 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecMoE: A Fast and Efficient Mixture-of-Experts Inference via Self-Assisted Speculative Decoding
Apr 11, 2026The Mixture-of-Experts (MoE) architecture has emerged as a promising approach to mitigate the rising computational costs of large language models (LLMs) by selectively activating parameters. However, its high memory requirements and sub-optimal parameter efficiency pose significant challenges for efficient deployment. Although CPU-offloaded MoE inference systems have been proposed in the literature, they offer limited efficiency, particularly for large batch sizes. In this work, we propose SpecMoE, a memory-efficient MoE inference system based on our self-assisted speculative decoding algorithm. SpecMoE demonstrates the effectiveness of applying speculative decoding to MoE inference without requiring additional model training or fine-tuning. Our system improves inference throughput by up to $4.30\times$, while significantly reducing bandwidth requirements of both memory and interconnect on memory-constrained systems.
PASCAL: A Phase-Aware Scheduling Algorithm for Serving Reasoning-based Large Language Models
Feb 12, 2026The emergence of reasoning-based LLMs leveraging Chain-of-Thought (CoT) inference introduces new serving challenges, as their extended reasoning phases delay user-visible output and inflate Time-To-First-Token (TTFT). Existing LLM serving frameworks fail to distinguish between reasoning and answering phases, leading to performance degradation under GPU memory constraints. We present PASCAL, a phase-aware scheduling algorithm that prioritizes reasoning to reduce TTFT while using controlled preemption and token pacing during answering to preserve Quality-of-Experience (QoE). Our hierarchical scheduler combines instance-level placement with intra-instance execution and enables dynamic migration at phase boundaries to balance load and reduce interference. Across benchmarks using DeepSeek-R1-Distill-Qwen-32B, PASCAL reduces tail TTFT by up to 72% while maintaining answering phase SLO attainment, demonstrating the importance of phase-aware scheduling for reasoning-based LLM deployment.
Debunking the CUDA Myth Towards GPU-based AI Systems
Dec 31, 2024



With the rise of AI, NVIDIA GPUs have become the de facto standard for AI system design. This paper presents a comprehensive evaluation of Intel Gaudi NPUs as an alternative to NVIDIA GPUs for AI model serving. First, we create a suite of microbenchmarks to compare Intel Gaudi-2 with NVIDIA A100, showing that Gaudi-2 achieves competitive performance not only in primitive AI compute, memory, and communication operations but also in executing several important AI workloads end-to-end. We then assess Gaudi NPU's programmability by discussing several software-level optimization strategies to employ for implementing critical FBGEMM operators and vLLM, evaluating their efficiency against GPU-optimized counterparts. Results indicate that Gaudi-2 achieves energy efficiency comparable to A100, though there are notable areas for improvement in terms of software maturity. Overall, we conclude that, with effective integration into high-level AI frameworks, Gaudi NPUs could challenge NVIDIA GPU's dominance in the AI server market, though further improvements are necessary to fully compete with NVIDIA's robust software ecosystem.
LazyDP: Co-Designing Algorithm-Software for Scalable Training of Differentially Private Recommendation Models
Apr 12, 2024Differential privacy (DP) is widely being employed in the industry as a practical standard for privacy protection. While private training of computer vision or natural language processing applications has been studied extensively, the computational challenges of training of recommender systems (RecSys) with DP have not been explored. In this work, we first present our detailed characterization of private RecSys training using DP-SGD, root-causing its several performance bottlenecks. Specifically, we identify DP-SGD's noise sampling and noisy gradient update stage to suffer from a severe compute and memory bandwidth limitation, respectively, causing significant performance overhead in training private RecSys. Based on these findings, we propose LazyDP, an algorithm-software co-design that addresses the compute and memory challenges of training RecSys with DP-SGD. Compared to a state-of-the-art DP-SGD training system, we demonstrate that LazyDP provides an average 119x training throughput improvement while also ensuring mathematically equivalent, differentially private RecSys models to be trained.
Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference
Aug 23, 2023Large language models (LLMs) based on transformers have made significant strides in recent years, the success of which is driven by scaling up their model size. Despite their high algorithmic performance, the computational and memory requirements of LLMs present unprecedented challenges. To tackle the high compute requirements of LLMs, the Mixture-of-Experts (MoE) architecture was introduced which is able to scale its model size without proportionally scaling up its computational requirements. Unfortunately, MoE's high memory demands and dynamic activation of sparse experts restrict its applicability to real-world problems. Previous solutions that offload MoE's memory-hungry expert parameters to CPU memory fall short because the latency to migrate activated experts from CPU to GPU incurs high performance overhead. Our proposed Pre-gated MoE system effectively tackles the compute and memory challenges of conventional MoE architectures using our algorithm-system co-design. Pre-gated MoE employs our novel pre-gating function which alleviates the dynamic nature of sparse expert activation, allowing our proposed system to address the large memory footprint of MoEs while also achieving high performance. We demonstrate that Pre-gated MoE is able to improve performance, reduce GPU memory consumption, while also maintaining the same level of model quality. These features allow our Pre-gated MoE system to cost-effectively deploy large-scale LLMs using just a single GPU with high performance.
