 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-fidelity Modeling of Full-scale Pressurized Water Reactor Flow Fields for Machine Learning Applications
May 23, 2026This work presents a high-fidelity computational fluid dynamics (CFD) and data-driven modeling framework for assembly-level flow characterization in a four-loop pressurized water reactor (PWR). A full lower-plenum and core-inlet domain was constructed using publicly available geometry and operating conditions, enabling transient simulations with pump-induced swirl boundary conditions. The results show that cold-leg swirl and lower-plenum transport generate strongly heterogeneous assembly-wise inlet flow distributions, particularly near the lower core region, while axial resistance and mixing progressively homogenize the flow at higher elevations. These physics-informed datasets were subsequently used to evaluate machine learning (ML) applications for partial field reconstruction and short-term autoregressive prediction. A 3D convolutional-based inpainting model successfully recon-structed missing assembly-level mass flow rates from partial observations, with errors concentrated in the highly turbulent base (bottom) layer and diminishing significantly in upper layers. Comparative analysis across multiple ML models demon-strates that spatially aware architectures, particularly ConvLSTM, significantly outperform sequence-based (LSTM) and operator-learning (DeepONet) approaches by effectively capturing coupled spatio-temporal dynamics. The study also high-lights key challenges, including the sensitivity of inlet flow predictions to turbulence and mesh resolution, as well as the absence of full-scale experimental validation data. Despite these limitations, the results remain consistent with expected physical behavior. Overall, this work establishes high-fidelity CFD as a critical foundation for developing data-driven surrogates, sparse sensing strategies, and future multiphysics coupling frameworks.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
GraLoRA: Granular Low-Rank Adaptation for Parameter-Efficient Fine-Tuning
May 26, 2025Low-Rank Adaptation (LoRA) is a popular method for parameter-efficient fine-tuning (PEFT) of generative models, valued for its simplicity and effectiveness. Despite recent enhancements, LoRA still suffers from a fundamental limitation: overfitting when the bottleneck is widened. It performs best at ranks 32-64, yet its accuracy stagnates or declines at higher ranks, still falling short of full fine-tuning (FFT) performance. We identify the root cause as LoRA's structural bottleneck, which introduces gradient entanglement to the unrelated input channels and distorts gradient propagation. To address this, we introduce a novel structure, Granular Low-Rank Adaptation (GraLoRA) that partitions weight matrices into sub-blocks, each with its own low-rank adapter. With negligible computational or storage cost, GraLoRA overcomes LoRA's limitations, effectively increases the representational capacity, and more closely approximates FFT behavior. Experiments on code generation and commonsense reasoning benchmarks show that GraLoRA consistently outperforms LoRA and other baselines, achieving up to +8.5% absolute gain in Pass@1 on HumanEval+. These improvements hold across model sizes and rank settings, making GraLoRA a scalable and robust solution for PEFT. Code, data, and scripts are available at https://github.com/SqueezeBits/GraLoRA.git
Debunking the CUDA Myth Towards GPU-based AI Systems
Dec 31, 2024



With the rise of AI, NVIDIA GPUs have become the de facto standard for AI system design. This paper presents a comprehensive evaluation of Intel Gaudi NPUs as an alternative to NVIDIA GPUs for AI model serving. First, we create a suite of microbenchmarks to compare Intel Gaudi-2 with NVIDIA A100, showing that Gaudi-2 achieves competitive performance not only in primitive AI compute, memory, and communication operations but also in executing several important AI workloads end-to-end. We then assess Gaudi NPU's programmability by discussing several software-level optimization strategies to employ for implementing critical FBGEMM operators and vLLM, evaluating their efficiency against GPU-optimized counterparts. Results indicate that Gaudi-2 achieves energy efficiency comparable to A100, though there are notable areas for improvement in terms of software maturity. Overall, we conclude that, with effective integration into high-level AI frameworks, Gaudi NPUs could challenge NVIDIA GPU's dominance in the AI server market, though further improvements are necessary to fully compete with NVIDIA's robust software ecosystem.
QUICK: Quantization-aware Interleaving and Conflict-free Kernel for efficient LLM inference
Feb 15, 2024



We introduce QUICK, a group of novel optimized CUDA kernels for the efficient inference of quantized Large Language Models (LLMs). QUICK addresses the shared memory bank-conflict problem of state-of-the-art mixed precision matrix multiplication kernels. Our method interleaves the quantized weight matrices of LLMs offline to skip the shared memory write-back after the dequantization. We demonstrate up to 1.91x speedup over existing kernels of AutoAWQ on larger batches and up to 1.94x throughput gain on representative LLM models on various NVIDIA GPU devices.
