 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-AdminSim: A Multi-Agent Simulator for Realistic Hospital Administrative Workflows with FHIR Integration
Feb 05, 2026Hospital administration departments handle a wide range of operational tasks and, in large hospitals, process over 10,000 requests per day, driving growing interest in LLM-based automation. However, prior work has focused primarily on patient--physician interactions or isolated administrative subtasks, failing to capture the complexity of real administrative workflows. To address this gap, we propose H-AdminSim, a comprehensive end-to-end simulation framework that combines realistic data generation with multi-agent-based simulation of hospital administrative workflows. These tasks are quantitatively evaluated using detailed rubrics, enabling systematic comparison of LLMs. Through FHIR integration, H-AdminSim provides a unified and interoperable environment for testing administrative workflows across heterogeneous hospital settings, serving as a standardized testbed for assessing the feasibility and performance of LLM-driven administrative automation.
ECG-Agent: On-Device Tool-Calling Agent for ECG Multi-Turn Dialogue
Jan 28, 2026Recent advances in Multimodal Large Language Models have rapidly expanded to electrocardiograms, focusing on classification, report generation, and single-turn QA tasks. However, these models fall short in real-world scenarios, lacking multi-turn conversational ability, on-device efficiency, and precise understanding of ECG measurements such as the PQRST intervals. To address these limitations, we introduce ECG-Agent, the first LLM-based tool-calling agent for multi-turn ECG dialogue. To facilitate its development and evaluation, we also present ECG-Multi-Turn-Dialogue (ECG-MTD) dataset, a collection of realistic user-assistant multi-turn dialogues for diverse ECG lead configurations. We develop ECG-Agents in various sizes, from on-device capable to larger agents. Experimental results show that ECG-Agents outperform baseline ECG-LLMs in response accuracy. Furthermore, on-device agents achieve comparable performance to larger agents in various evaluations that assess response accuracy, tool-calling ability, and hallucinations, demonstrating their viability for real-world applications.
Instruction-Guided Lesion Segmentation for Chest X-rays with Automatically Generated Large-Scale Dataset
Nov 19, 2025The applicability of current lesion segmentation models for chest X-rays (CXRs) has been limited both by a small number of target labels and the reliance on long, detailed expert-level text inputs, creating a barrier to practical use. To address these limitations, we introduce a new paradigm: instruction-guided lesion segmentation (ILS), which is designed to segment diverse lesion types based on simple, user-friendly instructions. Under this paradigm, we construct MIMIC-ILS, the first large-scale instruction-answer dataset for CXR lesion segmentation, using our fully automated multimodal pipeline that generates annotations from chest X-ray images and their corresponding reports. MIMIC-ILS contains 1.1M instruction-answer pairs derived from 192K images and 91K unique segmentation masks, covering seven major lesion types. To empirically demonstrate its utility, we introduce ROSALIA, a vision-language model fine-tuned on MIMIC-ILS. ROSALIA can segment diverse lesions and provide textual explanations in response to user instructions. The model achieves high segmentation and textual accuracy in our newly proposed task, highlighting the effectiveness of our pipeline and the value of MIMIC-ILS as a foundational resource for pixel-level CXR lesion grounding.
