 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLOVA: Global and Local Variation-Aware Analog Circuit Design with Risk-Sensitive Reinforcement Learning
May 16, 2025Analog/mixed-signal circuit design encounters significant challenges due to performance degradation from process, voltage, and temperature (PVT) variations. To achieve commercial-grade reliability, iterative manual design revisions and extensive statistical simulations are required. While several studies have aimed to automate variation aware analog design to reduce time-to-market, the substantial mismatches in real-world wafers have not been thoroughly addressed. In this paper, we present GLOVA, an analog circuit sizing framework that effectively manages the impact of diverse random mismatches to improve robustness against PVT variations. In the proposed approach, risk-sensitive reinforcement learning is leveraged to account for the reliability bound affected by PVT variations, and ensemble-based critic is introduced to achieve sample-efficient learning. For design verification, we also propose $\mu$-$\sigma$ evaluation and simulation reordering method to reduce simulation costs of identifying failed designs. GLOVA supports verification through industrial-level PVT variation evaluation methods, including corner simulation as well as global and local Monte Carlo (MC) simulations. Compared to previous state-of-the-art variation-aware analog sizing frameworks, GLOVA achieves up to 80.5$\times$ improvement in sample efficiency and 76.0$\times$ reduction in time.
Bottom-up Iterative Anomalous Diffusion Detector (BI-ADD)
Mar 14, 2025In recent years, the segmentation of short molecular trajectories with varying diffusive properties has drawn particular attention of researchers, since it allows studying the dynamics of a particle. In the past decade, machine learning methods have shown highly promising results, also in changepoint detection and segmentation tasks. Here, we introduce a novel iterative method to identify the changepoints in a molecular trajectory, i.e., frames, where the diffusive behavior of a particle changes. A trajectory in our case follows a fractional Brownian motion and we estimate the diffusive properties of the trajectories. The proposed BI-ADD combines unsupervised and supervised learning methods to detect the changepoints. Our approach can be used for the analysis of molecular trajectories at the individual level and also be extended to multiple particle tracking, which is an important challenge in fundamental biology. We validated BI-ADD in various scenarios within the framework of the AnDi2 Challenge 2024 dedicated to single particle tracking. Our method is implemented in Python and is publicly available for research purposes.
Forecasting Future International Events: A Reliable Dataset for Text-Based Event Modeling
Nov 21, 2024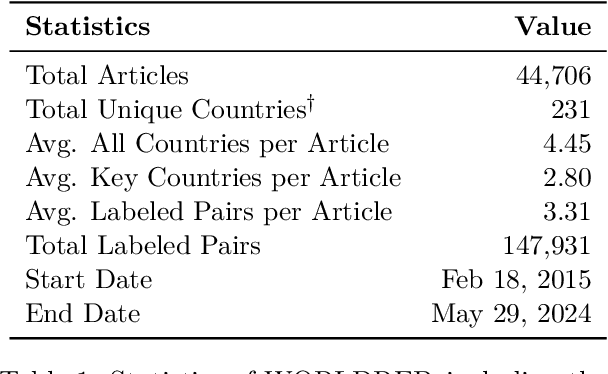
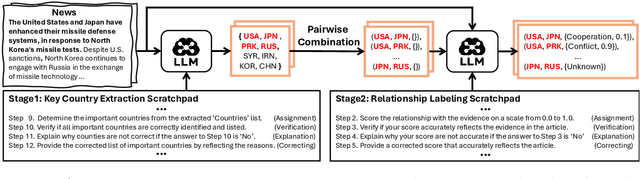

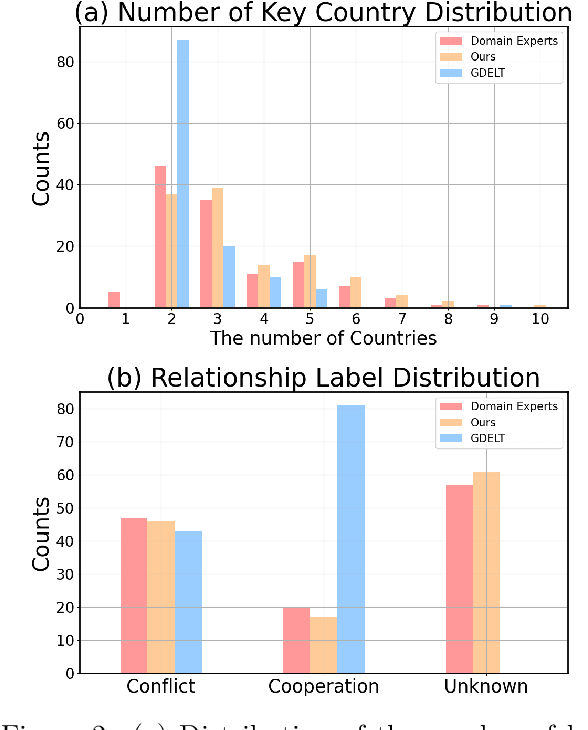
