we design an efficient and high-accuracy bidirectional privacy-preserving scheme for federated learning to complete secure model training and secure aggregation. To efficiently achieve bidirectional privacy, we design an efficient and accuracy-lossless model perturbation method on the server side (called $\mathbf{MP\_Server}$) that can be combined with local differential privacy (LDP) to prevent clients from accessing the model, while ensuring that the local gradients obtained on the server side satisfy LDP. Furthermore, to ensure model accuracy, we customize a distributed differential privacy mechanism on the client side (called $\mathbf{DDP\_Client}$). When combined with $\mathbf{MP\_Server}$, it ensures LDP of the local gradients, while ensuring that the aggregated result matches the accuracy of central differential privacy (CDP). Extensive experiments demonstrate that our scheme significantly outperforms state-of-the-art bidirectional privacy-preservation baselines (SOTAs) in terms of computational cost, model accuracy, and defense ability against privacy attacks. Particularly, given target accuracy, the training time of SOTAs is approximately $200$ times, or even over $1000$ times, longer than that of our scheme. When the privacy budget is set relatively small, our scheme incurs less than $6\%$ accuracy loss compared to the privacy-ignoring method, while SOTAs suffer up to $20\%$ accuracy loss. Experimental results also show that the defense capability of our scheme outperforms than SOTAs.
Long Term Memory: The Foundation of AI Self-Evolution
Oct 21, 2024



Large language models (LLMs) like GPTs, trained on vast datasets, have demonstrated impressive capabilities in language understanding, reasoning, and planning, achieving human-level performance in various tasks. Most studies focus on enhancing these models by training on ever-larger datasets to build more powerful foundation models. While training stronger models is important, enabling models to evolve during inference is equally crucial, a process we refer to as AI self-evolution. Unlike large-scale training, self-evolution may rely on limited data or interactions. Inspired by the columnar organization of the human cerebral cortex, we hypothesize that AI models could develop cognitive abilities and build internal representations through iterative interactions with their environment. To achieve this, models need long-term memory (LTM) to store and manage processed interaction data. LTM supports self-evolution by representing diverse experiences across environments and agents. In this report, we explore AI self-evolution and its potential to enhance models during inference. We examine LTM's role in lifelong learning, allowing models to evolve based on accumulated interactions. We outline the structure of LTM and the systems needed for effective data retention and representation. We also classify approaches for building personalized models with LTM data and show how these models achieve self-evolution through interaction. Using LTM, our multi-agent framework OMNE achieved first place on the GAIA benchmark, demonstrating LTM's potential for AI self-evolution. Finally, we present a roadmap for future research, emphasizing the importance of LTM for advancing AI technology and its practical applications.
MDD-5k: A New Diagnostic Conversation Dataset for Mental Disorders Synthesized via Neuro-Symbolic LLM Agents
Aug 22, 2024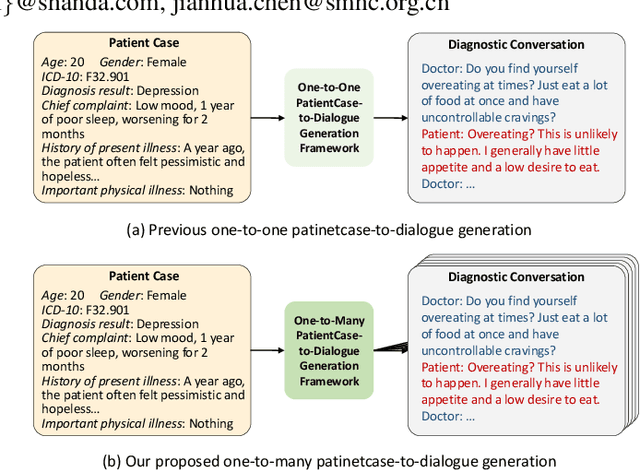

