 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn scalable and efficient training of diffusion samplers
May 26, 2025We address the challenge of training diffusion models to sample from unnormalized energy distributions in the absence of data, the so-called diffusion samplers. Although these approaches have shown promise, they struggle to scale in more demanding scenarios where energy evaluations are expensive and the sampling space is high-dimensional. To address this limitation, we propose a scalable and sample-efficient framework that properly harmonizes the powerful classical sampling method and the diffusion sampler. Specifically, we utilize Monte Carlo Markov chain (MCMC) samplers with a novelty-based auxiliary energy as a Searcher to collect off-policy samples, using an auxiliary energy function to compensate for exploring modes the diffusion sampler rarely visits. These off-policy samples are then combined with on-policy data to train the diffusion sampler, thereby expanding its coverage of the energy landscape. Furthermore, we identify primacy bias, i.e., the preference of samplers for early experience during training, as the main cause of mode collapse during training, and introduce a periodic re-initialization trick to resolve this issue. Our method significantly improves sample efficiency on standard benchmarks for diffusion samplers and also excels at higher-dimensional problems and real-world molecular conformer generation.
Energy-based generator matching: A neural sampler for general state space
May 26, 2025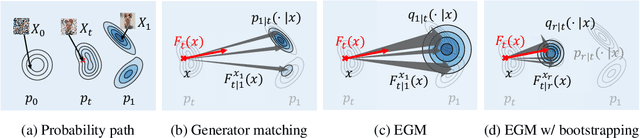
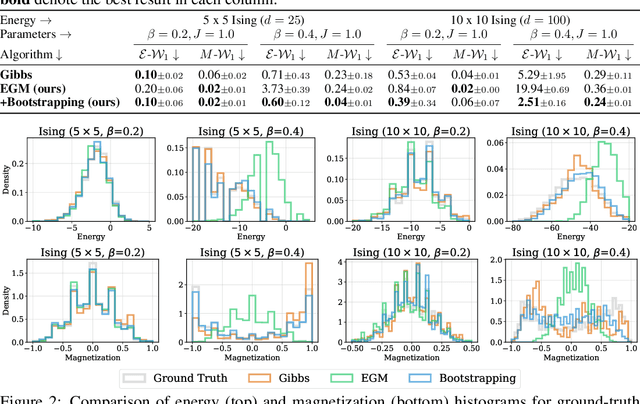
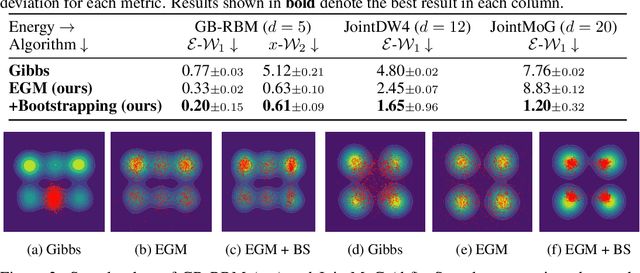
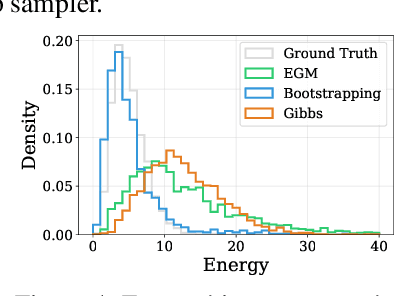
We propose Energy-based generator matching (EGM), a modality-agnostic approach to train generative models from energy functions in the absence of data. Extending the recently proposed generator matching, EGM enables training of arbitrary continuous-time Markov processes, e.g., diffusion, flow, and jump, and can generate data from continuous, discrete, and a mixture of two modalities. To this end, we propose estimating the generator matching loss using self-normalized importance sampling with an additional bootstrapping trick to reduce variance in the importance weight. We validate EGM on both discrete and multimodal tasks up to 100 and 20 dimensions, respectively.
