 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErasing Your Voice Before It's Heard: Training-free Speaker Unlearning for Zero-shot Text-to-Speech
Jan 28, 2026Modern zero-shot text-to-speech (TTS) models offer unprecedented expressivity but also pose serious crime risks, as they can synthesize voices of individuals who never consented. In this context, speaker unlearning aims to prevent the generation of specific speaker identities upon request. Existing approaches, reliant on retraining, are costly and limited to speakers seen in the training set. We present TruS, a training-free speaker unlearning framework that shifts the paradigm from data deletion to inference-time control. TruS steers identity-specific hidden activations to suppress target speakers while preserving other attributes (e.g., prosody and emotion). Experimental results show that TruS effectively prevents voice generation on both seen and unseen opt-out speakers, establishing a scalable safeguard for speech synthesis. The demo and code are available on http://mmai.ewha.ac.kr/trus.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
CountSteer: Steering Attention for Object Counting in Diffusion Models
Nov 14, 2025Text-to-image diffusion models generate realistic and coherent images but often fail to follow numerical instructions in text, revealing a gap between language and visual representation. Interestingly, we found that these models are not entirely blind to numbers-they are implicitly aware of their own counting accuracy, as their internal signals shift in consistent ways depending on whether the output meets the specified count. This observation suggests that the model already encodes a latent notion of numerical correctness, which can be harnessed to guide generation more precisely. Building on this intuition, we introduce CountSteer, a training-free method that improves generation of specified object counts by steering the model's cross-attention hidden states during inference. In our experiments, CountSteer improved object-count accuracy by about 4% without compromising visual quality, demonstrating a simple yet effective step toward more controllable and semantically reliable text-to-image generation.
Seeing What You Say: Expressive Image Generation from Speech
Nov 05, 2025This paper proposes VoxStudio, the first unified and end-to-end speech-to-image model that generates expressive images directly from spoken descriptions by jointly aligning linguistic and paralinguistic information. At its core is a speech information bottleneck (SIB) module, which compresses raw speech into compact semantic tokens, preserving prosody and emotional nuance. By operating directly on these tokens, VoxStudio eliminates the need for an additional speech-to-text system, which often ignores the hidden details beyond text, e.g., tone or emotion. We also release VoxEmoset, a large-scale paired emotional speech-image dataset built via an advanced TTS engine to affordably generate richly expressive utterances. Comprehensive experiments on the SpokenCOCO, Flickr8kAudio, and VoxEmoset benchmarks demonstrate the feasibility of our method and highlight key challenges, including emotional consistency and linguistic ambiguity, paving the way for future research.
Referee: Reference-aware Audiovisual Deepfake Detection
Oct 31, 2025Since deepfakes generated by advanced generative models have rapidly posed serious threats, existing audiovisual deepfake detection approaches struggle to generalize to unseen forgeries. We propose a novel reference-aware audiovisual deepfake detection method, called Referee. Speaker-specific cues from only one-shot examples are leveraged to detect manipulations beyond spatiotemporal artifacts. By matching and aligning identity-related queries from reference and target content into cross-modal features, Referee jointly reasons about audiovisual synchrony and identity consistency. Extensive experiments on FakeAVCeleb, FaceForensics++, and KoDF demonstrate that Referee achieves state-of-the-art performance on cross-dataset and cross-language evaluation protocols. Experimental results highlight the importance of cross-modal identity verification for future deepfake detection. The code is available at https://github.com/ewha-mmai/referee.
Trans-EnV: A Framework for Evaluating the Linguistic Robustness of LLMs Against English Varieties
May 27, 2025Large Language Models (LLMs) are predominantly evaluated on Standard American English (SAE), often overlooking the diversity of global English varieties. This narrow focus may raise fairness concerns as degraded performance on non-standard varieties can lead to unequal benefits for users worldwide. Therefore, it is critical to extensively evaluate the linguistic robustness of LLMs on multiple non-standard English varieties. We introduce Trans-EnV, a framework that automatically transforms SAE datasets into multiple English varieties to evaluate the linguistic robustness. Our framework combines (1) linguistics expert knowledge to curate variety-specific features and transformation guidelines from linguistic literature and corpora, and (2) LLM-based transformations to ensure both linguistic validity and scalability. Using Trans-EnV, we transform six benchmark datasets into 38 English varieties and evaluate seven state-of-the-art LLMs. Our results reveal significant performance disparities, with accuracy decreasing by up to 46.3% on non-standard varieties. These findings highlight the importance of comprehensive linguistic robustness evaluation across diverse English varieties. Each construction of Trans-EnV was validated through rigorous statistical testing and consultation with a researcher in the field of second language acquisition, ensuring its linguistic validity. Our \href{https://github.com/jiyounglee-0523/TransEnV}{code} and \href{https://huggingface.co/collections/jiyounglee0523/transenv-681eadb3c0c8cf363b363fb1}{datasets} are publicly available.
