 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraLoRA: Granular Low-Rank Adaptation for Parameter-Efficient Fine-Tuning
May 26, 2025Low-Rank Adaptation (LoRA) is a popular method for parameter-efficient fine-tuning (PEFT) of generative models, valued for its simplicity and effectiveness. Despite recent enhancements, LoRA still suffers from a fundamental limitation: overfitting when the bottleneck is widened. It performs best at ranks 32-64, yet its accuracy stagnates or declines at higher ranks, still falling short of full fine-tuning (FFT) performance. We identify the root cause as LoRA's structural bottleneck, which introduces gradient entanglement to the unrelated input channels and distorts gradient propagation. To address this, we introduce a novel structure, Granular Low-Rank Adaptation (GraLoRA) that partitions weight matrices into sub-blocks, each with its own low-rank adapter. With negligible computational or storage cost, GraLoRA overcomes LoRA's limitations, effectively increases the representational capacity, and more closely approximates FFT behavior. Experiments on code generation and commonsense reasoning benchmarks show that GraLoRA consistently outperforms LoRA and other baselines, achieving up to +8.5% absolute gain in Pass@1 on HumanEval+. These improvements hold across model sizes and rank settings, making GraLoRA a scalable and robust solution for PEFT. Code, data, and scripts are available at https://github.com/SqueezeBits/GraLoRA.git
Debunking the CUDA Myth Towards GPU-based AI Systems
Dec 31, 2024



With the rise of AI, NVIDIA GPUs have become the de facto standard for AI system design. This paper presents a comprehensive evaluation of Intel Gaudi NPUs as an alternative to NVIDIA GPUs for AI model serving. First, we create a suite of microbenchmarks to compare Intel Gaudi-2 with NVIDIA A100, showing that Gaudi-2 achieves competitive performance not only in primitive AI compute, memory, and communication operations but also in executing several important AI workloads end-to-end. We then assess Gaudi NPU's programmability by discussing several software-level optimization strategies to employ for implementing critical FBGEMM operators and vLLM, evaluating their efficiency against GPU-optimized counterparts. Results indicate that Gaudi-2 achieves energy efficiency comparable to A100, though there are notable areas for improvement in terms of software maturity. Overall, we conclude that, with effective integration into high-level AI frameworks, Gaudi NPUs could challenge NVIDIA GPU's dominance in the AI server market, though further improvements are necessary to fully compete with NVIDIA's robust software ecosystem.
Music Discovery Dialogue Generation Using Human Intent Analysis and Large Language Models
Nov 11, 2024A conversational music retrieval system can help users discover music that matches their preferences through dialogue. To achieve this, a conversational music retrieval system should seamlessly engage in multi-turn conversation by 1) understanding user queries and 2) responding with natural language and retrieved music. A straightforward solution would be a data-driven approach utilizing such conversation logs. However, few datasets are available for the research and are limited in terms of volume and quality. In this paper, we present a data generation framework for rich music discovery dialogue using a large language model (LLM) and user intents, system actions, and musical attributes. This is done by i) dialogue intent analysis using grounded theory, ii) generating attribute sequences via cascading database filtering, and iii) generating utterances using large language models. By applying this framework to the Million Song dataset, we create LP-MusicDialog, a Large Language Model based Pseudo Music Dialogue dataset, containing over 288k music conversations using more than 319k music items. Our evaluation shows that the synthetic dataset is competitive with an existing, small human dialogue dataset in terms of dialogue consistency, item relevance, and naturalness. Furthermore, using the dataset, we train a conversational music retrieval model and show promising results.
Mixture of Scales: Memory-Efficient Token-Adaptive Binarization for Large Language Models
Jun 18, 2024



Binarization, which converts weight parameters to binary values, has emerged as an effective strategy to reduce the size of large language models (LLMs). However, typical binarization techniques significantly diminish linguistic effectiveness of LLMs. To address this issue, we introduce a novel binarization technique called Mixture of Scales (BinaryMoS). Unlike conventional methods, BinaryMoS employs multiple scaling experts for binary weights, dynamically merging these experts for each token to adaptively generate scaling factors. This token-adaptive approach boosts the representational power of binarized LLMs by enabling contextual adjustments to the values of binary weights. Moreover, because this adaptive process only involves the scaling factors rather than the entire weight matrix, BinaryMoS maintains compression efficiency similar to traditional static binarization methods. Our experimental results reveal that BinaryMoS surpasses conventional binarization techniques in various natural language processing tasks and even outperforms 2-bit quantization methods, all while maintaining similar model size to static binarization techniques.