Modeling Clinical Uncertainty in Radiology Reports: from Explicit Uncertainty Markers to Implicit Reasoning Pathways
Nov 06, 2025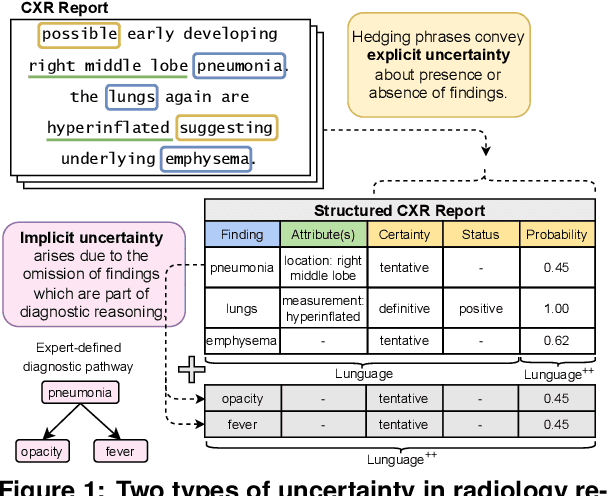
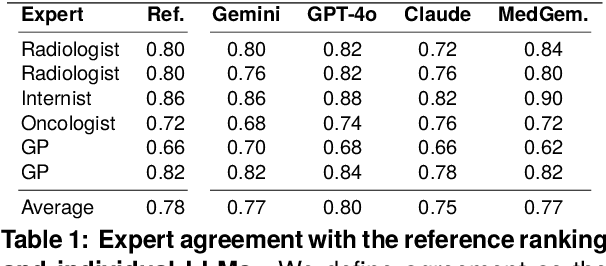
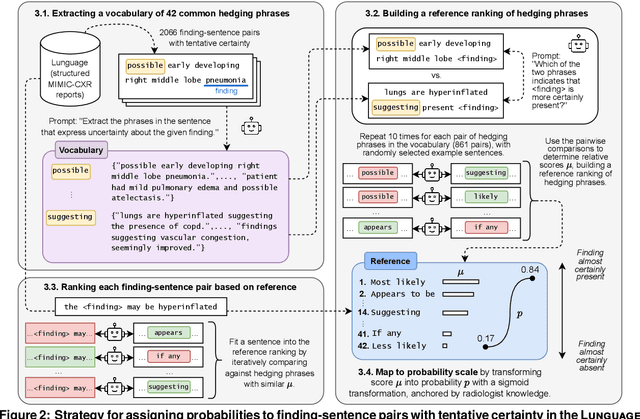
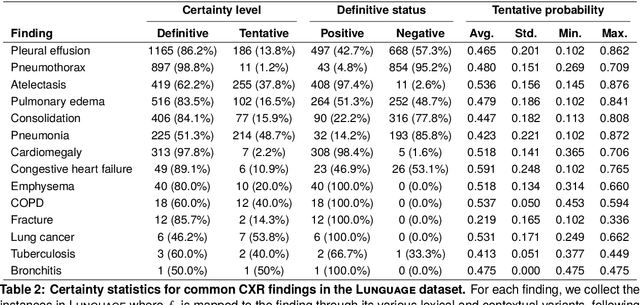
Radiology reports are invaluable for clinical decision-making and hold great potential for automated analysis when structured into machine-readable formats. These reports often contain uncertainty, which we categorize into two distinct types: (i) Explicit uncertainty reflects doubt about the presence or absence of findings, conveyed through hedging phrases. These vary in meaning depending on the context, making rule-based systems insufficient to quantify the level of uncertainty for specific findings; (ii) Implicit uncertainty arises when radiologists omit parts of their reasoning, recording only key findings or diagnoses. Here, it is often unclear whether omitted findings are truly absent or simply unmentioned for brevity. We address these challenges with a two-part framework. We quantify explicit uncertainty by creating an expert-validated, LLM-based reference ranking of common hedging phrases, and mapping each finding to a probability value based on this reference. In addition, we model implicit uncertainty through an expansion framework that systematically adds characteristic sub-findings derived from expert-defined diagnostic pathways for 14 common diagnoses. Using these methods, we release Lunguage++, an expanded, uncertainty-aware version of the Lunguage benchmark of fine-grained structured radiology reports. This enriched resource enables uncertainty-aware image classification, faithful diagnostic reasoning, and new investigations into the clinical impact of diagnostic uncertainty.
Generating Multi-Table Time Series EHR from Latent Space with Minimal Preprocessing
Jul 09, 2025Electronic Health Records (EHR) are time-series relational databases that record patient interactions and medical events over time, serving as a critical resource for healthcare research and applications. However, privacy concerns and regulatory restrictions limit the sharing and utilization of such sensitive data, necessitating the generation of synthetic EHR datasets. Unlike previous EHR synthesis methods, which typically generate medical records consisting of expert-chosen features (e.g. a few vital signs or structured codes only), we introduce RawMed, the first framework to synthesize multi-table, time-series EHR data that closely resembles raw EHRs. Using text-based representation and compression techniques, RawMed captures complex structures and temporal dynamics with minimal preprocessing. We also propose a new evaluation framework for multi-table time-series synthetic EHRs, assessing distributional similarity, inter-table relationships, temporal dynamics, and privacy. Validated on two open-source EHR datasets, RawMed outperforms baseline models in fidelity and utility. The code is available at https://github.com/eunbyeol-cho/RawMed.