DiVa: An Accelerator for Differentially Private Machine Learning
Aug 26, 2022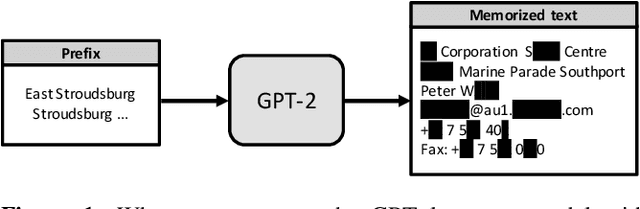
The widespread deployment of machine learning (ML) is raising serious concerns on protecting the privacy of users who contributed to the collection of training data. Differential privacy (DP) is rapidly gaining momentum in the industry as a practical standard for privacy protection. Despite DP's importance, however, little has been explored within the computer systems community regarding the implication of this emerging ML algorithm on system designs. In this work, we conduct a detailed workload characterization on a state-of-the-art differentially private ML training algorithm named DP-SGD. We uncover several unique properties of DP-SGD (e.g., its high memory capacity and computation requirements vs. non-private ML), root-causing its key bottlenecks. Based on our analysis, we propose an accelerator for differentially private ML named DiVa, which provides a significant improvement in compute utilization, leading to 2.6x higher energy-efficiency vs. conventional systolic arrays.
GROW: A Row-Stationary Sparse-Dense GEMM Accelerator for Memory-Efficient Graph Convolutional Neural Networks
Mar 02, 2022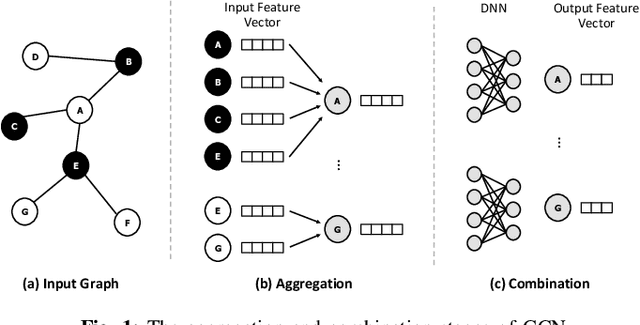
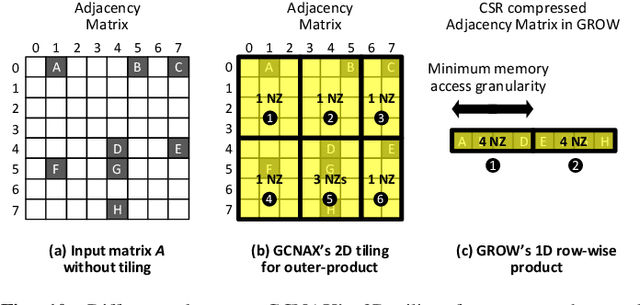
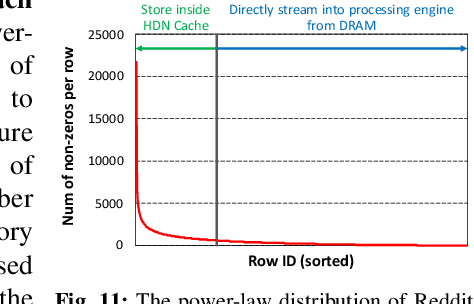
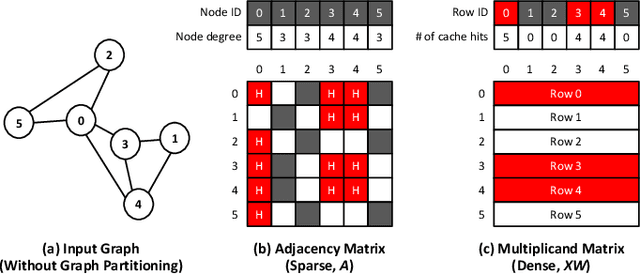
Graph convolutional neural networks (GCNs) have emerged as a key technology in various application domains where the input data is relational. A unique property of GCNs is that its two primary execution stages, aggregation and combination, exhibit drastically different dataflows. Consequently, prior GCN accelerators tackle this research space by casting the aggregation and combination stages as a series of sparse-dense matrix multiplication. However, prior work frequently suffers from inefficient data movements, leaving significant performance left on the table. We present GROW, a GCN accelerator based on Gustavson's algorithm to architect a row-wise product based sparse-dense GEMM accelerator. GROW co-designs the software/hardware that strikes a balance in locality and parallelism for GCNs, achieving significant energy-efficiency improvements vs. state-of-the-art GCN accelerators.