QUICK: Quantization-aware Interleaving and Conflict-free Kernel for efficient LLM inference
Feb 15, 2024



We introduce QUICK, a group of novel optimized CUDA kernels for the efficient inference of quantized Large Language Models (LLMs). QUICK addresses the shared memory bank-conflict problem of state-of-the-art mixed precision matrix multiplication kernels. Our method interleaves the quantized weight matrices of LLMs offline to skip the shared memory write-back after the dequantization. We demonstrate up to 1.91x speedup over existing kernels of AutoAWQ on larger batches and up to 1.94x throughput gain on representative LLM models on various NVIDIA GPU devices.
SLEB: Streamlining LLMs through Redundancy Verification and Elimination of Transformer Blocks
Feb 14, 2024
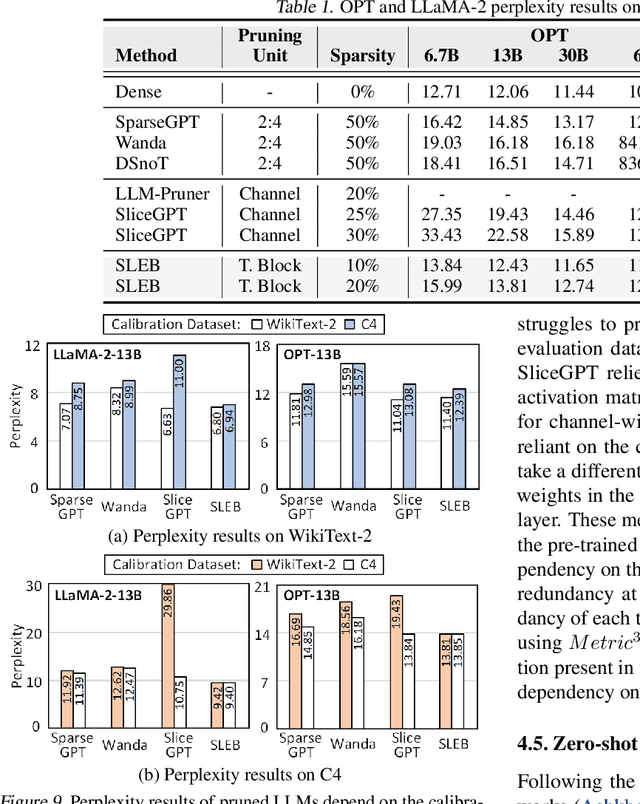
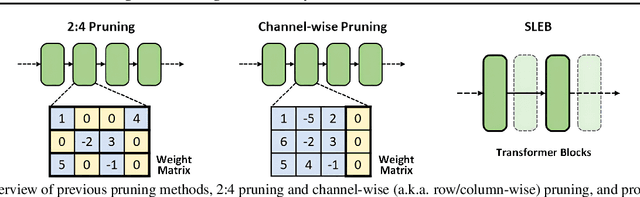
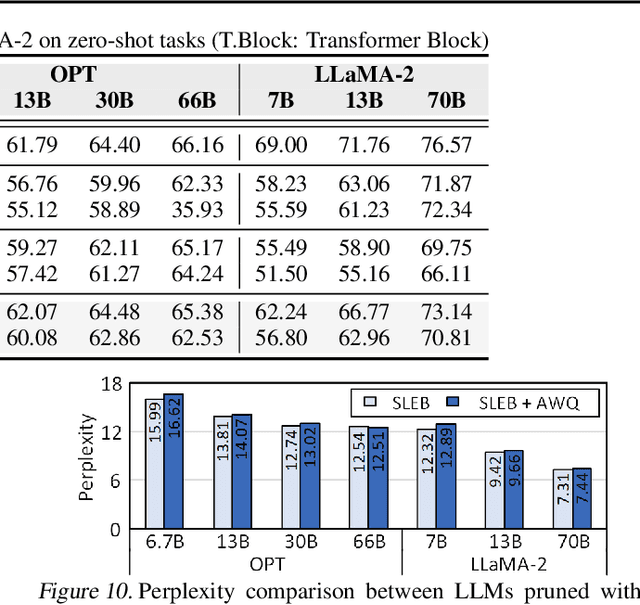
Large language models (LLMs) have proven to be highly effective across various natural language processing tasks. However, their large number of parameters poses significant challenges for practical deployment. Pruning, a technique aimed at reducing the size and complexity of LLMs, offers a potential solution by removing redundant components from the network. Despite the promise of pruning, existing methods often struggle to achieve substantial end-to-end LLM inference speedup. In this paper, we introduce SLEB, a novel approach designed to streamline LLMs by eliminating redundant transformer blocks. We choose the transformer block as the fundamental unit for pruning, because LLMs exhibit block-level redundancy with high similarity between the outputs of neighboring blocks. This choice allows us to effectively enhance the processing speed of LLMs. Our experimental results demonstrate that SLEB successfully accelerates LLM inference without compromising the linguistic capabilities of these models, making it a promising technique for optimizing the efficiency of LLMs. The code is available at: https://github.com/leapingjagg-dev/SLEB
Squeezing Large-Scale Diffusion Models for Mobile
