 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding World Simulation Models in a Real-World Metropolis
Mar 16, 2026What if a world simulation model could render not an imagined environment but a city that actually exists? Prior generative world models synthesize visually plausible yet artificial environments by imagining all content. We present Seoul World Model (SWM), a city-scale world model grounded in the real city of Seoul. SWM anchors autoregressive video generation through retrieval-augmented conditioning on nearby street-view images. However, this design introduces several challenges, including temporal misalignment between retrieved references and the dynamic target scene, limited trajectory diversity and data sparsity from vehicle-mounted captures at sparse intervals. We address these challenges through cross-temporal pairing, a large-scale synthetic dataset enabling diverse camera trajectories, and a view interpolation pipeline that synthesizes coherent training videos from sparse street-view images. We further introduce a Virtual Lookahead Sink to stabilize long-horizon generation by continuously re-grounding each chunk to a retrieved image at a future location. We evaluate SWM against recent video world models across three cities: Seoul, Busan, and Ann Arbor. SWM outperforms existing methods in generating spatially faithful, temporally consistent, long-horizon videos grounded in actual urban environments over trajectories reaching hundreds of meters, while supporting diverse camera movements and text-prompted scenario variations.
MASEval: Extending Multi-Agent Evaluation from Models to Systems
Mar 09, 2026The rapid adoption of LLM-based agentic systems has produced a rich ecosystem of frameworks (smolagents, LangGraph, AutoGen, CAMEL, LlamaIndex, i.a.). Yet existing benchmarks are model-centric: they fix the agentic setup and do not compare other system components. We argue that implementation decisions substantially impact performance, including choices such as topology, orchestration logic, and error handling. MASEval addresses this evaluation gap with a framework-agnostic library that treats the entire system as the unit of analysis. Through a systematic system-level comparison across 3 benchmarks, 3 models, and 3 frameworks, we find that framework choice matters as much as model choice. MASEval allows researchers to explore all components of agentic systems, opening new avenues for principled system design, and practitioners to identify the best implementation for their use case. MASEval is available under the MIT licence https://github.com/parameterlab/MASEval.
ChimeraLoRA: Multi-Head LoRA-Guided Synthetic Datasets
Feb 23, 2026Beyond general recognition tasks, specialized domains including privacy-constrained medical applications and fine-grained settings often encounter data scarcity, especially for tail classes. To obtain less biased and more reliable models under such scarcity, practitioners leverage diffusion models to supplement underrepresented regions of real data. Specifically, recent studies fine-tune pretrained diffusion models with LoRA on few-shot real sets to synthesize additional images. While an image-wise LoRA trained on a single image captures fine-grained details yet offers limited diversity, a class-wise LoRA trained over all shots produces diverse images as it encodes class priors yet tends to overlook fine details. To combine both benefits, we separate the adapter into a class-shared LoRA~$A$ for class priors and per-image LoRAs~$\mathcal{B}$ for image-specific characteristics. To expose coherent class semantics in the shared LoRA~$A$, we propose a semantic boosting by preserving class bounding boxes during training. For generation, we compose $A$ with a mixture of $\mathcal{B}$ using coefficients drawn from a Dirichlet distribution. Across diverse datasets, our synthesized images are both diverse and detail-rich while closely aligning with the few-shot real distribution, yielding robust gains in downstream classification accuracy.