Alignment without Over-optimization: Training-Free Solution for Diffusion Models
Jan 10, 2025



Diffusion models excel in generative tasks, but aligning them with specific objectives while maintaining their versatility remains challenging. Existing fine-tuning methods often suffer from reward over-optimization, while approximate guidance approaches fail to optimize target rewards effectively. Addressing these limitations, we propose a training-free sampling method based on Sequential Monte Carlo (SMC) to sample from the reward-aligned target distribution. Our approach, tailored for diffusion sampling and incorporating tempering techniques, achieves comparable or superior target rewards to fine-tuning methods while preserving diversity and cross-reward generalization. We demonstrate its effectiveness in single-reward optimization, multi-objective scenarios, and online black-box optimization. This work offers a robust solution for aligning diffusion models with diverse downstream objectives without compromising their general capabilities. Code is available at https://github.com/krafton-ai/DAS .
Text Change Detection in Multilingual Documents Using Image Comparison
Dec 05, 2024Document comparison typically relies on optical character recognition (OCR) as its core technology. However, OCR requires the selection of appropriate language models for each document and the performance of multilingual or hybrid models remains limited. To overcome these challenges, we propose text change detection (TCD) using an image comparison model tailored for multilingual documents. Unlike OCR-based approaches, our method employs word-level text image-to-image comparison to detect changes. Our model generates bidirectional change segmentation maps between the source and target documents. To enhance performance without requiring explicit text alignment or scaling preprocessing, we employ correlations among multi-scale attention features. We also construct a benchmark dataset comprising actual printed and scanned word pairs in various languages to evaluate our model. We validate our approach using our benchmark dataset and public benchmarks Distorted Document Images and the LRDE Document Binarization Dataset. We compare our model against state-of-the-art semantic segmentation and change detection models, as well as to conventional OCR-based models.
Rare-to-Frequent: Unlocking Compositional Generation Power of Diffusion Models on Rare Concepts with LLM Guidance
Oct 29, 2024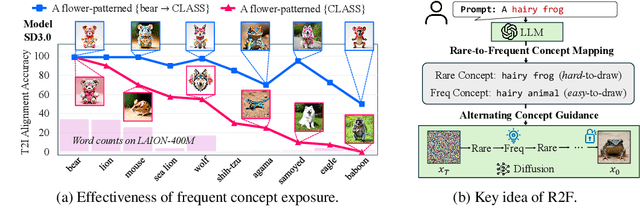
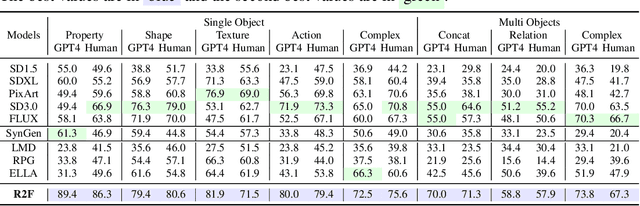
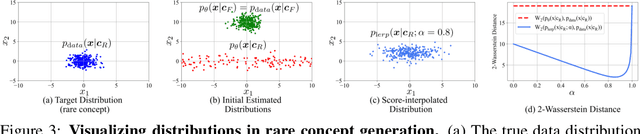
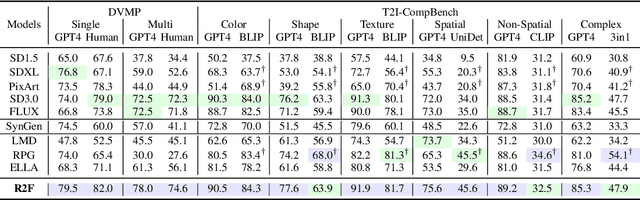
State-of-the-art text-to-image (T2I) diffusion models often struggle to generate rare compositions of concepts, e.g., objects with unusual attributes. In this paper, we show that the compositional generation power of diffusion models on such rare concepts can be significantly enhanced by the Large Language Model (LLM) guidance. We start with empirical and theoretical analysis, demonstrating that exposing frequent concepts relevant to the target rare concepts during the diffusion sampling process yields more accurate concept composition. Based on this, we propose a training-free approach, R2F, that plans and executes the overall rare-to-frequent concept guidance throughout the diffusion inference by leveraging the abundant semantic knowledge in LLMs. Our framework is flexible across any pre-trained diffusion models and LLMs, and can be seamlessly integrated with the region-guided diffusion approaches. Extensive experiments on three datasets, including our newly proposed benchmark, RareBench, containing various prompts with rare compositions of concepts, R2F significantly surpasses existing models including SD3.0 and FLUX by up to 28.1%p in T2I alignment. Code is available at https://github.com/krafton-ai/Rare2Frequent.