Predicting future international events from textual information, such as news articles, has tremendous potential for applications in global policy, strategic decision-making, and geopolitics. However, existing datasets available for this task are often limited in quality, hindering the progress of related research. In this paper, we introduce WORLDREP (WORLD Relationship and Event Prediction), a novel dataset designed to address these limitations by leveraging the advanced reasoning capabilities of large-language models (LLMs). Our dataset features high-quality scoring labels generated through advanced prompt modeling and rigorously validated by domain experts in political science. We showcase the quality and utility of WORLDREP for real-world event prediction tasks, demonstrating its effectiveness through extensive experiments and analysis. Furthermore, we publicly release our dataset along with the full automation source code for data collection, labeling, and benchmarking, aiming to support and advance research in text-based event prediction.
Self-Supervised Contrastive Forecasting
Feb 03, 2024
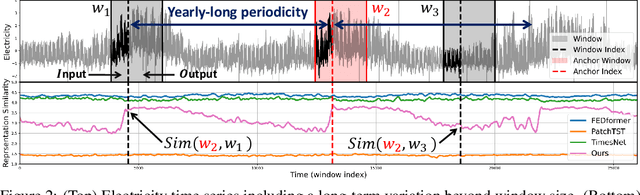
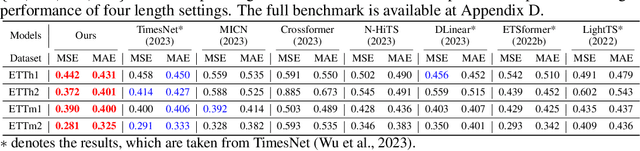

Long-term forecasting presents unique challenges due to the time and memory complexity of handling long sequences. Existing methods, which rely on sliding windows to process long sequences, struggle to effectively capture long-term variations that are partially caught within the short window (i.e., outer-window variations). In this paper, we introduce a novel approach that overcomes this limitation by employing contrastive learning and enhanced decomposition architecture, specifically designed to focus on long-term variations. To this end, our contrastive loss incorporates global autocorrelation held in the whole time series, which facilitates the construction of positive and negative pairs in a self-supervised manner. When combined with our decomposition networks, our contrastive learning significantly improves long-term forecasting performance. Extensive experiments demonstrate that our approach outperforms 14 baseline models in multiple experiments over nine long-term benchmarks, especially in challenging scenarios that require a significantly long output for forecasting. Source code is available at https://github.com/junwoopark92/Self-Supervised-Contrastive-Forecsating.
Deep Imbalanced Time-series Forecasting via Local Discrepancy Density
Feb 27, 2023



Time-series forecasting models often encounter abrupt changes in a given period of time which generally occur due to unexpected or unknown events. Despite their scarce occurrences in the training set, abrupt changes incur loss that significantly contributes to the total loss. Therefore, they act as noisy training samples and prevent the model from learning generalizable patterns, namely the normal states. Based on our findings, we propose a reweighting framework that down-weights the losses incurred by abrupt changes and up-weights those by normal states. For the reweighting framework, we first define a measurement termed Local Discrepancy (LD) which measures the degree of abruptness of a change in a given period of time. Since a training set is mostly composed of normal states, we then consider how frequently the temporal changes appear in the training set based on LD. Our reweighting framework is applicable to existing time-series forecasting models regardless of the architectures. Through extensive experiments on 12 time-series forecasting models over eight datasets with various in-output sequence lengths, we demonstrate that applying our reweighting framework reduces MSE by 10.1% on average and by up to 18.6% in the state-of-the-art model.