Bootstrap Your Own Views: Masked Ego-Exo Modeling for Fine-grained View-invariant Video Representations
Mar 25, 2025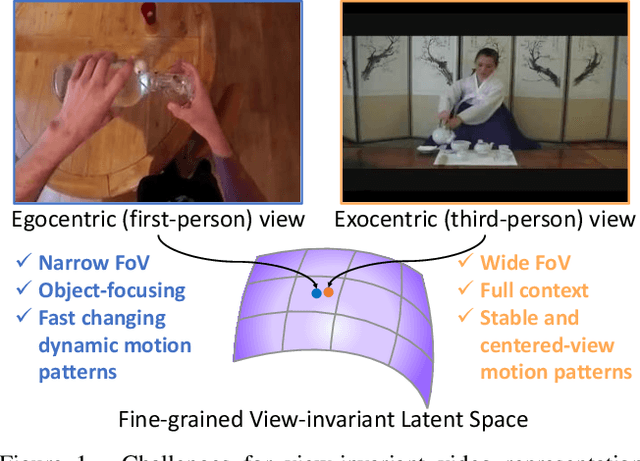
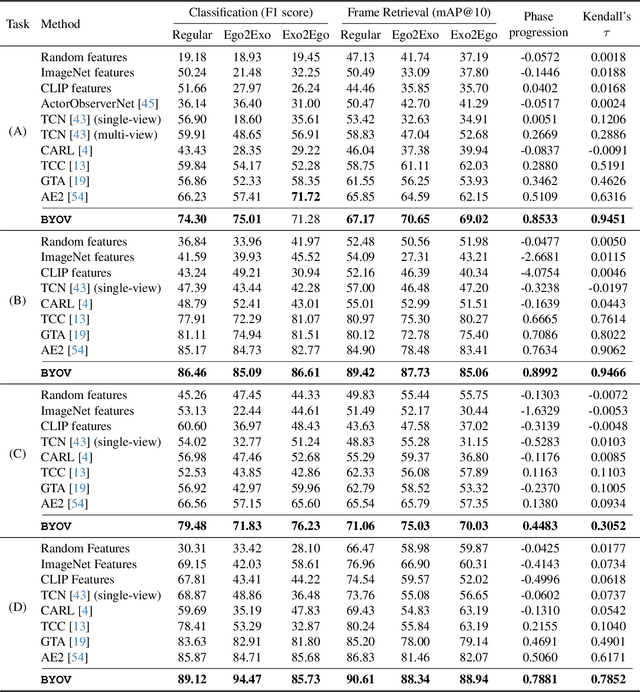
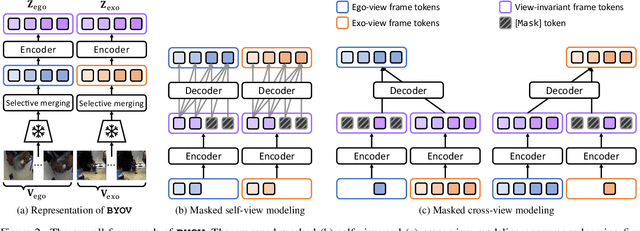

View-invariant representation learning from egocentric (first-person, ego) and exocentric (third-person, exo) videos is a promising approach toward generalizing video understanding systems across multiple viewpoints. However, this area has been underexplored due to the substantial differences in perspective, motion patterns, and context between ego and exo views. In this paper, we propose a novel masked ego-exo modeling that promotes both causal temporal dynamics and cross-view alignment, called Bootstrap Your Own Views (BYOV), for fine-grained view-invariant video representation learning from unpaired ego-exo videos. We highlight the importance of capturing the compositional nature of human actions as a basis for robust cross-view understanding. Specifically, self-view masking and cross-view masking predictions are designed to learn view-invariant and powerful representations concurrently. Experimental results demonstrate that our BYOV significantly surpasses existing approaches with notable gains across all metrics in four downstream ego-exo video tasks. The code is available at https://github.com/park-jungin/byov.
