 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Aggregation with Top-K Sparsification in Decentralized Federated Learning
Jun 09, 2026Secure aggregation is a vital component for mitigating gradient leakage in federated learning, but its communication cost conventionally scales with the gradient dimension. This becomes prohibitive for large models and even more pronounced in decentralized federated learning with limited bandwidth and unreliable nodes. Top-K gradient sparsification is an effective approach to reduce communication by transmitting only a few entries of the full gradient, while maintaining competitive model accuracy. Nevertheless, the top-K entries selected by each user are unpredictable and vary across users, which poses a challenge for efficient sparse secure aggregation. This paper studies information-theoretic secure aggregation with top-K sparsification in decentralized federated learning under user dropouts and user collusion. We propose a communication-efficient sparse secure aggregation scheme that offloads dimension-dependent overhead to an offline phase and protects private gradients using random masks and permutations. Experimental results demonstrate that our scheme preserves accuracy comparable to full-gradient aggregation even with only 1% gradient sparsification, while substantially reducing the communication cost.
The Capacity of Information-Theoretic Secure Aggregation in Federated Learning
Jun 05, 2026Secure aggregation allows a server to aggregate users' local updates while preserving update privacy. Existing information-theoretic problems typically assume that correlated random keys are provided by a trusted third party (TTP) or generated via prescribed groupwise structures, while the communication cost for establishing such correlated keys is often ignored. Consequently, the fundamental limits under general key-distribution mechanisms remain unknown. In this paper, we study the $T$-colluding information-theoretic secure aggregation problem with $N$ users under a general two-phase framework consisting of a key distribution phase and an update aggregation phase. Unlike prior work, we model key distribution through user-to-user communication and allow arbitrary user-generated key-distribution mechanisms, eliminating TTP or prescribed structures. This enables a joint characterization of three resources: randomness for security, key-distribution communication, and aggregation communication. We completely characterize the capacity region among these three resources by constructing a novel secure aggregation scheme together with a matching information-theoretic converse. In particular, we develop an explicit deterministic capacity-achieving construction over any finite field of size at least $N$, whereas most existing schemes either rely on TTP or employ randomized or existential constructions over sufficiently large finite fields. We further show that the optimal performance can be achieved using only pairwise shared keys, enabling implementation via Diffie--Hellman key exchange. Compared with Google's seminal secure aggregation scheme, the proposed scheme requires fewer random masking keys while preserving the same aggregation communication overhead.
Repurposing Backdoors for Good: Ephemeral Intrinsic Proofs for Verifiable Aggregation in Cross-silo Federated Learning
Mar 11, 2026While Secure Aggregation (SA) protects update confidentiality in Cross-silo Federated Learning, it fails to guarantee aggregation integrity, allowing malicious servers to silently omit or tamper with updates. Existing verifiable aggregation schemes rely on heavyweight cryptography (e.g., ZKPs, HE), incurring computational costs that scale poorly with model size. In this paper, we propose a lightweight architecture that shifts from extrinsic cryptographic proofs to \textit{Intrinsic Proofs}. We repurpose backdoor injection to embed verification signals directly into model parameters. By harnessing Catastrophic Forgetting, these signals are robust for immediate verification yet ephemeral, naturally decaying to preserve final model utility. We design a randomized, single-verifier auditing framework compatible with SA, ensuring client anonymity and preventing signal collision without trusted third parties. Experiments on SVHN, CIFAR-10, and CIFAR-100 demonstrate high detection probabilities against malicious servers. Notably, our approach achieves over $1000\times$ speedup on ResNet-18 compared to cryptographic baselines, effectively scaling to large models.