Enemy Spotted: in-game gun sound dataset for gunshot classification and localization
Oct 12, 2022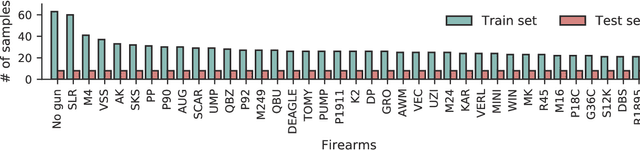
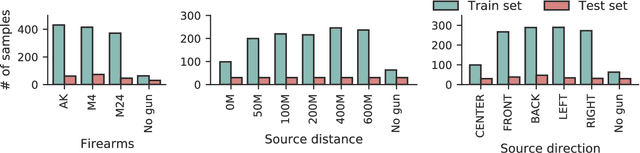
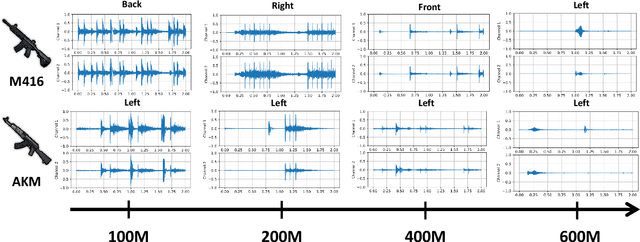
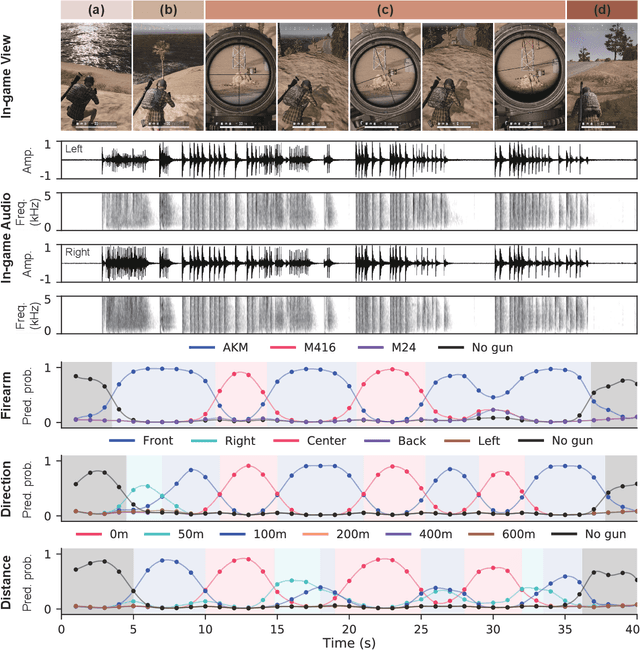
Recently, deep learning-based methods have drawn huge attention due to their simple yet high performance without domain knowledge in sound classification and localization tasks. However, a lack of gun sounds in existing datasets has been a major obstacle to implementing a support system to spot criminals from their gunshots by leveraging deep learning models. Since the occurrence of gunshot is rare and unpredictable, it is impractical to collect gun sounds in the real world. As an alternative, gun sounds can be obtained from an FPS game that is designed to mimic real-world warfare. The recent FPS game offers a realistic environment where we can safely collect gunshot data while simulating even dangerous situations. By exploiting the advantage of the game environment, we construct a gunshot dataset, namely BGG, for the firearm classification and gunshot localization tasks. The BGG dataset consists of 37 different types of firearms, distances, and directions between the sound source and a receiver. We carefully verify that the in-game gunshot data has sufficient information to identify the location and type of gunshots by training several sound classification and localization baselines on the BGG dataset. Afterward, we demonstrate that the accuracy of real-world firearm classification and localization tasks can be enhanced by utilizing the BGG dataset.