MuCo: Multi-turn Contrastive Learning for Multimodal Embedding Model
Feb 06, 2026Universal Multimodal embedding models built on Multimodal Large Language Models (MLLMs) have traditionally employed contrastive learning, which aligns representations of query-target pairs across different modalities. Yet, despite its empirical success, they are primarily built on a "single-turn" formulation where each query-target pair is treated as an independent data point. This paradigm leads to computational inefficiency when scaling, as it requires a separate forward pass for each pair and overlooks potential contextual relationships between multiple queries that can relate to the same context. In this work, we introduce Multi-Turn Contrastive Learning (MuCo), a dialogue-inspired framework that revisits this process. MuCo leverages the conversational nature of MLLMs to process multiple, related query-target pairs associated with a single image within a single forward pass. This allows us to extract a set of multiple query and target embeddings simultaneously, conditioned on a shared context representation, amplifying the effective batch size and overall training efficiency. Experiments exhibit MuCo with a newly curated 5M multimodal multi-turn dataset (M3T), which yields state-of-the-art retrieval performance on MMEB and M-BEIR benchmarks, while markedly enhancing both training efficiency and representation coherence across modalities. Code and M3T are available at https://github.com/naver-ai/muco
Fast KVzip: Efficient and Accurate LLM Inference with Gated KV Eviction
Jan 25, 2026Efficient key-value (KV) cache management is crucial for the practical deployment of large language models (LLMs), yet existing compression techniques often incur a trade-off between performance degradation and computational overhead. We propose a novel gating-based KV cache eviction method for frozen-weight LLMs that achieves high compression ratios with negligible computational cost. Our approach introduces lightweight sink-attention gating modules to identify and retain critical KV pairs, and integrates seamlessly into both the prefill and decoding stages. The proposed gate training algorithm relies on forward passes of an LLM, avoiding expensive backpropagation, while achieving strong task generalization through a task-agnostic reconstruction objective. Extensive experiments across the Qwen2.5-1M, Qwen3, and Gemma3 families show that our method maintains near-lossless performance while evicting up to 70% of the KV cache. The results are consistent across a wide range of tasks, including long-context understanding, code comprehension, and mathematical reasoning, demonstrating the generality of our approach.
Oops, Wait: Token-Level Signals as a Lens into LLM Reasoning
Jan 24, 2026The emergence of discourse-like tokens such as "wait" and "therefore" in large language models (LLMs) has offered a unique window into their reasoning processes. However, systematic analyses of how such signals vary across training strategies and model scales remain lacking. In this paper, we analyze token-level signals through token probabilities across various models. We find that specific tokens strongly correlate with reasoning correctness, varying with training strategies while remaining stable across model scales. A closer look at the "wait" token in relation to answer probability demonstrates that models fine-tuned on small-scale datasets acquire reasoning ability through such signals but exploit them only partially. This work provides a systematic lens to observe and understand the dynamics of LLM reasoning.
Privacy Collapse: Benign Fine-Tuning Can Break Contextual Privacy in Language Models
Jan 21, 2026We identify a novel phenomenon in language models: benign fine-tuning of frontier models can lead to privacy collapse. We find that diverse, subtle patterns in training data can degrade contextual privacy, including optimisation for helpfulness, exposure to user information, emotional and subjective dialogue, and debugging code printing internal variables, among others. Fine-tuned models lose their ability to reason about contextual privacy norms, share information inappropriately with tools, and violate memory boundaries across contexts. Privacy collapse is a ``silent failure'' because models maintain high performance on standard safety and utility benchmarks whilst exhibiting severe privacy vulnerabilities. Our experiments show evidence of privacy collapse across six models (closed and open weight), five fine-tuning datasets (real-world and controlled data), and two task categories (agentic and memory-based). Our mechanistic analysis reveals that privacy representations are uniquely fragile to fine-tuning, compared to task-relevant features which are preserved. Our results reveal a critical gap in current safety evaluations, in particular for the deployment of specialised agents.