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Feb 14, 2024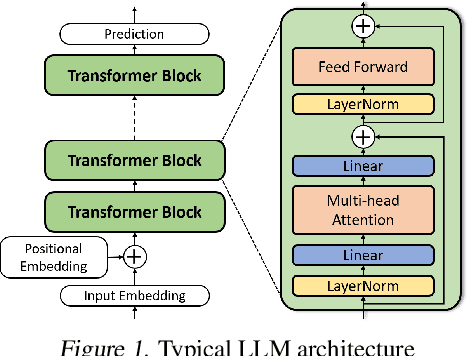
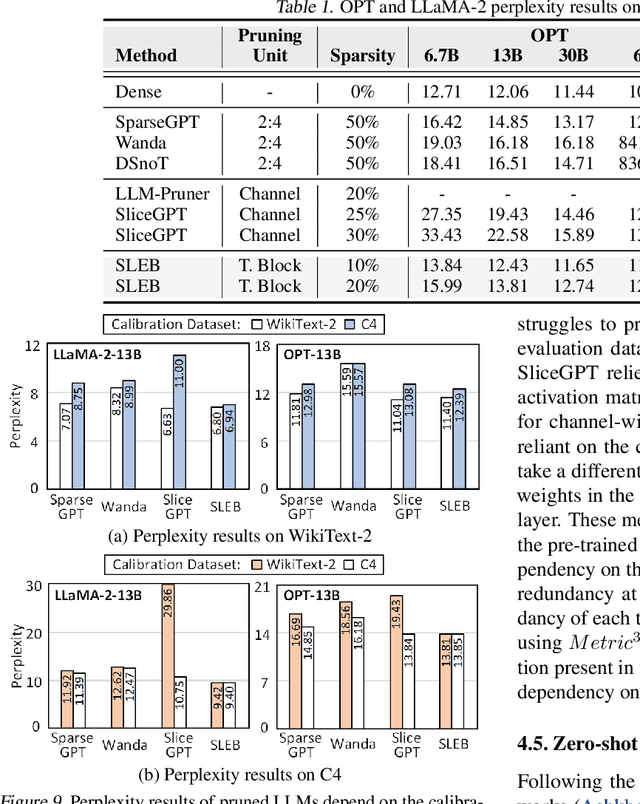
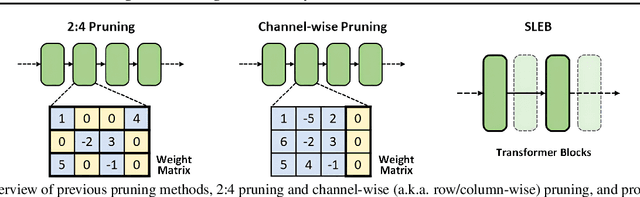
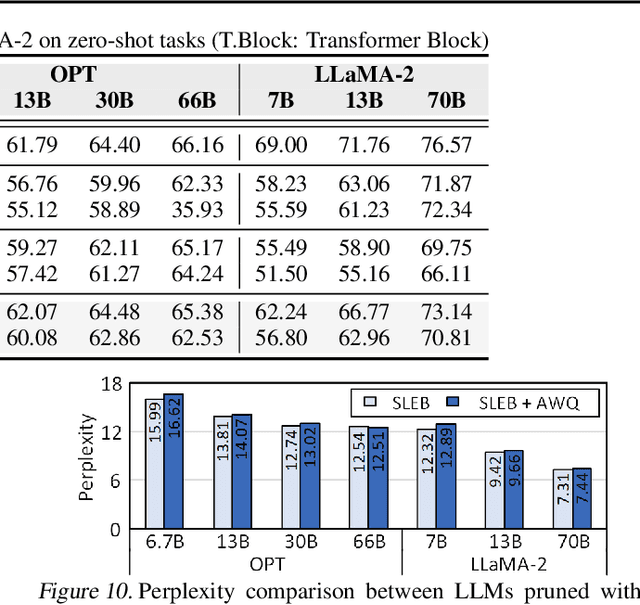
Large language models (LLMs) have proven to be highly effective across various natural language processing tasks. However, their large number of parameters poses significant challenges for practical deployment. Pruning, a technique aimed at reducing the size and complexity of LLMs, offers a potential solution by removing redundant components from the network. Despite the promise of pruning, existing methods often struggle to achieve substantial end-to-end LLM inference speedup. In this paper, we introduce SLEB, a novel approach designed to streamline LLMs by eliminating redundant transformer blocks. We choose the transformer block as the fundamental unit for pruning, because LLMs exhibit block-level redundancy with high similarity between the outputs of neighboring blocks. This choice allows us to effectively enhance the processing speed of LLMs. Our experimental results demonstrate that SLEB successfully accelerates LLM inference without compromising the linguistic capabilities of these models, making it a promising technique for optimizing the efficiency of LLMs. The code is available at: https://github.com/leapingjagg-dev/SLEB
Squeezing Large-Scale Diffusion Models for Mobile
Jul 03, 2023The emergence of diffusion models has greatly broadened the scope of high-fidelity image synthesis, resulting in notable advancements in both practical implementation and academic research. With the active adoption of the model in various real-world applications, the need for on-device deployment has grown considerably. However, deploying large diffusion models such as