Knowledge Graph-based Question Answering with Electronic Health Records
Oct 19, 2020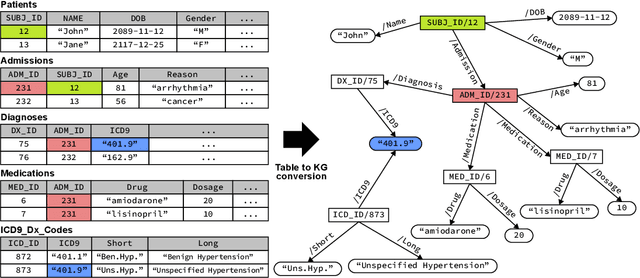

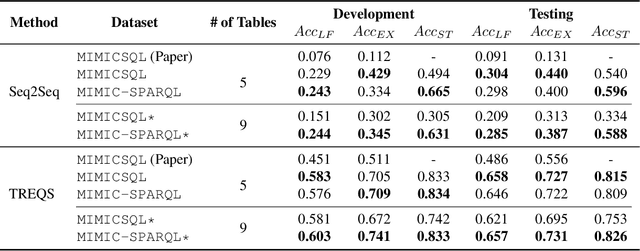

Question Answering (QA) on Electronic Health Records (EHR), namely EHR QA, can work as a crucial milestone towards developing an intelligent agent in healthcare. EHR data are typically stored in a relational database, which can also be converted to a Directed Acyclic Graph (DAG), allowing two approaches for EHR QA: Table-based QA and Knowledge Graph-based QA. We hypothesize that the graph-based approach is more suitable for EHR QA as graphs can represent relations between entities and values more naturally compared to tables, which essentially require JOIN operations. To validate our hypothesis, we first construct EHR QA datasets based on MIMIC-III, where the same question-answer pairs are represented in SQL (table-based) and SPARQL (graph-based), respectively. We then test a state-of-the-art EHR QA model on both datasets where the model demonstrated superior QA performance on the SPARQL version. Finally, we open-source both MIMICSQL* and MIMIC-SPARQL* to encourage further EHR QA research in both direction
What and Where to Translate: Local Mask-based Image-to-Image Translation
Jun 09, 2019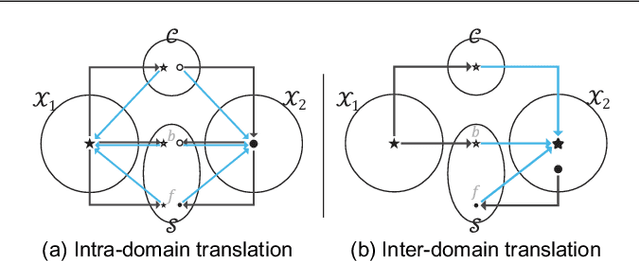
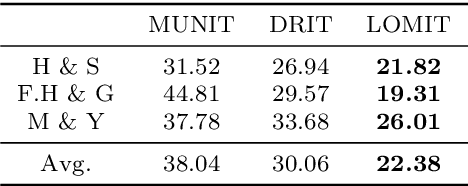
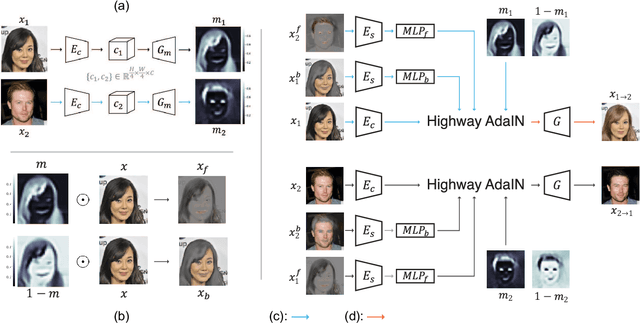

Recently, image-to-image translation has obtained significant attention. Among many, those approaches based on an exemplar image that contains the target style information has been actively studied, due to its capability to handle multimodality as well as its applicability in practical use. However, two intrinsic problems exist in the existing methods: what and where to transfer. First, those methods extract style from an entire exemplar which includes noisy information, which impedes a translation model from properly extracting the intended style of the exemplar. That is, we need to carefully determine what to transfer from the exemplar. Second, the extracted style is applied to the entire input image, which causes unnecessary distortion in irrelevant image regions. In response, we need to decide where to transfer the extracted style. In this paper, we propose a novel approach that extracts out a local mask from the exemplar that determines what style to transfer, and another local mask from the input image that determines where to transfer the extracted style. The main novelty of this paper lies in (1) the highway adaptive instance normalization technique and (2) an end-to-end translation framework which achieves an outstanding performance in reflecting a style of an exemplar. We demonstrate the quantitative and qualitative evaluation results to confirm the advantages of our proposed approach.