MD-ViSCo: A Unified Model for Multi-Directional Vital Sign Waveform Conversion
Jun 10, 2025Despite the remarkable progress of deep-learning methods generating a target vital sign waveform from a source vital sign waveform, most existing models are designed exclusively for a specific source-to-target pair. This requires distinct model architectures, optimization procedures, and pre-processing pipelines, resulting in multiple models that hinder usability in clinical settings. To address this limitation, we propose the Multi-Directional Vital-Sign Converter (MD-ViSCo), a unified framework capable of generating any target waveform such as electrocardiogram (ECG), photoplethysmogram (PPG), or arterial blood pressure (ABP) from any single input waveform with a single model. MD-ViSCo employs a shallow 1-Dimensional U-Net integrated with a Swin Transformer that leverages Adaptive Instance Normalization (AdaIN) to capture distinct waveform styles. To evaluate the efficacy of MD-ViSCo, we conduct multi-directional waveform generation on two publicly available datasets. Our framework surpasses state-of-the-art baselines (NabNet & PPG2ABP) on average across all waveform types, lowering Mean absolute error (MAE) by 8.8% and improving Pearson correlation (PC) by 4.9% over two datasets. In addition, the generated ABP waveforms satisfy the Association for the Advancement of Medical Instrumentation (AAMI) criterion and achieve Grade B on the British Hypertension Society (BHS) standard, outperforming all baselines. By eliminating the need for developing a distinct model for each task, we believe that this work offers a unified framework that can deal with any kind of vital sign waveforms with a single model in healthcare monitoring.
Lunguage: A Benchmark for Structured and Sequential Chest X-ray Interpretation
May 27, 2025Radiology reports convey detailed clinical observations and capture diagnostic reasoning that evolves over time. However, existing evaluation methods are limited to single-report settings and rely on coarse metrics that fail to capture fine-grained clinical semantics and temporal dependencies. We introduce LUNGUAGE,a benchmark dataset for structured radiology report generation that supports both single-report evaluation and longitudinal patient-level assessment across multiple studies. It contains 1,473 annotated chest X-ray reports, each reviewed by experts, and 80 of them contain longitudinal annotations to capture disease progression and inter-study intervals, also reviewed by experts. Using this benchmark, we develop a two-stage framework that transforms generated reports into fine-grained, schema-aligned structured representations, enabling longitudinal interpretation. We also propose LUNGUAGESCORE, an interpretable metric that compares structured outputs at the entity, relation, and attribute level while modeling temporal consistency across patient timelines. These contributions establish the first benchmark dataset, structuring framework, and evaluation metric for sequential radiology reporting, with empirical results demonstrating that LUNGUAGESCORE effectively supports structured report evaluation. The code is available at: https://github.com/SuperSupermoon/Lunguage
Trans-EnV: A Framework for Evaluating the Linguistic Robustness of LLMs Against English Varieties
May 27, 2025Large Language Models (LLMs) are predominantly evaluated on Standard American English (SAE), often overlooking the diversity of global English varieties. This narrow focus may raise fairness concerns as degraded performance on non-standard varieties can lead to unequal benefits for users worldwide. Therefore, it is critical to extensively evaluate the linguistic robustness of LLMs on multiple non-standard English varieties. We introduce Trans-EnV, a framework that automatically transforms SAE datasets into multiple English varieties to evaluate the linguistic robustness. Our framework combines (1) linguistics expert knowledge to curate variety-specific features and transformation guidelines from linguistic literature and corpora, and (2) LLM-based transformations to ensure both linguistic validity and scalability. Using Trans-EnV, we transform six benchmark datasets into 38 English varieties and evaluate seven state-of-the-art LLMs. Our results reveal significant performance disparities, with accuracy decreasing by up to 46.3% on non-standard varieties. These findings highlight the importance of comprehensive linguistic robustness evaluation across diverse English varieties. Each construction of Trans-EnV was validated through rigorous statistical testing and consultation with a researcher in the field of second language acquisition, ensuring its linguistic validity. Our \href{https://github.com/jiyounglee-0523/TransEnV}{code} and \href{https://huggingface.co/collections/jiyounglee0523/transenv-681eadb3c0c8cf363b363fb1}{datasets} are publicly available.
PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions
May 23, 2025
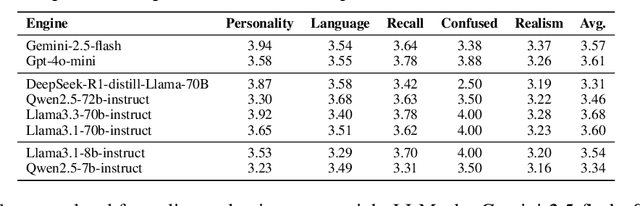
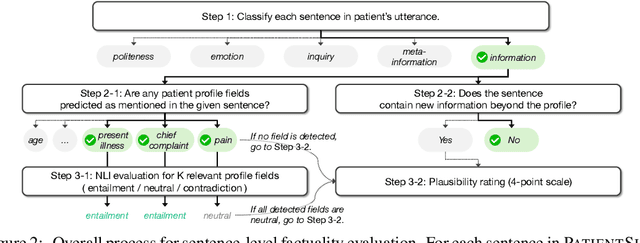
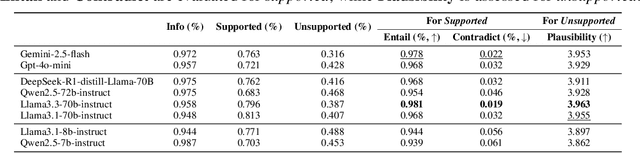
Doctor-patient consultations require multi-turn, context-aware communication tailored to diverse patient personas. Training or evaluating doctor LLMs in such settings requires realistic patient interaction systems. However, existing simulators often fail to reflect the full range of personas seen in clinical practice. To address this, we introduce PatientSim, a patient simulator that generates realistic and diverse patient personas for clinical scenarios, grounded in medical expertise. PatientSim operates using: 1) clinical profiles, including symptoms and medical history, derived from real-world data in the MIMIC-ED and MIMIC-IV datasets, and 2) personas defined by four axes: personality, language proficiency, medical history recall level, and cognitive confusion level, resulting in 37 unique combinations. We evaluated eight LLMs for factual accuracy and persona consistency. The top-performing open-source model, Llama 3.3, was validated by four clinicians to confirm the robustness of our framework. As an open-source, customizable platform, PatientSim provides a reproducible and scalable solution that can be customized for specific training needs. Offering a privacy-compliant environment, it serves as a robust testbed for evaluating medical dialogue systems across diverse patient presentations and shows promise as an educational tool for healthcare.
CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays
May 23, 2025Recent progress in Large Vision-Language Models (LVLMs) has enabled promising applications in medical tasks, such as report generation and visual question answering. However, existing benchmarks focus mainly on the final diagnostic answer, offering limited insight into whether models engage in clinically meaningful reasoning. To address this, we present CheXStruct and CXReasonBench, a structured pipeline and benchmark built on the publicly available MIMIC-CXR-JPG dataset. CheXStruct automatically derives a sequence of intermediate reasoning steps directly from chest X-rays, such as segmenting anatomical regions, deriving anatomical landmarks and diagnostic measurements, computing diagnostic indices, and applying clinical thresholds. CXReasonBench leverages this pipeline to evaluate whether models can perform clinically valid reasoning steps and to what extent they can learn from structured guidance, enabling fine-grained and transparent assessment of diagnostic reasoning. The benchmark comprises 18,988 QA pairs across 12 diagnostic tasks and 1,200 cases, each paired with up to 4 visual inputs, and supports multi-path, multi-stage evaluation including visual grounding via anatomical region selection and diagnostic measurements. Even the strongest of 10 evaluated LVLMs struggle with structured reasoning and generalization, often failing to link abstract knowledge with anatomically grounded visual interpretation. The code is available at https://github.com/ttumyche/CXReasonBench