Stable Diffusion with more than one billion parameters to mobile devices poses distinctive challenges due to the limited computational and memory resources, which may vary according to the device. In this paper, we present the challenges and solutions for deploying Stable Diffusion on mobile devices with TensorFlow Lite framework, which supports both iOS and Android devices. The resulting Mobile Stable Diffusion achieves the inference latency of smaller than 7 seconds for a 512x512 image generation on Android devices with mobile GPUs.
OWQ: Lessons learned from activation outliers for weight quantization in large language models
Jun 13, 2023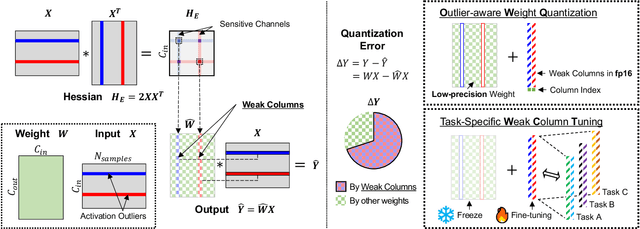
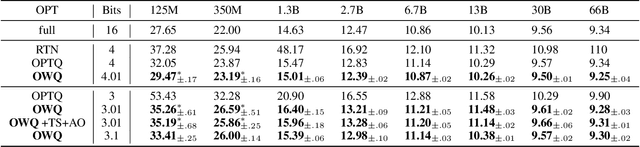
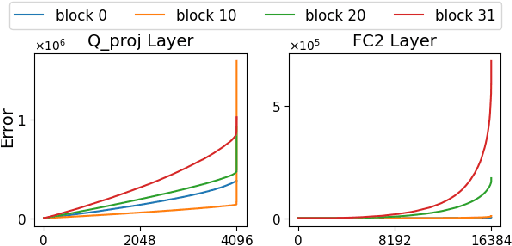
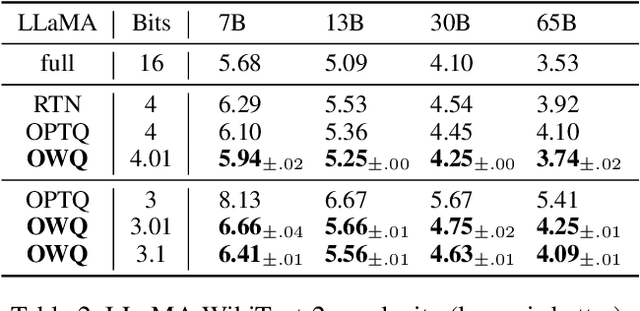
Large language models (LLMs) with hundreds of billions of parameters show impressive results across various language tasks using simple prompt tuning and few-shot examples, without the need for task-specific fine-tuning. However, their enormous size requires multiple server-grade GPUs even for inference, creating a significant cost barrier. To address this limitation, we introduce a novel post-training quantization method for weights with minimal quality degradation. While activation outliers are known to be problematic in activation quantization, our theoretical analysis suggests that we can identify factors contributing to weight quantization errors by considering activation outliers. We propose an innovative PTQ scheme called outlier-aware weight quantization (OWQ), which identifies vulnerable weights and allocates high-precision to them. Our extensive experiments demonstrate that the 3.01-bit models produced by OWQ exhibit comparable quality to the 4-bit models generated by OPTQ.
