 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Imbalanced Time-series Forecasting via Local Discrepancy Density
Feb 27, 2023



Time-series forecasting models often encounter abrupt changes in a given period of time which generally occur due to unexpected or unknown events. Despite their scarce occurrences in the training set, abrupt changes incur loss that significantly contributes to the total loss. Therefore, they act as noisy training samples and prevent the model from learning generalizable patterns, namely the normal states. Based on our findings, we propose a reweighting framework that down-weights the losses incurred by abrupt changes and up-weights those by normal states. For the reweighting framework, we first define a measurement termed Local Discrepancy (LD) which measures the degree of abruptness of a change in a given period of time. Since a training set is mostly composed of normal states, we then consider how frequently the temporal changes appear in the training set based on LD. Our reweighting framework is applicable to existing time-series forecasting models regardless of the architectures. Through extensive experiments on 12 time-series forecasting models over eight datasets with various in-output sequence lengths, we demonstrate that applying our reweighting framework reduces MSE by 10.1% on average and by up to 18.6% in the state-of-the-art model.
EHRSQL: A Practical Text-to-SQL Benchmark for Electronic Health Records
Jan 16, 2023



We present a new text-to-SQL dataset for electronic health records (EHRs). The utterances were collected from 222 hospital staff, including physicians, nurses, insurance review and health records teams, and more. To construct the QA dataset on structured EHR data, we conducted a poll at a university hospital and templatized the responses to create seed questions. Then, we manually linked them to two open-source EHR databases, MIMIC-III and eICU, and included them with various time expressions and held-out unanswerable questions in the dataset, which were all collected from the poll. Our dataset poses a unique set of challenges: the model needs to 1) generate SQL queries that reflect a wide range of needs in the hospital, including simple retrieval and complex operations such as calculating survival rate, 2) understand various time expressions to answer time-sensitive questions in healthcare, and 3) distinguish whether a given question is answerable or unanswerable based on the prediction confidence. We believe our dataset, EHRSQL, could serve as a practical benchmark to develop and assess QA models on structured EHR data and take one step further towards bridging the gap between text-to-SQL research and its real-life deployment in healthcare. EHRSQL is available at https://github.com/glee4810/EHRSQL.
Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation
Dec 01, 2021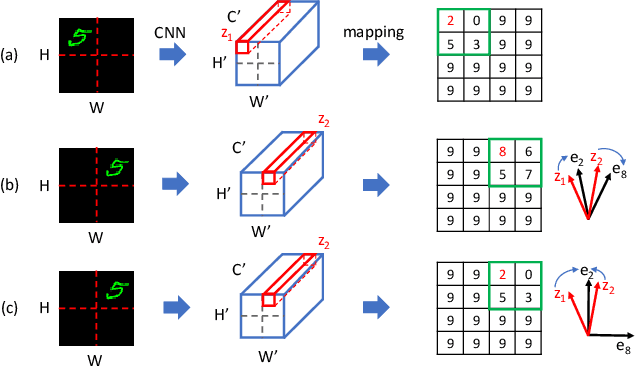
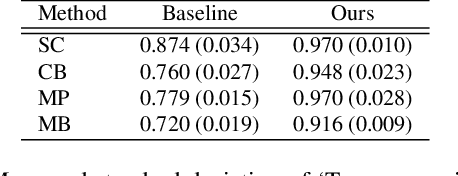
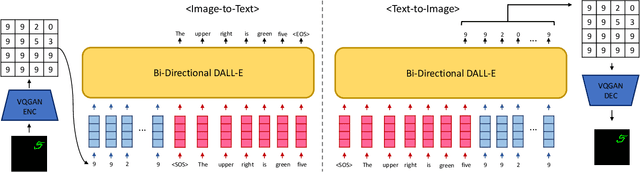

Recently, vector-quantized image modeling has demonstrated impressive performance on generation tasks such as text-to-image generation. However, we discover that the current image quantizers do not satisfy translation equivariance in the quantized space due to aliasing, degrading performance in the downstream text-to-image generation and image-to-text generation, even in simple experimental setups. Instead of focusing on anti-aliasing, we take a direct approach to encourage translation equivariance in the quantized space. In particular, we explore a desirable property of image quantizers, called 'Translation Equivariance in the Quantized Space' and propose a simple but effective way to achieve translation equivariance by regularizing orthogonality in the codebook embedding vectors. Using this method, we improve accuracy by +22% in text-to-image generation and +26% in image-to-text generation, outperforming the VQGAN.
Multi-modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training
May 24, 2021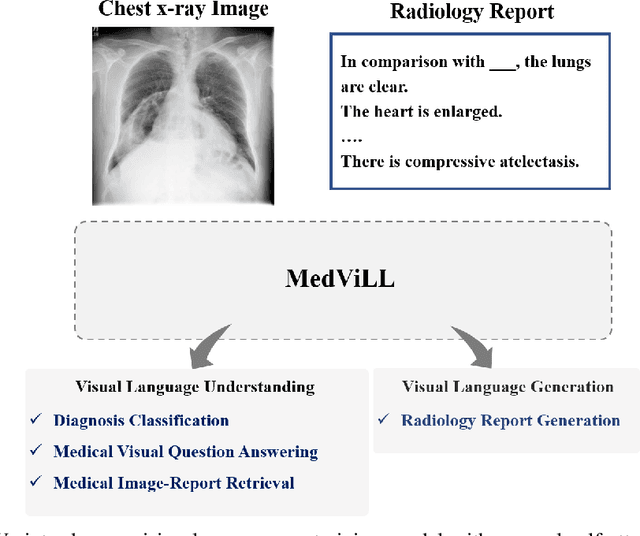

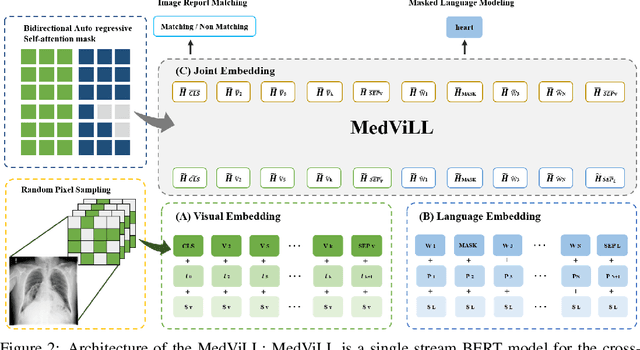
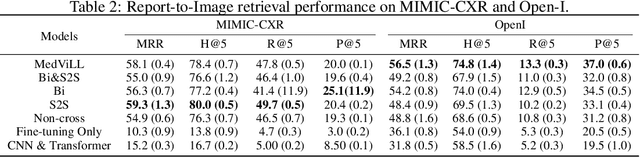
Recently a number of studies demonstrated impressive performance on diverse vision-language multi-modal tasks such as image captioning and visual question answering by extending the BERT architecture with multi-modal pre-training objectives. In this work we explore a broad set of multi-modal representation learning tasks in the medical domain, specifically using radiology images and the unstructured report. We propose Medical Vision Language Learner (MedViLL) which adopts a Transformer-based architecture combined with a novel multimodal attention masking scheme to maximize generalization performance for both vision-language understanding tasks (image-report retrieval, disease classification, medical visual question answering) and vision-language generation task (report generation). By rigorously evaluating the proposed model on four downstream tasks with two chest X-ray image datasets (MIMIC-CXR and Open-I), we empirically demonstrate the superior downstream task performance of MedViLL against various baselines including task-specific architectures.