 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Collision Cones: Dynamic Obstacle Avoidance for Nonholonomic Robots via Dynamic Parabolic Control Barrier Functions
Oct 01, 2025Control Barrier Functions (CBFs) are a powerful tool for ensuring the safety of autonomous systems, yet applying them to nonholonomic robots in cluttered, dynamic environments remains an open challenge. State-of-the-art methods often rely on collision-cone or velocity-obstacle constraints which, by only considering the angle of the relative velocity, are inherently conservative and can render the CBF-based quadratic program infeasible, particularly in dense scenarios. To address this issue, we propose a Dynamic Parabolic Control Barrier Function (DPCBF) that defines the safe set using a parabolic boundary. The parabola's vertex and curvature dynamically adapt based on both the distance to an obstacle and the magnitude of the relative velocity, creating a less restrictive safety constraint. We prove that the proposed DPCBF is valid for a kinematic bicycle model subject to input constraints. Extensive comparative simulations demonstrate that our DPCBF-based controller significantly enhances navigation success rates and QP feasibility compared to baseline methods. Our approach successfully navigates through dense environments with up to 100 dynamic obstacles, scenarios where collision cone-based methods fail due to infeasibility.
Token Bottleneck: One Token to Remember Dynamics
Jul 09, 2025Deriving compact and temporally aware visual representations from dynamic scenes is essential for successful execution of sequential scene understanding tasks such as visual tracking and robotic manipulation. In this paper, we introduce Token Bottleneck (ToBo), a simple yet intuitive self-supervised learning pipeline that squeezes a scene into a bottleneck token and predicts the subsequent scene using minimal patches as hints. The ToBo pipeline facilitates the learning of sequential scene representations by conservatively encoding the reference scene into a compact bottleneck token during the squeeze step. In the expansion step, we guide the model to capture temporal dynamics by predicting the target scene using the bottleneck token along with few target patches as hints. This design encourages the vision backbone to embed temporal dependencies, thereby enabling understanding of dynamic transitions across scenes. Extensive experiments in diverse sequential tasks, including video label propagation and robot manipulation in simulated environments demonstrate the superiority of ToBo over baselines. Moreover, deploying our pre-trained model on physical robots confirms its robustness and effectiveness in real-world environments. We further validate the scalability of ToBo across different model scales.
BR-MPPI: Barrier Rate guided MPPI for Enforcing Multiple Inequality Constraints with Learned Signed Distance Field
Jun 08, 2025Model Predictive Path Integral (MPPI) controller is used to solve unconstrained optimal control problems and Control Barrier Function (CBF) is a tool to impose strict inequality constraints, a.k.a, barrier constraints. In this work, we propose an integration of these two methods that employ CBF-like conditions to guide the control sampling procedure of MPPI. CBFs provide an inequality constraint restricting the rate of change of barrier functions by a classK function of the barrier itself. We instead impose the CBF condition as an equality constraint by choosing a parametric linear classK function and treating this parameter as a state in an augmented system. The time derivative of this parameter acts as an additional control input that is designed by MPPI. A cost function is further designed to reignite Nagumo's theorem at the boundary of the safe set by promoting specific values of classK parameter to enforce safety. Our problem formulation results in an MPPI subject to multiple state and control-dependent equality constraints which are non-trivial to satisfy with randomly sampled control inputs. We therefore also introduce state transformations and control projection operations, inspired by the literature on path planning for manifolds, to resolve the aforementioned issue. We show empirically through simulations and experiments on quadrotor that our proposed algorithm exhibits better sampled efficiency and enhanced capability to operate closer to the safe set boundary over vanilla MPPI.
Certifiably-Correct Mapping for Safe Navigation Despite Odometry Drift
Apr 25, 2025Accurate perception, state estimation and mapping are essential for safe robotic navigation as planners and controllers rely on these components for safety-critical decisions. However, existing mapping approaches often assume perfect pose estimates, an unrealistic assumption that can lead to incorrect obstacle maps and therefore collisions. This paper introduces a framework for certifiably-correct mapping that ensures that the obstacle map correctly classifies obstacle-free regions despite the odometry drift in vision-based localization systems (VIO}/SLAM). By deflating the safe region based on the incremental odometry error at each timestep, we ensure that the map remains accurate and reliable locally around the robot, even as the overall odometry error with respect to the inertial frame grows unbounded. Our contributions include two approaches to modify popular obstacle mapping paradigms, (I) Safe Flight Corridors, and (II) Signed Distance Fields. We formally prove the correctness of both methods, and describe how they integrate with existing planning and control modules. Simulations using the Replica dataset highlight the efficacy of our methods compared to state-of-the-art techniques. Real-world experiments with a robotic rover show that, while baseline methods result in collisions with previously mapped obstacles, the proposed framework enables the rover to safely stop before potential collisions.
