 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation of FP8 Across Accelerators for LLM Inference
Feb 03, 2025



The introduction of 8-bit floating-point (FP8) computation units in modern AI accelerators has generated significant interest in FP8-based large language model (LLM) inference. Unlike 16-bit floating-point formats, FP8 in deep learning requires a shared scaling factor. Additionally, while E4M3 and E5M2 are well-defined at the individual value level, their scaling and accumulation methods remain unspecified and vary across hardware and software implementations. As a result, FP8 behaves more like a quantization format than a standard numeric representation. In this work, we provide the first comprehensive analysis of FP8 computation and acceleration on two AI accelerators: the NVIDIA H100 and Intel Gaudi 2. Our findings highlight that the Gaudi 2, by leveraging FP8, achieves higher throughput-to-power efficiency during LLM inference, offering valuable insights into the practical implications of FP8 adoption for datacenter-scale LLM serving.
Debunking the CUDA Myth Towards GPU-based AI Systems
Dec 31, 2024



With the rise of AI, NVIDIA GPUs have become the de facto standard for AI system design. This paper presents a comprehensive evaluation of Intel Gaudi NPUs as an alternative to NVIDIA GPUs for AI model serving. First, we create a suite of microbenchmarks to compare Intel Gaudi-2 with NVIDIA A100, showing that Gaudi-2 achieves competitive performance not only in primitive AI compute, memory, and communication operations but also in executing several important AI workloads end-to-end. We then assess Gaudi NPU's programmability by discussing several software-level optimization strategies to employ for implementing critical FBGEMM operators and vLLM, evaluating their efficiency against GPU-optimized counterparts. Results indicate that Gaudi-2 achieves energy efficiency comparable to A100, though there are notable areas for improvement in terms of software maturity. Overall, we conclude that, with effective integration into high-level AI frameworks, Gaudi NPUs could challenge NVIDIA GPU's dominance in the AI server market, though further improvements are necessary to fully compete with NVIDIA's robust software ecosystem.
To FP8 and Back Again: Quantifying the Effects of Reducing Precision on LLM Training Stability
May 29, 2024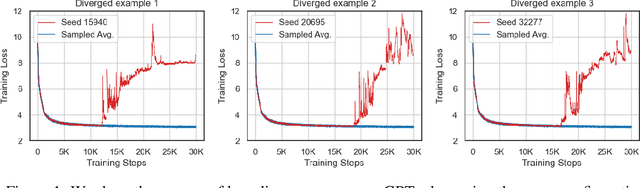
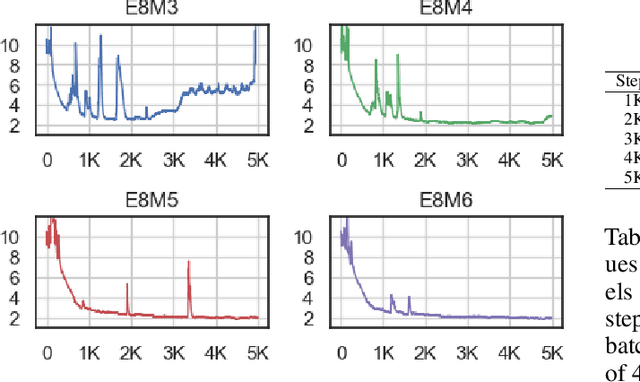
The massive computational costs associated with large language model (LLM) pretraining have spurred great interest in reduced-precision floating-point representations to accelerate the process. As a result, the BrainFloat16 (BF16) precision has become the de facto standard for LLM training, with hardware support included in recent accelerators. This trend has gone even further in the latest processors, where FP8 has recently been introduced. However, prior experience with FP16, which was found to be less stable than BF16, raises concerns as to whether FP8, with even fewer bits than FP16, can be a cost-effective option for LLM training. We argue that reduced-precision training schemes must have similar training stability and hyperparameter sensitivities to their higher-precision counterparts in order to be cost-effective. However, we find that currently available methods for FP8 training are not robust enough to allow their use as economical replacements. This prompts us to investigate the stability of reduced-precision LLM training in terms of robustness across random seeds and learning rates. To this end, we propose new evaluation techniques and a new metric for quantifying loss landscape sharpness in autoregressive language models. By simulating incremental bit reductions in floating-point representations, we analyze the relationship between representational power and training stability with the intent of aiding future research into the field.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024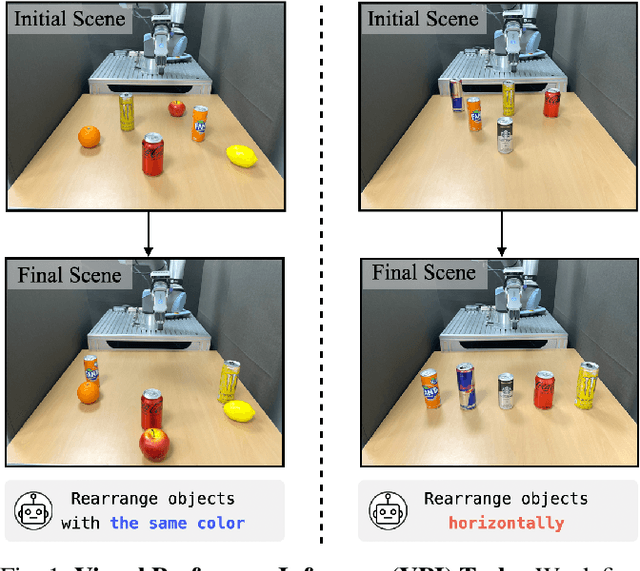

