 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaPa: Carve-n-Paint Synthesis for Efficient 4K Textured Mesh Generation
Jan 16, 2025The synthesis of high-quality 3D assets from textual or visual inputs has become a central objective in modern generative modeling. Despite the proliferation of 3D generation algorithms, they frequently grapple with challenges such as multi-view inconsistency, slow generation times, low fidelity, and surface reconstruction problems. While some studies have addressed some of these issues, a comprehensive solution remains elusive. In this paper, we introduce \textbf{CaPa}, a carve-and-paint framework that generates high-fidelity 3D assets efficiently. CaPa employs a two-stage process, decoupling geometry generation from texture synthesis. Initially, a 3D latent diffusion model generates geometry guided by multi-view inputs, ensuring structural consistency across perspectives. Subsequently, leveraging a novel, model-agnostic Spatially Decoupled Attention, the framework synthesizes high-resolution textures (up to 4K) for a given geometry. Furthermore, we propose a 3D-aware occlusion inpainting algorithm that fills untextured regions, resulting in cohesive results across the entire model. This pipeline generates high-quality 3D assets in less than 30 seconds, providing ready-to-use outputs for commercial applications. Experimental results demonstrate that CaPa excels in both texture fidelity and geometric stability, establishing a new standard for practical, scalable 3D asset generation.
Panoramic Image-to-Image Translation
Apr 11, 2023



In this paper, we tackle the challenging task of Panoramic Image-to-Image translation (Pano-I2I) for the first time. This task is difficult due to the geometric distortion of panoramic images and the lack of a panoramic image dataset with diverse conditions, like weather or time. To address these challenges, we propose a panoramic distortion-aware I2I model that preserves the structure of the panoramic images while consistently translating their global style referenced from a pinhole image. To mitigate the distortion issue in naive 360 panorama translation, we adopt spherical positional embedding to our transformer encoders, introduce a distortion-free discriminator, and apply sphere-based rotation for augmentation and its ensemble. We also design a content encoder and a style encoder to be deformation-aware to deal with a large domain gap between panoramas and pinhole images, enabling us to work on diverse conditions of pinhole images. In addition, considering the large discrepancy between panoramas and pinhole images, our framework decouples the learning procedure of the panoramic reconstruction stage from the translation stage. We show distinct improvements over existing I2I models in translating the StreetLearn dataset in the daytime into diverse conditions. The code will be publicly available online for our community.
Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Mar 05, 2023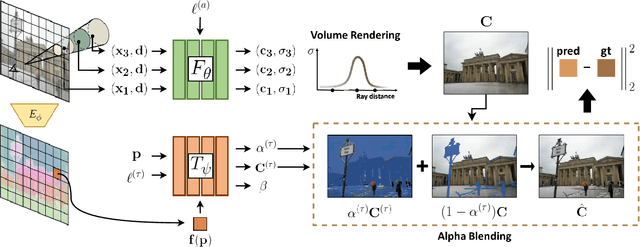
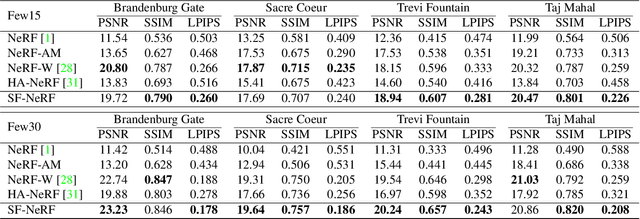

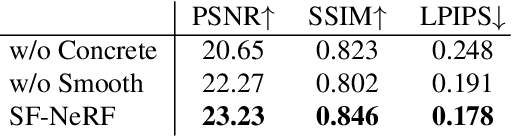
We present a learning framework for reconstructing neural scene representations from a small number of unconstrained tourist photos. Since each image contains transient occluders, decomposing the static and transient components is necessary to construct radiance fields with such in-the-wild photographs where existing methods require a lot of training data. We introduce SF-NeRF, aiming to disentangle those two components with only a few images given, which exploits semantic information without any supervision. The proposed method contains an occlusion filtering module that predicts the transient color and its opacity for each pixel, which enables the NeRF model to solely learn the static scene representation. This filtering module learns the transient phenomena guided by pixel-wise semantic features obtained by a trainable image encoder that can be trained across multiple scenes to learn the prior of transient objects. Furthermore, we present two techniques to prevent ambiguous decomposition and noisy results of the filtering module. We demonstrate that our method outperforms state-of-the-art novel view synthesis methods on Phototourism dataset in a few-shot setting.