Transparent Networks for Multivariate Time Series
Oct 14, 2024Transparent models, which are machine learning models that produce inherently interpretable predictions, are receiving significant attention in high-stakes domains. However, despite much real-world data being collected as time series, there is a lack of studies on transparent time series models. To address this gap, we propose a novel transparent neural network model for time series called Generalized Additive Time Series Model (GATSM). GATSM consists of two parts: 1) independent feature networks to learn feature representations, and 2) a transparent temporal module to learn temporal patterns across different time steps using the feature representations. This structure allows GATSM to effectively capture temporal patterns and handle dynamic-length time series while preserving transparency. Empirical experiments show that GATSM significantly outperforms existing generalized additive models and achieves comparable performance to black-box time series models, such as recurrent neural networks and Transformer. In addition, we demonstrate that GATSM finds interesting patterns in time series. The source code is available at https://github.com/gim4855744/GATSM.
Neural Image Compression with Text-guided Encoding for both Pixel-level and Perceptual Fidelity
Mar 05, 2024Recent advances in text-guided image compression have shown great potential to enhance the perceptual quality of reconstructed images. These methods, however, tend to have significantly degraded pixel-wise fidelity, limiting their practicality. To fill this gap, we develop a new text-guided image compression algorithm that achieves both high perceptual and pixel-wise fidelity. In particular, we propose a compression framework that leverages text information mainly by text-adaptive encoding and training with joint image-text loss. By doing so, we avoid decoding based on text-guided generative models -- known for high generative diversity -- and effectively utilize the semantic information of text at a global level. Experimental results on various datasets show that our method can achieve high pixel-level and perceptual quality, with either human- or machine-generated captions. In particular, our method outperforms all baselines in terms of LPIPS, with some room for even more improvements when we use more carefully generated captions.
KorMedMCQA: Multi-Choice Question Answering Benchmark for Korean Healthcare Professional Licensing Examinations
Mar 05, 2024We introduce KorMedMCQA, the first Korean multiple-choice question answering (MCQA) benchmark derived from Korean healthcare professional licensing examinations, covering from the year 2012 to year 2023. This dataset consists of a selection of questions from the license examinations for doctors, nurses, and pharmacists, featuring a diverse array of subjects. We conduct baseline experiments on various large language models, including proprietary/open-source, multilingual/Korean-additional pretrained, and clinical context pretrained models, highlighting the potential for further enhancements. We make our data publicly available on HuggingFace (https://huggingface.co/datasets/sean0042/KorMedMCQA) and provide a evaluation script via LM-Harness, inviting further exploration and advancement in Korean healthcare environments.
QUICK: Quantization-aware Interleaving and Conflict-free Kernel for efficient LLM inference
Feb 15, 2024We introduce QUICK, a group of novel optimized CUDA kernels for the efficient inference of quantized Large Language Models (LLMs). QUICK addresses the shared memory bank-conflict problem of state-of-the-art mixed precision matrix multiplication kernels. Our method interleaves the quantized weight matrices of LLMs offline to skip the shared memory write-back after the dequantization. We demonstrate up to 1.91x speedup over existing kernels of AutoAWQ on larger batches and up to 1.94x throughput gain on representative LLM models on various NVIDIA GPU devices.
Image Clustering Conditioned on Text Criteria
Oct 30, 2023



Classical clustering methods do not provide users with direct control of the clustering results, and the clustering results may not be consistent with the relevant criterion that a user has in mind. In this work, we present a new methodology for performing image clustering based on user-specified text criteria by leveraging modern vision-language models and large language models. We call our method Image Clustering Conditioned on Text Criteria (IC$|$TC), and it represents a different paradigm of image clustering. IC$|$TC requires a minimal and practical degree of human intervention and grants the user significant control over the clustering results in return. Our experiments show that IC$|$TC can effectively cluster images with various criteria, such as human action, physical location, or the person's mood, while significantly outperforming baselines.