Temporal Dynamic Quantization for Diffusion Models
Jun 04, 2023The diffusion model has gained popularity in vision applications due to its remarkable generative performance and versatility. However, high storage and computation demands, resulting from the model size and iterative generation, hinder its use on mobile devices. Existing quantization techniques struggle to maintain performance even in 8-bit precision due to the diffusion model's unique property of temporal variation in activation. We introduce a novel quantization method that dynamically adjusts the quantization interval based on time step information, significantly improving output quality. Unlike conventional dynamic quantization techniques, our approach has no computational overhead during inference and is compatible with both post-training quantization (PTQ) and quantization-aware training (QAT). Our extensive experiments demonstrate substantial improvements in output quality with the quantized diffusion model across various datasets.
INSTA-BNN: Binary Neural Network with INSTAnce-aware Threshold
Apr 18, 2022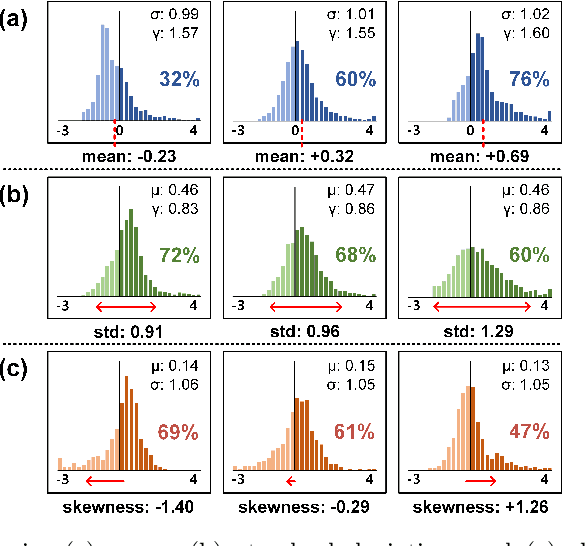
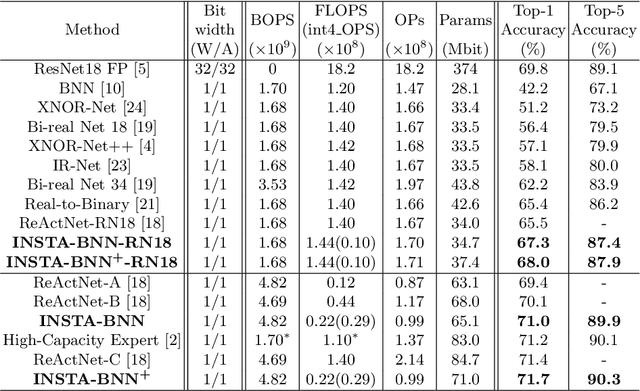
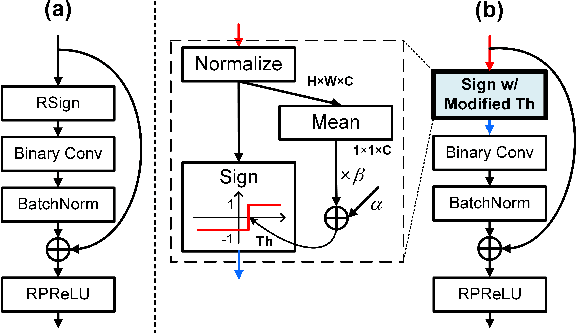

Binary Neural Networks (BNNs) have emerged as a promising solution for reducing the memory footprint and compute costs of deep neural networks. BNNs, on the other hand, suffer from information loss because binary activations are limited to only two values, resulting in reduced accuracy. To improve the accuracy, previous studies have attempted to control the distribution of binary activation by manually shifting the threshold of the activation function or making the shift amount trainable. During the process, they usually depended on statistical information computed from a batch. We argue that using statistical data from a batch fails to capture the crucial information for each input instance in BNN computations, and the differences between statistical information computed from each instance need to be considered when determining the binary activation threshold of each instance. Based on the concept, we propose the Binary Neural Network with INSTAnce-aware threshold (INSTA-BNN), which decides the activation threshold value considering the difference between statistical data computed from a batch and each instance. The proposed INSTA-BNN outperforms the baseline by 2.5% and 2.3% on the ImageNet classification task with comparable computing cost, achieving 68.0% and 71.7% top-1 accuracy on ResNet-18 and MobileNetV1 based models, respectively.