Robust Camera Pose Refinement for Multi-Resolution Hash Encoding
Feb 03, 2023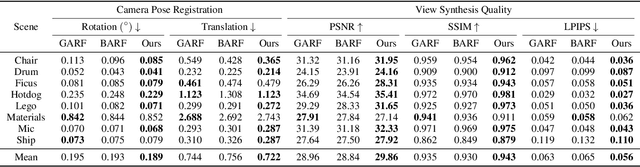
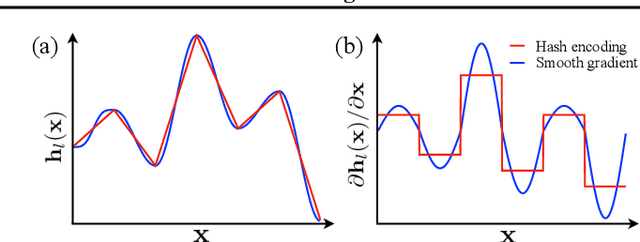
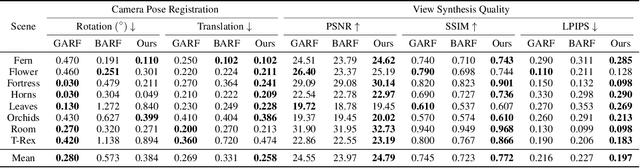
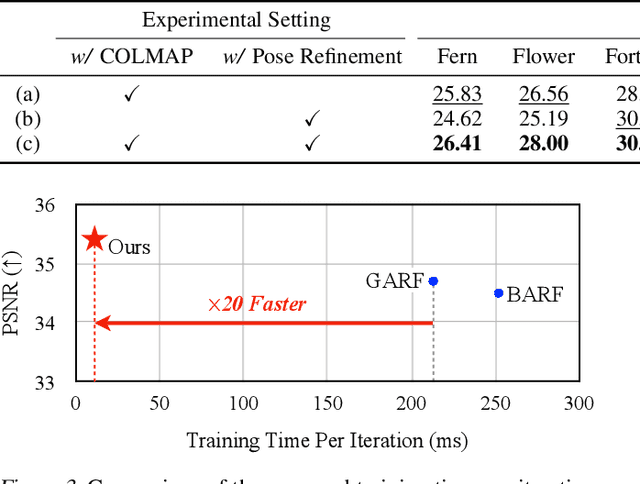
Multi-resolution hash encoding has recently been proposed to reduce the computational cost of neural renderings, such as NeRF. This method requires accurate camera poses for the neural renderings of given scenes. However, contrary to previous methods jointly optimizing camera poses and 3D scenes, the naive gradient-based camera pose refinement method using multi-resolution hash encoding severely deteriorates performance. We propose a joint optimization algorithm to calibrate the camera pose and learn a geometric representation using efficient multi-resolution hash encoding. Showing that the oscillating gradient flows of hash encoding interfere with the registration of camera poses, our method addresses the issue by utilizing smooth interpolation weighting to stabilize the gradient oscillation for the ray samplings across hash grids. Moreover, the curriculum training procedure helps to learn the level-wise hash encoding, further increasing the pose refinement. Experiments on the novel-view synthesis datasets validate that our learning frameworks achieve state-of-the-art performance and rapid convergence of neural rendering, even when initial camera poses are unknown.
Domain Generalization Emerges from Dreaming
Feb 02, 2023
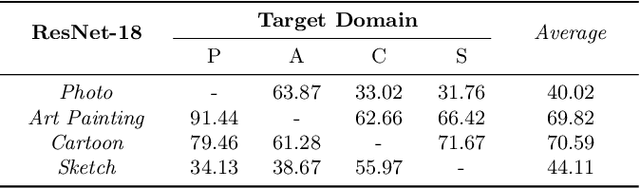


Recent studies have proven that DNNs, unlike human vision, tend to exploit texture information rather than shape. Such texture bias is one of the factors for the poor generalization performance of DNNs. We observe that the texture bias negatively affects not only in-domain generalization but also out-of-distribution generalization, i.e., Domain Generalization. Motivated by the observation, we propose a new framework to reduce the texture bias of a model by a novel optimization-based data augmentation, dubbed Stylized Dream. Our framework utilizes adaptive instance normalization (AdaIN) to augment the style of an original image yet preserve the content. We then adopt a regularization loss to predict consistent outputs between Stylized Dream and original images, which encourages the model to learn shape-based representations. Extensive experiments show that the proposed method achieves state-of-the-art performance in out-of-distribution settings on public benchmark datasets: PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet.