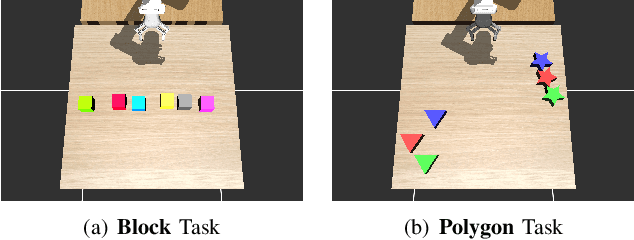

In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
SPOTS: Stable Placement of Objects with Reasoning in Semi-Autonomous Teleoperation Systems
Sep 25, 2023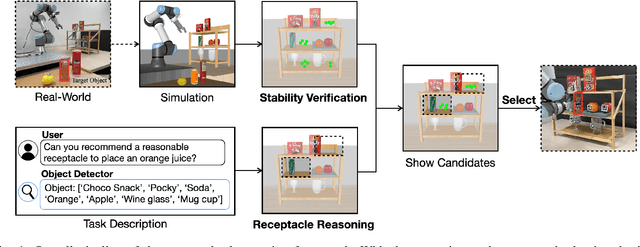
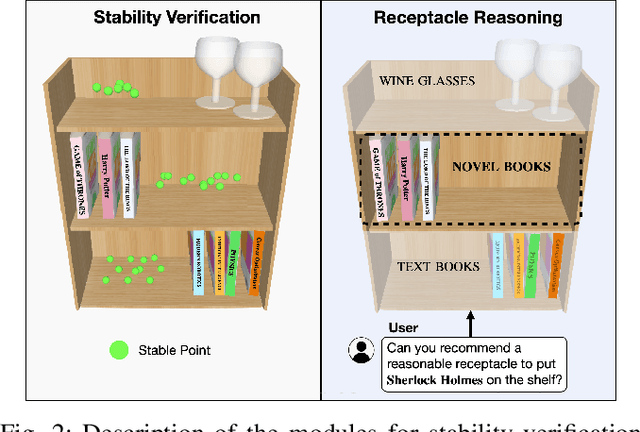
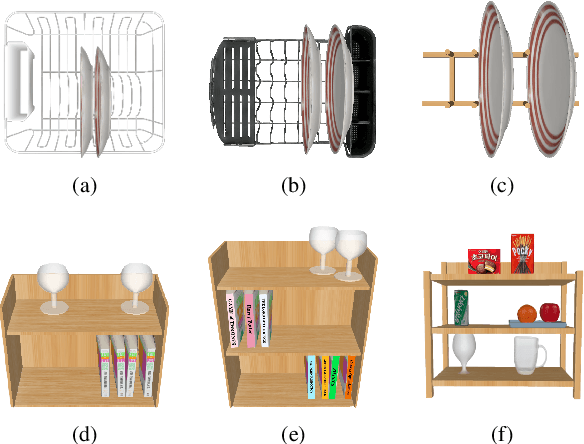
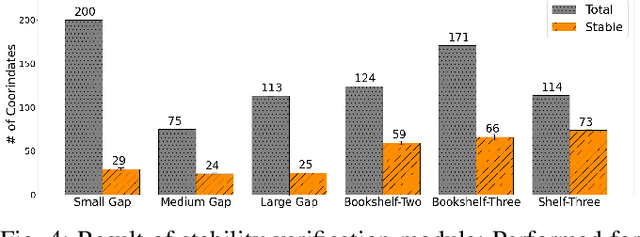
Pick-and-place is one of the fundamental tasks in robotics research. However, the attention has been mostly focused on the ``pick'' task, leaving the ``place'' task relatively unexplored. In this paper, we address the problem of placing objects in the context of a teleoperation framework. Particularly, we focus on two aspects of the place task: stability robustness and contextual reasonableness of object placements. Our proposed method combines simulation-driven physical stability verification via real-to-sim and the semantic reasoning capability of large language models. In other words, given place context information (e.g., user preferences, object to place, and current scene information), our proposed method outputs a probability distribution over the possible placement candidates, considering the robustness and reasonableness of the place task. Our proposed method is extensively evaluated in two simulation and one real world environments and we show that our method can greatly increase the physical plausibility of the placement as well as contextual soundness while considering user preferences.
CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents
Jun 22, 2023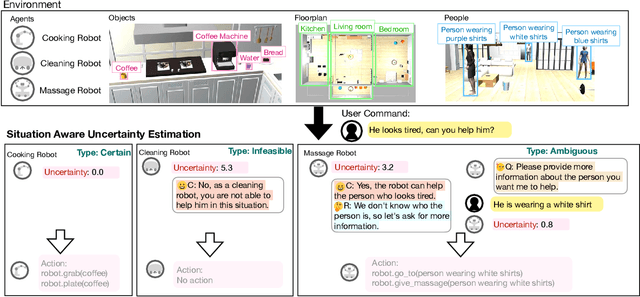
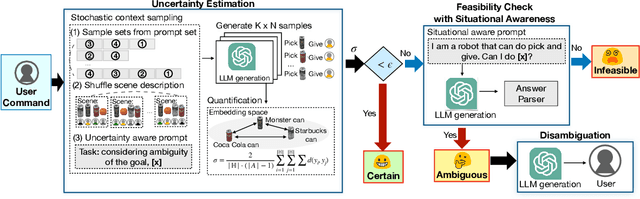
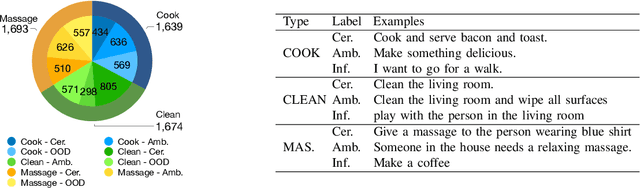
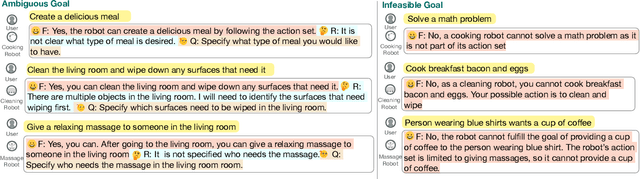
In this paper, we focus on inferring whether the given user command is clear, ambiguous, or infeasible in the context of interactive robotic agents utilizing large language models (LLMs). To tackle this problem, we first present an uncertainty estimation method for LLMs to classify whether the command is certain (i.e., clear) or not (i.e., ambiguous or infeasible). Once the command is classified as uncertain, we further distinguish it between ambiguous or infeasible commands leveraging LLMs with situational aware context in a zero-shot manner. For ambiguous commands, we disambiguate the command by interacting with users via question generation with LLMs. We believe that proper recognition of the given commands could lead to a decrease in malfunction and undesired actions of the robot, enhancing the reliability of interactive robot agents. We present a dataset for robotic situational awareness, consisting pair of high-level commands, scene descriptions, and labels of command type (i.e., clear, ambiguous, or infeasible). We validate the proposed method on the collected dataset, pick-and-place tabletop simulation. Finally, we demonstrate the proposed approach in real-world human-robot interaction experiments, i.e., handover scenarios.
Patch-wise Deep Metric Learning for Unsupervised Low-Dose CT Denoising
Jul 14, 2022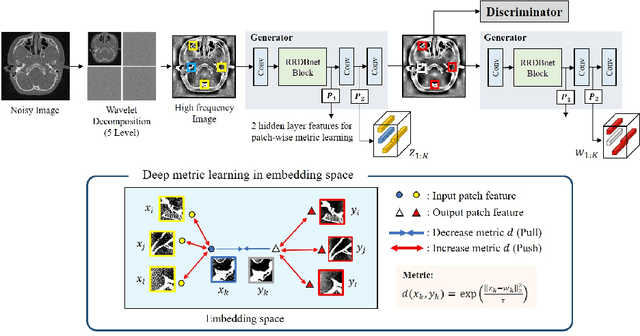