Centaur: A Chiplet-based, Hybrid Sparse-Dense Accelerator for Personalized Recommendations
May 12, 2020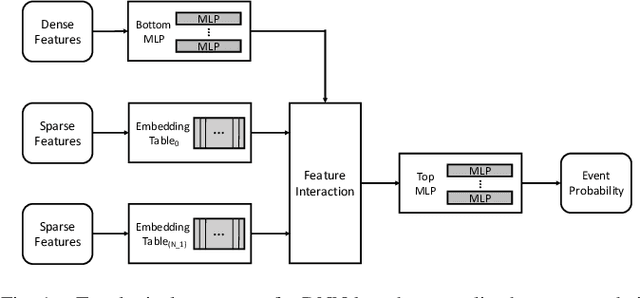
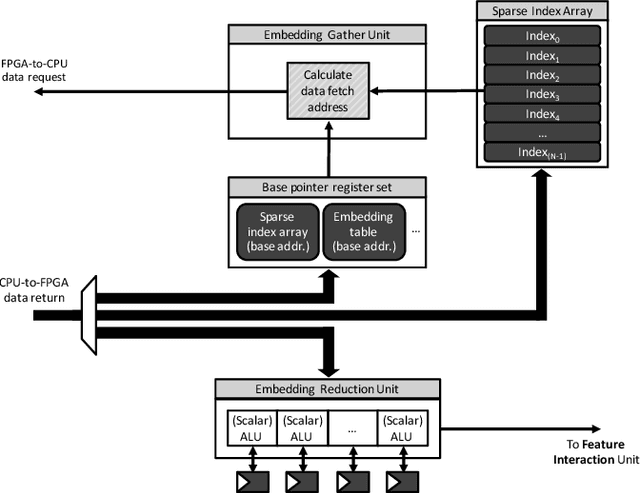
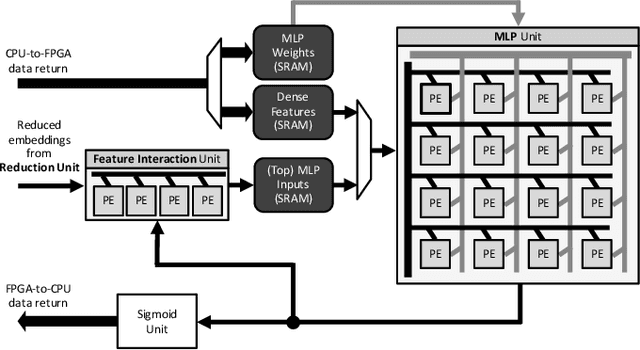
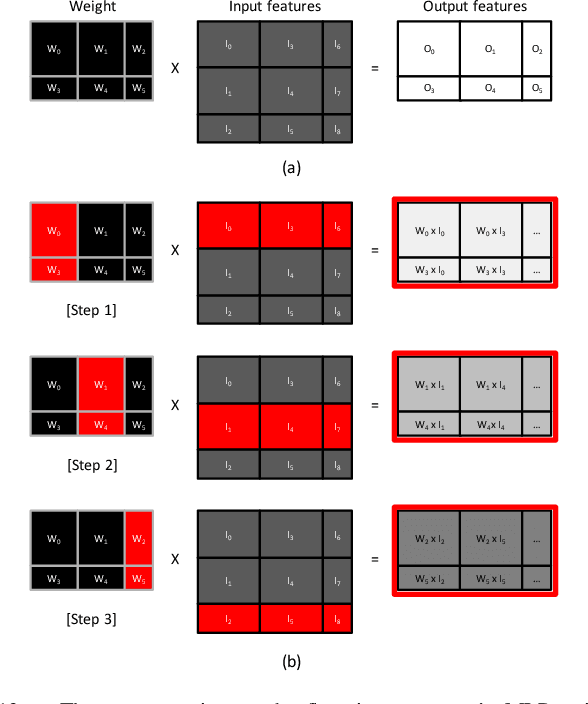
Personalized recommendations are the backbone machine learning (ML) algorithm that powers several important application domains (e.g., ads, e-commerce, etc) serviced from cloud datacenters. Sparse embedding layers are a crucial building block in designing recommendations yet little attention has been paid in properly accelerating this important ML algorithm. This paper first provides a detailed workload characterization on personalized recommendations and identifies two significant performance limiters: memory-intensive embedding layers and compute-intensive multi-layer perceptron (MLP) layers. We then present Centaur, a chiplet-based hybrid sparse-dense accelerator that addresses both the memory throughput challenges of embedding layers and the compute limitations of MLP layers. We implement and demonstrate our proposal on an Intel HARPv2, a package-integrated CPU+FPGA device, which shows a 1.7-17.2x performance speedup and 1.7-19.5x energy-efficiency improvement than conventional approaches.