Efficiently Achieving Secure Model Training and Secure Aggregation to Ensure Bidirectional Privacy-Preservation in Federated Learning
Dec 16, 2024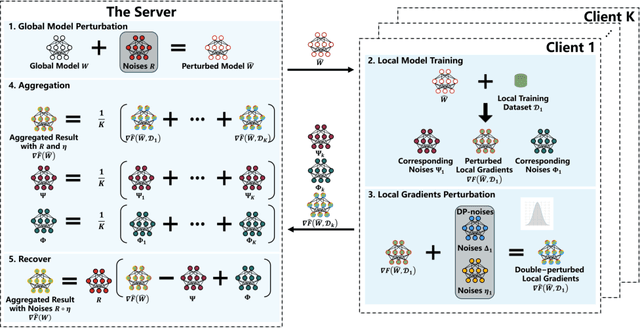
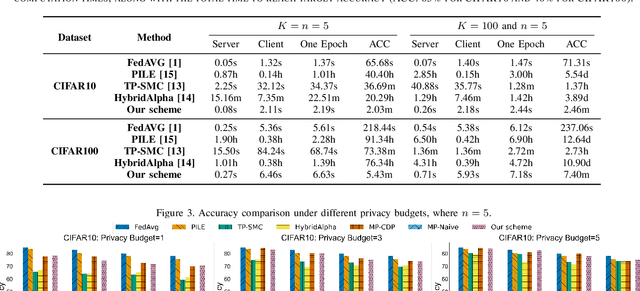
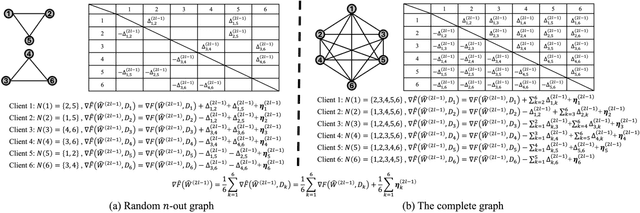

Bidirectional privacy-preservation federated learning is crucial as both local gradients and the global model may leak privacy. However, only a few works attempt to achieve it, and they often face challenges such as excessive communication and computational overheads, or significant degradation of model accuracy, which hinders their practical applications. In this paper, we design an efficient and high-accuracy bidirectional privacy-preserving scheme for federated learning to complete secure model training and secure aggregation. To efficiently achieve bidirectional privacy, we design an efficient and accuracy-lossless model perturbation method on the server side (called $\mathbf{MP\_Server}$) that can be combined with local differential privacy (LDP) to prevent clients from accessing the model, while ensuring that the local gradients obtained on the server side satisfy LDP. Furthermore, to ensure model accuracy, we customize a distributed differential privacy mechanism on the client side (called $\mathbf{DDP\_Client}$). When combined with $\mathbf{MP\_Server}$, it ensures LDP of the local gradients, while ensuring that the aggregated result matches the accuracy of central differential privacy (CDP). Extensive experiments demonstrate that our scheme significantly outperforms state-of-the-art bidirectional privacy-preservation baselines (SOTAs) in terms of computational cost, model accuracy, and defense ability against privacy attacks. Particularly, given target accuracy, the training time of SOTAs is approximately $200$ times, or even over $1000$ times, longer than that of our scheme. When the privacy budget is set relatively small, our scheme incurs less than $6\%$ accuracy loss compared to the privacy-ignoring method, while SOTAs suffer up to $20\%$ accuracy loss. Experimental results also show that the defense capability of our scheme outperforms than SOTAs.
Object Segmentation-Assisted Inter Prediction for Versatile Video Coding
Mar 18, 2024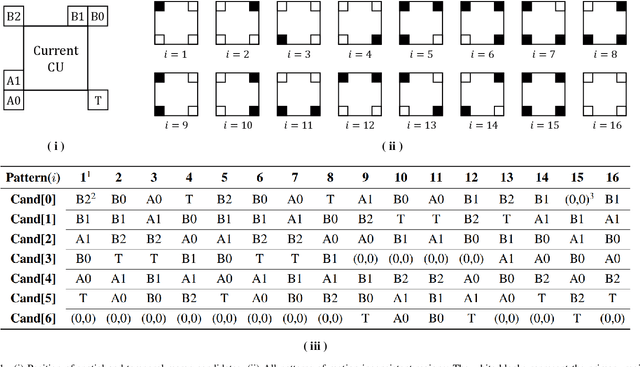
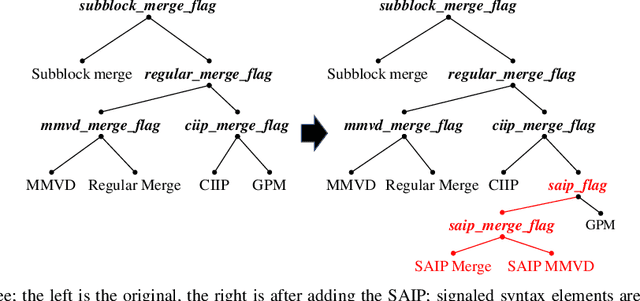
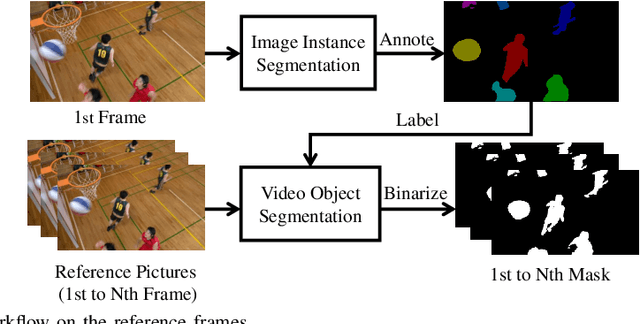

In modern video coding standards, block-based inter prediction is widely adopted, which brings high compression efficiency. However, in natural videos, there are usually multiple moving objects of arbitrary shapes, resulting in complex motion fields that are difficult to compactly represent. This problem has been tackled by more flexible block partitioning methods in the Versatile Video Coding (VVC) standard, but the more flexible partitions require more overhead bits to signal and still cannot be made arbitrary shaped. To