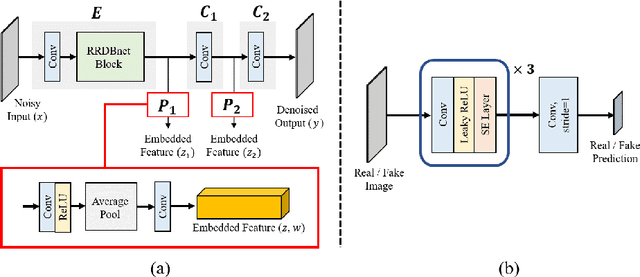
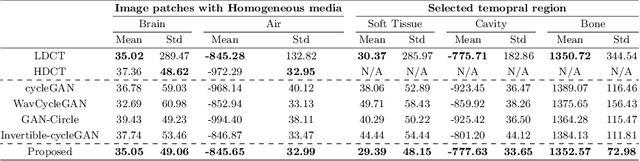
The acquisition conditions for low-dose and high-dose CT images are usually different, so that the shifts in the CT numbers often occur. Accordingly, unsupervised deep learning-based approaches, which learn the target image distribution, often introduce CT number distortions and result in detrimental effects in diagnostic performance. To address this, here we propose a novel unsupervised learning approach for lowdose CT reconstruction using patch-wise deep metric learning. The key idea is to learn embedding space by pulling the positive pairs of image patches which shares the same anatomical structure, and pushing the negative pairs which have same noise level each other. Thereby, the network is trained to suppress the noise level, while retaining the original global CT number distributions even after the image translation. Experimental results confirm that our deep metric learning plays a critical role in producing high quality denoised images without CT number shift.