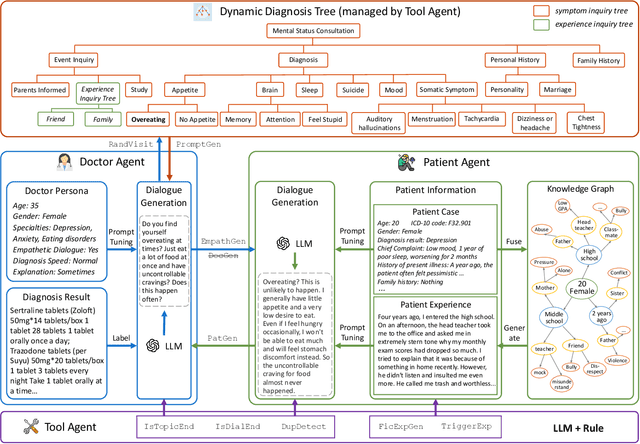

The clinical diagnosis of most mental disorders primarily relies on the conversations between psychiatrist and patient. The creation of such diagnostic conversation datasets is promising to boost the AI mental healthcare community. However, directly collecting the conversations in real diagnosis scenarios is near impossible due to stringent privacy and ethical considerations. To address this issue, we seek to synthesize diagnostic conversation by exploiting anonymous patient cases that are easier to access. Specifically, we design a neuro-symbolic multi-agent framework for synthesizing the diagnostic conversation of mental disorders with large language models. It takes patient case as input and is capable of generating multiple diverse conversations with one single patient case. The framework basically involves the interaction between a doctor agent and a patient agent, and achieves text generation under symbolic control via a dynamic diagnosis tree from a tool agent. By applying the proposed framework, we develop the largest Chinese mental disorders diagnosis dataset MDD-5k, which is built upon 1000 cleaned real patient cases by cooperating with a pioneering psychiatric hospital, and contains 5000 high-quality long conversations with diagnosis results as labels. To the best of our knowledge, it's also the first labelled Chinese mental disorders diagnosis dataset. Human evaluation demonstrates the proposed MDD-5k dataset successfully simulates human-like diagnostic process of mental disorders. The dataset and code will become publicly accessible in https://github.com/lemonsis/MDD-5k.
MLDT: Multi-Level Decomposition for Complex Long-Horizon Robotic Task Planning with Open-Source Large Language Model
Apr 02, 2024



In the realm of data-driven AI technology, the application of open-source large language models (LLMs) in robotic task planning represents a significant milestone. Recent robotic task planning methods based on open-source LLMs typically leverage vast task planning datasets to enhance models' planning abilities. While these methods show promise, they struggle with complex long-horizon tasks, which require comprehending more context and generating longer action sequences. This paper addresses this limitation by proposing MLDT, theMulti-Level Decomposition Task planning method. This method innovatively decomposes tasks at the goal-level, task-level, and action-level to mitigate the challenge of complex long-horizon tasks. In order to enhance open-source LLMs' planning abilities, we introduce a goal-sensitive corpus generation method to create high-quality training data and conduct instruction tuning on the generated corpus. Since the complexity of the existing datasets is not high enough, we construct a more challenging dataset, LongTasks, to specifically evaluate planning ability on complex long-horizon tasks. We evaluate our method using various LLMs on four datasets in VirtualHome. Our results demonstrate a significant performance enhancement in robotic task planning, showcasing MLDT's effectiveness in overcoming the limitations of existing methods based on open-source LLMs as well as its practicality in complex, real-world scenarios.
A Transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics
Jun 01, 2023During the diagnostic process, clinicians leverage multimodal information, such as chief complaints, medical images, and laboratory-test results. Deep-learning models for aiding diagnosis have yet to meet this requirement. Here we report a Transformer-based representation-learning model as a clinical diagnostic aid that processes multimodal input in a unified manner. Rather than learning modality-specific features, the model uses embedding layers to convert images and unstructured and structured text into visual tokens and text tokens, and bidirectional blocks with intramodal and intermodal attention to learn a holistic representation of radiographs, the unstructured chief complaint and clinical history, structured clinical information such as laboratory-test results and patient demographic information. The unified model outperformed an image-only model and non-unified multimodal diagnosis models in the identification of pulmonary diseases (by 12% and 9%, respectively) and in the prediction of adverse clinical outcomes in patients with COVID-19 (by 29% and 7%, respectively). Leveraging unified multimodal Transformer-based models may help streamline triage of patients and facilitate the clinical decision process.