Safe Navigation in Uncertain Crowded Environments Using Risk Adaptive CVaR Barrier Functions
Apr 09, 2025Robot navigation in dynamic, crowded environments poses a significant challenge due to the inherent uncertainties in the obstacle model. In this work, we propose a risk-adaptive approach based on the Conditional Value-at-Risk Barrier Function (CVaR-BF), where the risk level is automatically adjusted to accept the minimum necessary risk, achieving a good performance in terms of safety and optimization feasibility under uncertainty. Additionally, we introduce a dynamic zone-based barrier function which characterizes the collision likelihood by evaluating the relative state between the robot and the obstacle. By integrating risk adaptation with this new function, our approach adaptively expands the safety margin, enabling the robot to proactively avoid obstacles in highly dynamic environments. Comparisons and ablation studies demonstrate that our method outperforms existing social navigation approaches, and validate the effectiveness of our proposed framework.
Learning to Refine Input Constrained Control Barrier Functions via Uncertainty-Aware Online Parameter Adaptation
Sep 22, 2024Control Barrier Functions (CBFs) have become powerful tools for ensuring safety in nonlinear systems. However, finding valid CBFs that guarantee persistent safety and feasibility remains an open challenge, especially in systems with input constraints. Traditional approaches often rely on manually tuning the parameters of the class K functions of the CBF conditions a priori. The performance of CBF-based controllers is highly sensitive to these fixed parameters, potentially leading to overly conservative behavior or safety violations. To overcome these issues, this paper introduces a learning-based optimal control framework for online adaptation of Input Constrained CBF (ICCBF) parameters in discrete-time nonlinear systems. Our method employs a probabilistic ensemble neural network to predict the performance and risk metrics, as defined in this work, for candidate parameters, accounting for both epistemic and aleatoric uncertainties. We propose a two-step verification process using Jensen-Renyi Divergence and distributionally-robust Conditional Value at Risk to identify valid parameters. This enables dynamic refinement of ICCBF parameters based on current state and nearby environments, optimizing performance while ensuring safety within the verified parameter set. Experimental results demonstrate that our method outperforms both fixed-parameter and existing adaptive methods in robot navigation scenarios across safety and performance metrics.
Visibility-Aware RRT* for Safety-Critical Navigation of Perception-Limited Robots in Unknown Environments
Jun 11, 2024Safe autonomous navigation in unknown environments remains a critical challenge for robots with limited sensing capabilities. While safety-critical control techniques, such as Control Barrier Functions (CBFs), have been proposed to ensure safety, their effectiveness relies on the assumption that the robot has complete knowledge of its surroundings. In reality, robots often operate with restricted field-of-view and finite sensing range, which can lead to collisions with unknown obstacles if the planning algorithm is agnostic to these limitations. To address this issue, we introduce the visibility-aware RRT* algorithm that combines sampling-based planning with CBFs to generate safe and efficient global reference paths in partially unknown environments. The algorithm incorporates a collision avoidance CBF and a novel visibility CBF, which guarantees that the robot remains within locally collision-free regions, enabling timely detection and avoidance of unknown obstacles. We conduct extensive experiments interfacing the path planners with two different safety-critical controllers, wherein our method outperforms all other compared baselines across both safety and efficiency aspects.
ActiveNeuS: Active 3D Reconstruction using Neural Implicit Surface Uncertainty
May 04, 2024Active learning in 3D scene reconstruction has been widely studied, as selecting informative training views is critical for the reconstruction. Recently, Neural Radiance Fields (NeRF) variants have shown performance increases in active 3D reconstruction using image rendering or geometric uncertainty. However, the simultaneous consideration of both uncertainties in selecting informative views remains unexplored, while utilizing different types of uncertainty can reduce the bias that arises in the early training stage with sparse inputs. In this paper, we propose ActiveNeuS, which evaluates candidate views considering both uncertainties. ActiveNeuS provides a way to accumulate image rendering uncertainty while avoiding the bias that the estimated densities can introduce. ActiveNeuS computes the neural implicit surface uncertainty, providing the color uncertainty along with the surface information. It efficiently handles the bias by using the surface information and a grid, enabling the fast selection of diverse viewpoints. Our method outperforms previous works on popular datasets, Blender and DTU, showing that the views selected by ActiveNeuS significantly improve performance.