Single Ground Truth Is Not Enough: Add Linguistic Variability to Aspect-based Sentiment Analysis Evaluation
Oct 13, 2024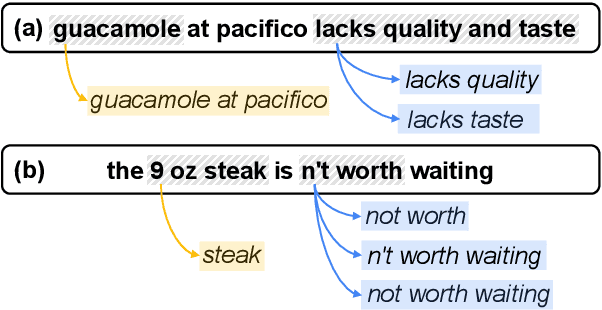
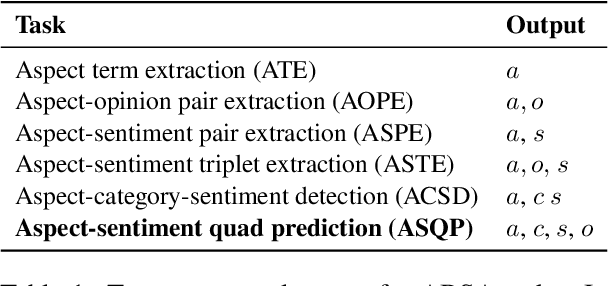
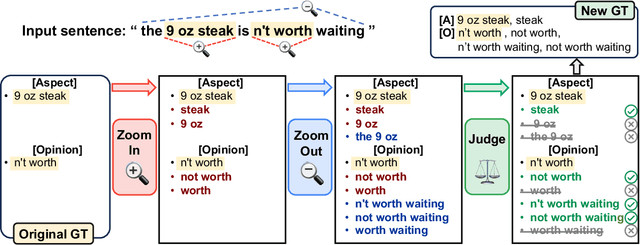
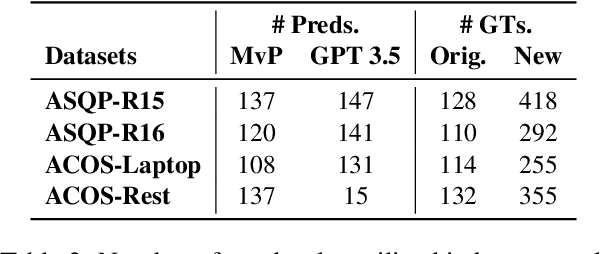
Aspect-based sentiment analysis (ABSA) is the challenging task of extracting sentiment along with its corresponding aspects and opinions from human language. Due to the inherent variability of natural language, aspect and opinion terms can be expressed in various surface forms, making their accurate identification complex. Current evaluation methods for this task often restrict answers to a single ground truth, penalizing semantically equivalent predictions that differ in surface form. To address this limitation, we propose a novel, fully automated pipeline that augments existing test sets with alternative valid responses for aspect and opinion terms. This approach enables a fairer assessment of language models by accommodating linguistic diversity, resulting in higher human agreement than single-answer test sets (up to 10%p improvement in Kendall's Tau score). Our experimental results demonstrate that Large Language Models (LLMs) show substantial performance improvements over T5 models when evaluated using our augmented test set, suggesting that LLMs' capabilities in ABSA tasks may have been underestimated. This work contributes to a more comprehensive evaluation framework for ABSA, potentially leading to more accurate assessments of model performance in information extraction tasks, particularly those involving span extraction.
Read, Watch and Scream! Sound Generation from Text and Video
Jul 08, 2024
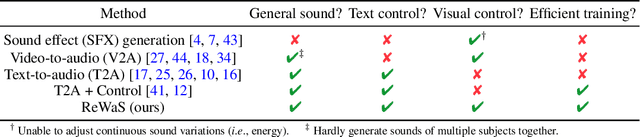


Multimodal generative models have shown impressive advances with the help of powerful diffusion models. Despite the progress, generating sound solely from text poses challenges in ensuring comprehensive scene depiction and temporal alignment. Meanwhile, video-to-sound generation limits the flexibility to prioritize sound synthesis for specific objects within the scene. To tackle these challenges, we propose a novel video-and-text-to-sound generation method, called ReWaS, where video serves as a conditional control for a text-to-audio generation model. Our method estimates the structural information of audio (namely, energy) from the video while receiving key content cues from a user prompt. We employ a well-performing text-to-sound model to consolidate the video control, which is much more efficient for training multimodal diffusion models with massive triplet-paired (audio-video-text) data. In addition, by separating the generative components of audio, it becomes a more flexible system that allows users to freely adjust the energy, surrounding environment, and primary sound source according to their preferences. Experimental results demonstrate that our method shows superiority in terms of quality, controllability, and training efficiency. Our demo is available at https://naver-ai.github.io/rewas
Bridging Vision and Language Spaces with Assignment Prediction
Apr 15, 2024This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.