 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKorMedMCQA: Multi-Choice Question Answering Benchmark for Korean Healthcare Professional Licensing Examinations
Mar 05, 2024We introduce KorMedMCQA, the first Korean multiple-choice question answering (MCQA) benchmark derived from Korean healthcare professional licensing examinations, covering from the year 2012 to year 2023. This dataset consists of a selection of questions from the license examinations for doctors, nurses, and pharmacists, featuring a diverse array of subjects. We conduct baseline experiments on various large language models, including proprietary/open-source, multilingual/Korean-additional pretrained, and clinical context pretrained models, highlighting the potential for further enhancements. We make our data publicly available on HuggingFace (https://huggingface.co/datasets/sean0042/KorMedMCQA) and provide a evaluation script via LM-Harness, inviting further exploration and advancement in Korean healthcare environments.
Review Learning: Alleviating Catastrophic Forgetting with Generative Replay without Generator
Oct 17, 2022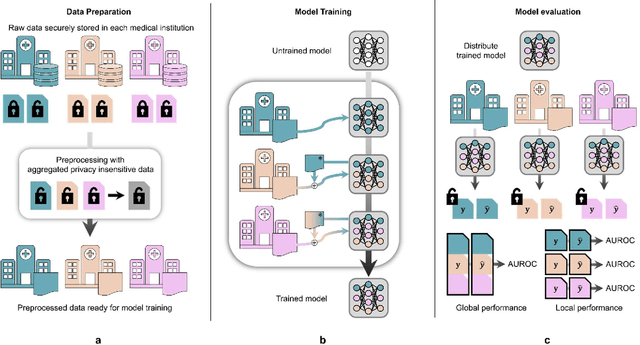

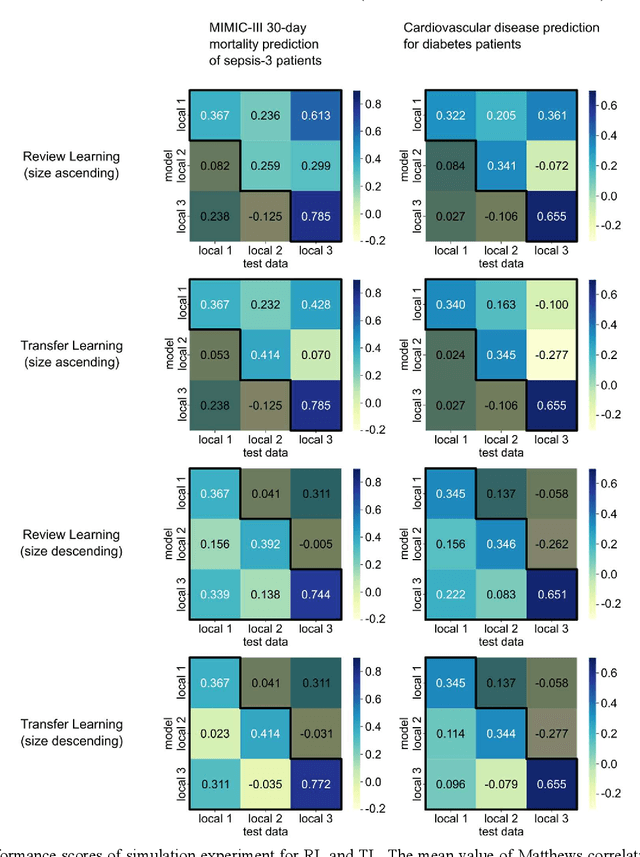
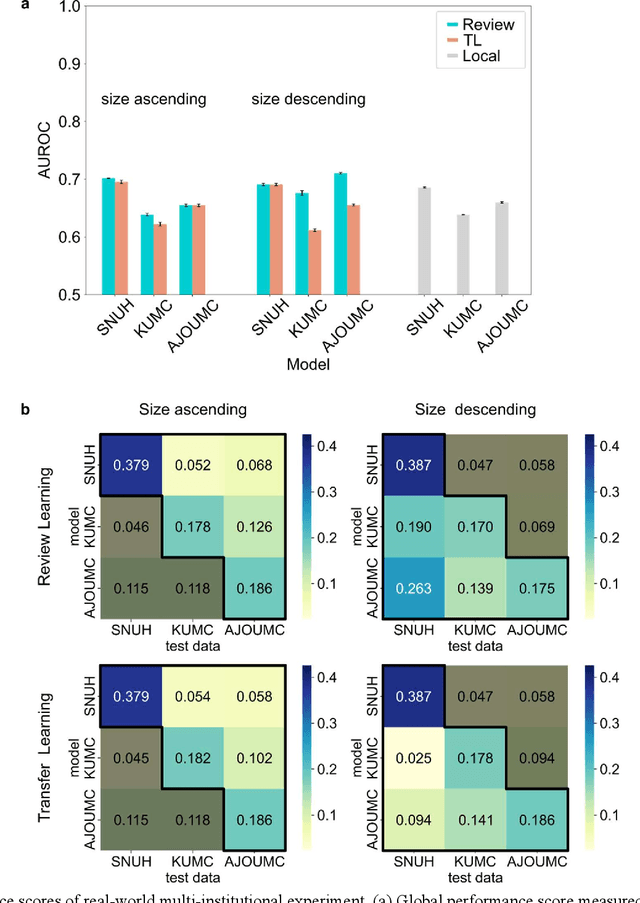
When a deep learning model is sequentially trained on different datasets, it forgets the knowledge acquired from previous data, a phenomenon known as catastrophic forgetting. It deteriorates performance of the deep learning model on diverse datasets, which is critical in privacy-preserving deep learning (PPDL) applications based on transfer learning (TL). To overcome this, we propose review learning (RL), a generative-replay-based continual learning technique that does not require a separate generator. Data samples are generated from the memory stored within the synaptic weights of the deep learning model which are used to review knowledge acquired from previous datasets. The performance of RL was validated through PPDL experiments. Simulations and real-world medical multi-institutional experiments were conducted using three types of binary classification electronic health record data. In the real-world experiments, the global area under the receiver operating curve was 0.710 for RL and 0.655 for TL. Thus, RL was highly effective in retaining previously learned knowledge.