address this limitation, we propose an object segmentation-assisted inter prediction method (SAIP), where objects in the reference frames are segmented by some advanced technologies. With a proper indication, the object segmentation mask is translated from the reference frame to the current frame as the arbitrary-shaped partition of different regions without any extra signal. Using the segmentation mask, motion compensation is separately performed for different regions, achieving higher prediction accuracy. The segmentation mask is further used to code the motion vectors of different regions more efficiently. Moreover, segmentation mask is considered in the joint rate-distortion optimization for motion estimation and partition estimation to derive the motion vector of different regions and partition more accurately. The proposed method is implemented into the VVC reference software, VTM version 12.0. Experimental results show that the proposed method achieves up to 1.98%, 1.14%, 0.79%, and on average 0.82%, 0.49%, 0.37% BD-rate reduction for common test sequences, under the Low-delay P, Low-delay B, and Random Access configurations, respectively.
Multi-Satellite Cooperative Networks: Joint Hybrid Beamforming and User Scheduling Design
Oct 12, 2023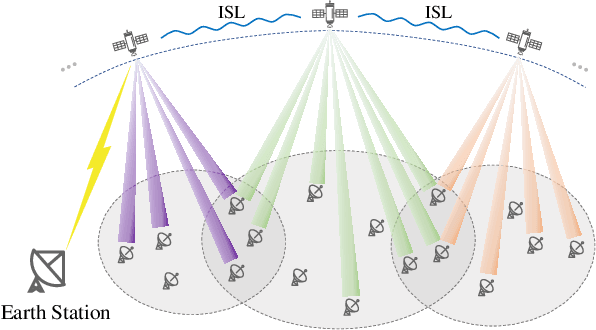
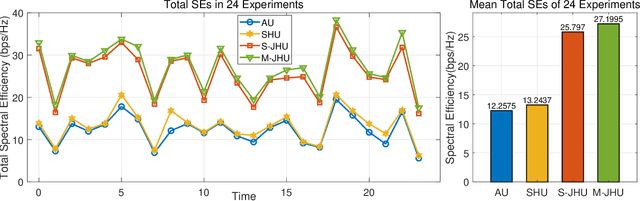
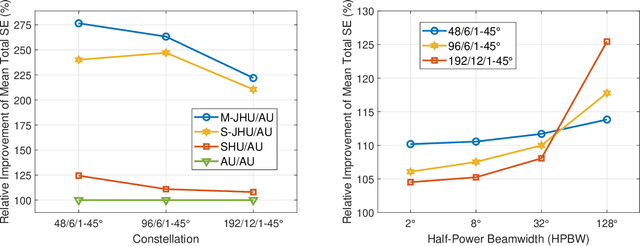
In this paper, we consider a cooperative communication network where multiple low-Earth-orbit satellites provide services for ground users (GUs) (at the same time and on the same frequency). The multi-satellite cooperative network has great potential for satellite communications due to its dense configuration, extensive coverage, and large spectral efficiency. However, the communication and computational resources on satellites are usually restricted. Therefore, considering the limitation of the on-board radio-frequency chains of satellites, we first propose a hybrid beamforming method consisting of analog beamforming for beam alignment and digital beamforming for interference mitigation. Then, to establish appropriate connections between the satellites and GUs, we propose a low-complexity heuristic user scheduling algorithm which determines the connections according to the total spectral efficiency increment of the multi-satellite cooperative network. Next, considering the intrinsic connection between beamforming and user scheduling, a joint hybrid beamforming and user scheduling (JHU) scheme is proposed to dramatically improve the performance of the multi-satellite cooperative network. In addition to the single-connection scenario, we also consider the multi-connection case using the JHU scheme. Moreover, simulations are conducted to compare the proposed schemes with representative baselines and to analyze the key factors influencing the performance of the multi-satellite cooperative network.
Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference
Aug 23, 2023Large language models (LLMs) based on transformers have made significant strides in recent years, the success of which is driven by scaling up their model size. Despite their high algorithmic performance, the computational and memory requirements of LLMs present unprecedented challenges. To tackle the high compute requirements of LLMs, the Mixture-of-Experts (MoE) architecture was introduced which is able to scale its model size without proportionally scaling up its computational requirements. Unfortunately, MoE's high memory demands and dynamic activation of sparse experts restrict its applicability to real-world problems. Previous solutions that offload MoE's memory-hungry expert parameters to CPU memory fall short because the latency to migrate activated experts from CPU to GPU incurs high performance overhead. Our proposed Pre-gated MoE system effectively tackles the compute and memory challenges of conventional MoE architectures using our algorithm-system co-design. Pre-gated MoE employs our novel pre-gating function which alleviates the dynamic nature of sparse expert activation, allowing our proposed system to address the large memory footprint of MoEs while also achieving high performance. We demonstrate that Pre-gated MoE is able to improve performance, reduce GPU memory consumption, while also maintaining the same level of model quality. These features allow our Pre-gated MoE system to cost-effectively deploy large-scale LLMs using just a single GPU with high performance.
An Efficient Virtual Data Generation Method for Reducing Communication in Federated Learning
Jun 29, 2023



Communication overhead is one of the major challenges in Federated Learning(FL). A few classical schemes assume the server can extract the auxiliary information about training data of the participants from the local models to construct a central dummy dataset. The server uses the dummy dataset to finetune aggregated global model to achieve the target test accuracy in fewer communication rounds. In this paper, we summarize the above solutions into a data-based communication-efficient FL framework. The key of the proposed framework is to design an efficient extraction module(EM) which ensures the dummy dataset has a positive effect on finetuning aggregated global model. Different from the existing methods that use generator to design EM, our proposed method, FedINIBoost borrows the idea of gradient match to construct EM. Specifically, FedINIBoost builds a proxy dataset of the real dataset in two steps for each participant at each communication round. Then the server aggregates all the proxy datasets to form a central dummy dataset, which is used to finetune aggregated global model. Extensive experiments verify the superiority of our method compared with the existing classical method, FedAVG, FedProx, Moon and FedFTG. Moreover, FedINIBoost plays a significant role in finetuning the performance of aggregated global model at the initial stage of FL.
An Efficient and Multi-private Key Secure Aggregation for Federated Learning
Jun 15, 2023With the emergence of privacy leaks in federated learning, secure aggregation protocols that mainly adopt either homomorphic encryption or threshold secret sharing have been widely developed for federated learning to protect the privacy of the local training data of each client. However, these existing protocols suffer from many shortcomings, such as the dependence on a trusted third party, the vulnerability to clients being corrupted, low efficiency, the trade-off between security and fault tolerance, etc. To solve these disadvantages, we propose an efficient and multi-private key secure aggregation scheme for federated learning. Specifically, we skillfully modify the variant ElGamal encryption technique to achieve homomorphic addition operation, which has two important advantages: 1) The server and each client can freely select public and private keys without introducing a trust third party and 2) Compared to the variant ElGamal encryption, the plaintext space is relatively large, which is more suitable for the deep model. Besides, for the high dimensional deep model parameter, we introduce a super-increasing sequence to compress multi-dimensional data into 1-D, which can greatly reduce encryption and decryption times as well as communication for ciphertext transmission. Detailed security analyses show that our proposed scheme achieves the semantic security of both individual local gradients and the aggregated result while achieving optimal robustness in tolerating both client collusion and dropped clients. Extensive simulations demonstrate that the accuracy of our scheme is almost the same as the non-private approach, while the efficiency of our scheme is much better than the state-of-the-art homomorphic encryption-based secure aggregation schemes. More importantly, the efficiency advantages of our scheme will become increasingly prominent as the number of model parameters increases.
Low-Complexity Signal Detection for the Splitting Receiver Scheme
May 30, 2023This letter proposes a low-complexity signal detection method for the splitting receiver scheme, which achieves an excellent symbol error rate (SER) performance. Based on the three-dimensional (3D) received signal of the splitting receiver, we derive an equivalent two-dimensional (2D) signal model and develop a low-complexity signal detection method for the practical modulation scheme. The computational complexity of the proposed signal detector is reduced by at least 11.1 times as compared to the 3D signal detection scheme shown in [1]. Simulation results demonstrate that the approximation SER achieved by the low-complexity signal detection is very close to that of the accurate SER at a certain power splitting ratio.