Jul 03, 2023The emergence of diffusion models has greatly broadened the scope of high-fidelity image synthesis, resulting in notable advancements in both practical implementation and academic research. With the active adoption of the model in various real-world applications, the need for on-device deployment has grown considerably. However, deploying large diffusion models such as Stable Diffusion with more than one billion parameters to mobile devices poses distinctive challenges due to the limited computational and memory resources, which may vary according to the device. In this paper, we present the challenges and solutions for deploying Stable Diffusion on mobile devices with TensorFlow Lite framework, which supports both iOS and Android devices. The resulting Mobile Stable Diffusion achieves the inference latency of smaller than 7 seconds for a 512x512 image generation on Android devices with mobile GPUs.
OWQ: Lessons learned from activation outliers for weight quantization in large language models
Jun 13, 2023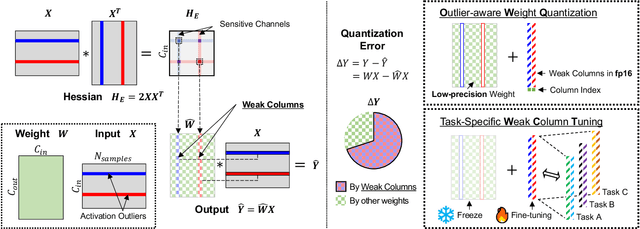
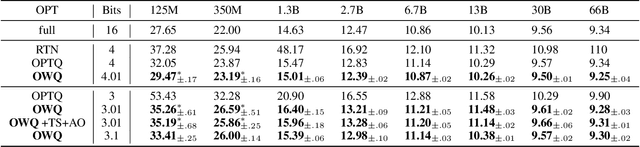
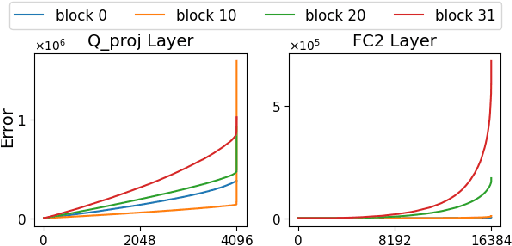
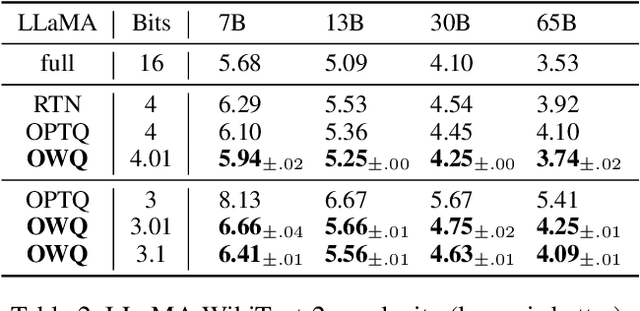
Large language models (LLMs) with hundreds of billions of parameters show impressive results across various language tasks using simple prompt tuning and few-shot examples, without the need for task-specific fine-tuning. However, their enormous size requires multiple server-grade GPUs even for inference, creating a significant cost barrier. To address this limitation, we introduce a novel post-training quantization method for weights with minimal quality degradation. While activation outliers are known to be problematic in activation quantization, our theoretical analysis suggests that we can identify factors contributing to weight quantization errors by considering activation outliers. We propose an innovative PTQ scheme called outlier-aware weight quantization (OWQ), which identifies vulnerable weights and allocates high-precision to them. Our extensive experiments demonstrate that the 3.01-bit models produced by OWQ exhibit comparable quality to the 4-bit models generated by OPTQ.