HYPE: Hyperbolic Entailment Filtering for Underspecified Images and Texts
Apr 26, 2024In an era where the volume of data drives the effectiveness of self-supervised learning, the specificity and clarity of data semantics play a crucial role in model training. Addressing this, we introduce HYPerbolic Entailment filtering (HYPE), a novel methodology designed to meticulously extract modality-wise meaningful and well-aligned data from extensive, noisy image-text pair datasets. Our approach leverages hyperbolic embeddings and the concept of entailment cones to evaluate and filter out samples with meaningless or underspecified semantics, focusing on enhancing the specificity of each data sample. HYPE not only demonstrates a significant improvement in filtering efficiency but also sets a new state-of-the-art in the DataComp benchmark when combined with existing filtering techniques. This breakthrough showcases the potential of HYPE to refine the data selection process, thereby contributing to the development of more accurate and efficient self-supervised learning models. Additionally, the image specificity $\epsilon_{i}$ can be independently applied to induce an image-only dataset from an image-text or image-only data pool for training image-only self-supervised models and showed superior performance when compared to the dataset induced by CLIP score.
Leveraging Temporal Contextualization for Video Action Recognition
Apr 15, 2024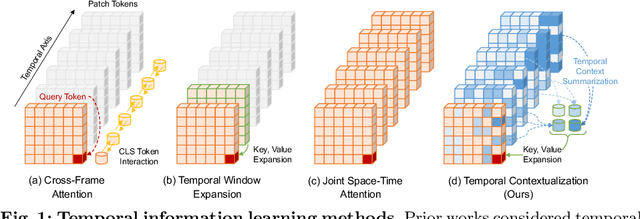
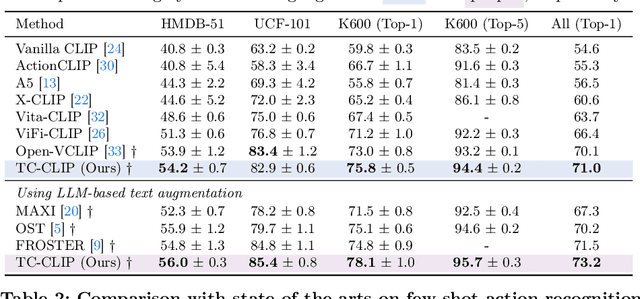
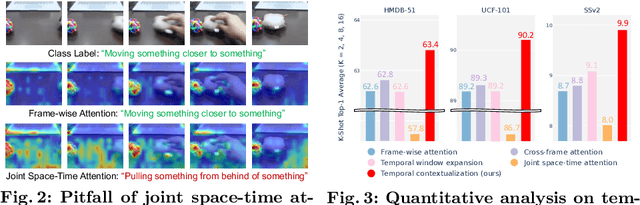
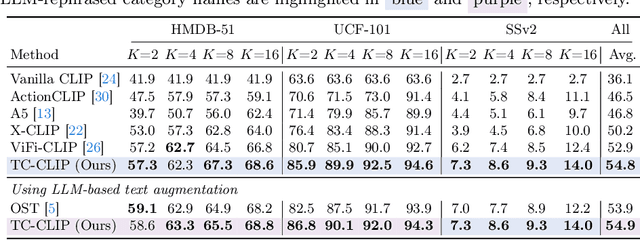
Pretrained vision-language models have shown effectiveness in video understanding. However, recent studies have not sufficiently leveraged essential temporal information from videos, simply averaging frame-wise representations or referencing consecutive frames. We introduce Temporally Contextualized CLIP (TC-CLIP), a pioneering framework for video understanding that effectively and efficiently leverages comprehensive video information. We propose Temporal Contextualization (TC), a novel layer-wise temporal information infusion mechanism for video that extracts core information from each frame, interconnects relevant information across the video to summarize into context tokens, and ultimately leverages the context tokens during the feature encoding process. Furthermore, our Video-conditional Prompting (VP) module manufactures context tokens to generate informative prompts in text modality. We conduct extensive experiments in zero-shot, few-shot, base-to-novel, and fully-supervised action recognition to validate the superiority of our TC-CLIP. Ablation studies for TC and VP guarantee our design choices. Code is available at https://github.com/naver-ai/tc-clip