What Defines Good Reasoning in LLMs? Dissecting Reasoning Steps with Multi-Aspect Evaluation
Oct 23, 2025
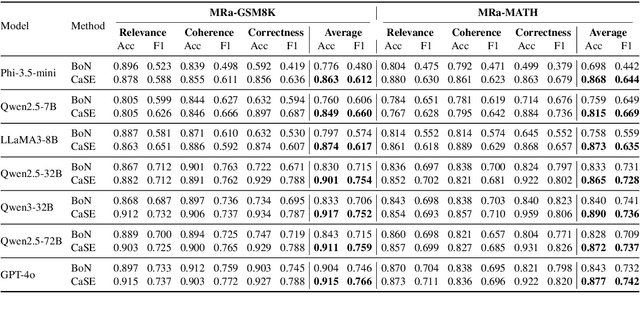
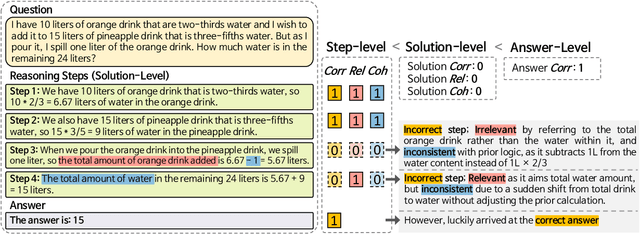
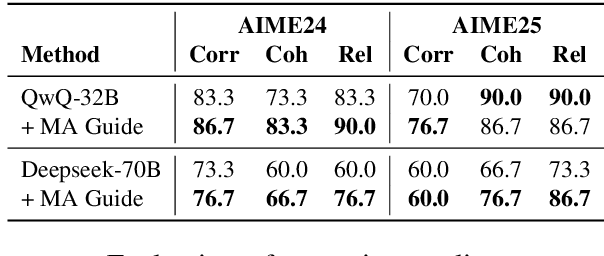
Evaluating large language models (LLMs) on final-answer correctness is the dominant paradigm. This approach, however, provides a coarse signal for model improvement and overlooks the quality of the underlying reasoning process. We argue that a more granular evaluation of reasoning offers a more effective path to building robust models. We decompose reasoning quality into two dimensions: relevance and coherence. Relevance measures if a step is grounded in the problem; coherence measures if it follows logically from prior steps. To measure these aspects reliably, we introduce causal stepwise evaluation (CaSE). This method assesses each reasoning step using only its preceding context, which avoids hindsight bias. We validate CaSE against human judgments on our new expert-annotated benchmarks, MRa-GSM8K and MRa-MATH. More importantly, we show that curating training data with CaSE-evaluated relevance and coherence directly improves final task performance. Our work provides a scalable framework for analyzing, debugging, and improving LLM reasoning, demonstrating the practical value of moving beyond validity checks.
Dr.LLM: Dynamic Layer Routing in LLMs
Oct 14, 2025Large Language Models (LLMs) process every token through all layers of a transformer stack, causing wasted computation on simple queries and insufficient flexibility for harder ones that need deeper reasoning. Adaptive-depth methods can improve efficiency, but prior approaches rely on costly inference-time search, architectural changes, or large-scale retraining, and in practice often degrade accuracy despite efficiency gains. We introduce Dr.LLM, Dynamic routing of Layers for LLMs, a retrofittable framework that equips pretrained models with lightweight per-layer routers deciding to skip, execute, or repeat a block. Routers are trained with explicit supervision: using Monte Carlo Tree Search (MCTS), we derive high-quality layer configurations that preserve or improve accuracy under a compute budget. Our design, windowed pooling for stable routing, focal loss with class balancing, and bottleneck MLP routers, ensures robustness under class imbalance and long sequences. On ARC (logic) and DART (math), Dr.LLM improves accuracy by up to +3.4%p while saving 5 layers per example on average. Routers generalize to out-of-domain tasks (MMLU, GSM8k, AIME, TruthfulQA, SQuADv2, GPQA, PIQA, AGIEval) with only 0.85% accuracy drop while retaining efficiency, and outperform prior routing methods by up to +7.7%p. Overall, Dr.LLM shows that explicitly supervised routers retrofit frozen LLMs for budget-aware, accuracy-driven inference without altering base weights.
ClearFairy: Capturing Creative Workflows through Decision Structuring, In-Situ Questioning, and Rationale Inference
Sep 18, 2025Capturing professionals' decision-making in creative workflows is essential for reflection, collaboration, and knowledge sharing, yet existing methods often leave rationales incomplete and implicit decisions hidden. To address this, we present CLEAR framework that structures reasoning into cognitive decision steps-linked units of actions, artifacts, and self-explanations that make decisions traceable. Building on this framework, we introduce ClearFairy, a think-aloud AI assistant for UI design that detects weak explanations, asks lightweight clarifying questions, and infers missing rationales to ease the knowledge-sharing burden. In a study with twelve creative professionals, 85% of ClearFairy's inferred rationales were accepted, increasing strong explanations from 14% to over 83% of decision steps without adding cognitive demand. The captured steps also enhanced generative AI agents in Figma, yielding next-action predictions better aligned with professionals and producing more coherent design outcomes. For future research on human knowledge-grounded creative AI agents, we release a dataset of captured 417 decision steps.