Cross-speaker Emotion Transfer by Manipulating Speech Style Latents
Mar 15, 2023In recent years, emotional text-to-speech has shown considerable progress. However, it requires a large amount of labeled data, which is not easily accessible. Even if it is possible to acquire an emotional speech dataset, there is still a limitation in controlling emotion intensity. In this work, we propose a novel method for cross-speaker emotion transfer and manipulation using vector arithmetic in latent style space. By leveraging only a few labeled samples, we generate emotional speech from reading-style speech without losing the speaker identity. Furthermore, emotion strength is readily controllable using a scalar value, providing an intuitive way for users to manipulate speech. Experimental results show the proposed method affords superior performance in terms of expressiveness, naturalness, and controllability, preserving speaker identity.
Hi,KIA: A Speech Emotion Recognition Dataset for Wake-Up Words
Nov 07, 2022
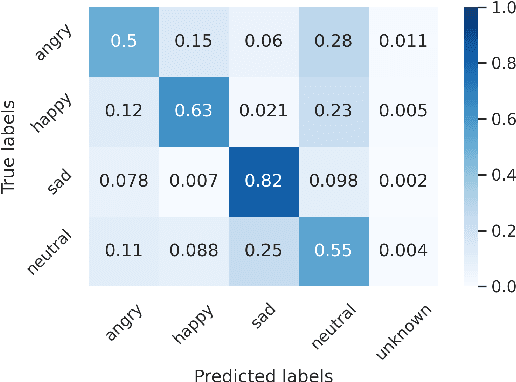
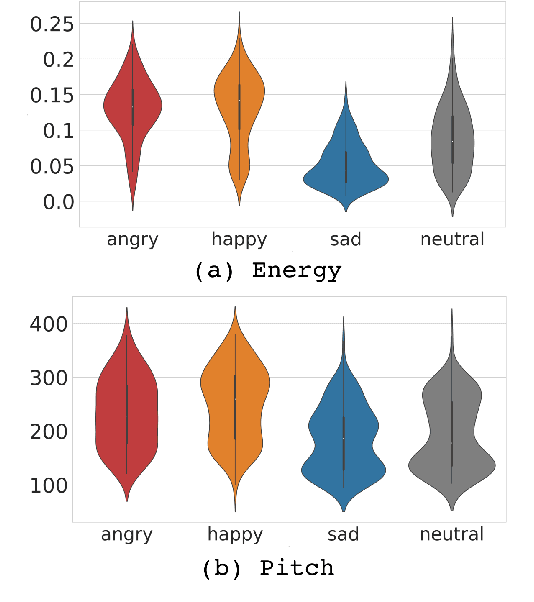
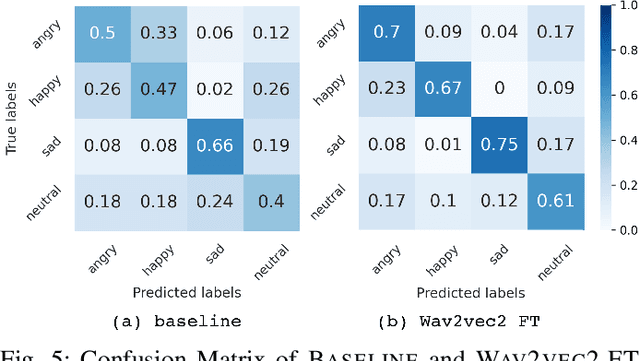
Wake-up words (WUW) is a short sentence used to activate a speech recognition system to receive the user's speech input. WUW utterances include not only the lexical information for waking up the system but also non-lexical information such as speaker identity or emotion. In particular, recognizing the user's emotional state may elaborate the voice communication. However, there is few dataset where the emotional state of the WUW utterances is labeled. In this paper, we introduce Hi, KIA, a new WUW dataset which consists of 488 Korean accent emotional utterances collected from four male and four female speakers and each of utterances is labeled with four emotional states including anger, happy, sad, or neutral. We present the step-by-step procedure to build the dataset, covering scenario selection, post-processing, and human validation for label agreement. Also, we provide two classification models for WUW speech emotion recognition using the dataset. One is based on traditional hand-craft features and the other is a transfer-learning approach using a pre-trained neural network. These classification models could be used as benchmarks in further research.