Consistency Learning via Decoding Path Augmentation for Transformers in Human Object Interaction Detection
Apr 11, 2022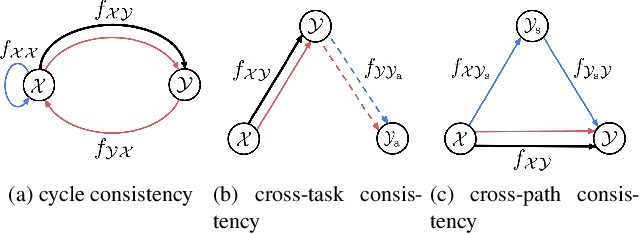
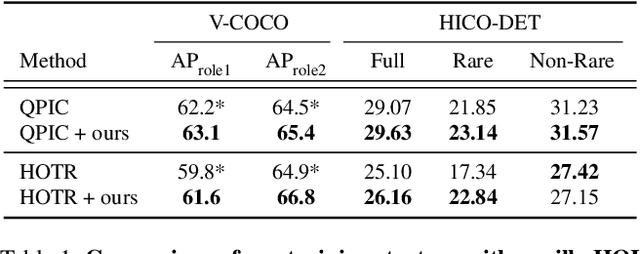
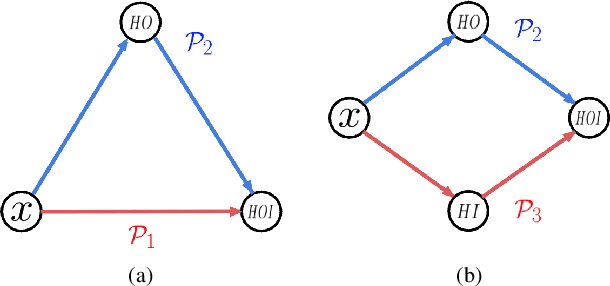
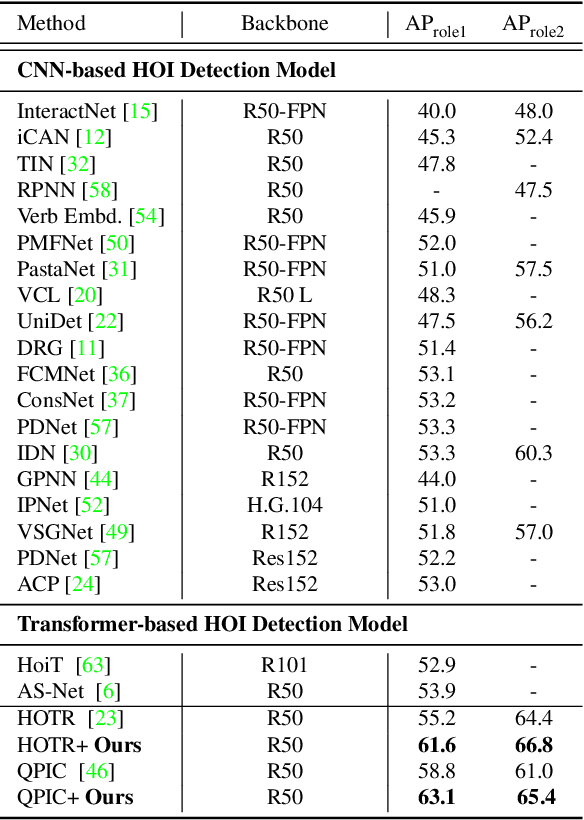
Human-Object Interaction detection is a holistic visual recognition task that entails object detection as well as interaction classification. Previous works of HOI detection has been addressed by the various compositions of subset predictions, e.g., Image -> HO -> I, Image -> HI -> O. Recently, transformer based architecture for HOI has emerged, which directly predicts the HOI triplets in an end-to-end fashion (Image -> HOI). Motivated by various inference paths for HOI detection, we propose cross-path consistency learning (CPC), which is a novel end-to-end learning strategy to improve HOI detection for transformers by leveraging augmented decoding paths. CPC learning enforces all the possible predictions from permuted inference sequences to be consistent. This simple scheme makes the model learn consistent representations, thereby improving generalization without increasing model capacity. Our experiments demonstrate the effectiveness of our method, and we achieved significant improvement on V-COCO and HICO-DET compared to the baseline models. Our code is available at https://github.com/mlvlab/CPChoi.