 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGE: All-[MASK] Block Already Knows Where to Look in Diffusion LLM
Feb 15, 2026Block diffusion LLMs are emerging as a promising next paradigm for language generation, but their use of KV caching makes memory access a dominant bottleneck in long-context settings. While dynamic sparse attention has been actively explored, existing methods designed for autoregressive LLMs rely on approximate importance estimation and perform poorly when adapted to block diffusion. This work identifies a key opportunity unique to block diffusion: attention at the first All-[MASK] denoising step reliably predicts important KV entries and budget requirements, enabling MAGE to perform a single exact attention pass per block and reuse it for training-free sparse denoising. Across long-context benchmarks including LongBench and Needle-in-a-Haystack, MAGE achieves near-lossless accuracy with a fraction of the KV budget while delivering up to 3-4x end-to-end speedup, consistently outperforming AR-oriented sparse attention baselines. A lightweight fine-tuning strategy further strengthens [MASK]-guided patterns with minimal cost, requiring only a few hours of training on a single NVIDIA H100 GPU for both 1.5B and 7B models.
GS-Scale: Unlocking Large-Scale 3D Gaussian Splatting Training via Host Offloading
Sep 19, 2025The advent of 3D Gaussian Splatting has revolutionized graphics rendering by delivering high visual quality and fast rendering speeds. However, training large-scale scenes at high quality remains challenging due to the substantial memory demands required to store parameters, gradients, and optimizer states, which can quickly overwhelm GPU memory. To address these limitations, we propose GS-Scale, a fast and memory-efficient training system for 3D Gaussian Splatting. GS-Scale stores all Gaussians in host memory, transferring only a subset to the GPU on demand for each forward and backward pass. While this dramatically reduces GPU memory usage, it requires frustum culling and optimizer updates to be executed on the CPU, introducing slowdowns due to CPU's limited compute and memory bandwidth. To mitigate this, GS-Scale employs three system-level optimizations: (1) selective offloading of geometric parameters for fast frustum culling, (2) parameter forwarding to pipeline CPU optimizer updates with GPU computation, and (3) deferred optimizer update to minimize unnecessary memory accesses for Gaussians with zero gradients. Our extensive evaluations on large-scale datasets demonstrate that GS-Scale significantly lowers GPU memory demands by 3.3-5.6x, while achieving training speeds comparable to GPU without host offloading. This enables large-scale 3D Gaussian Splatting training on consumer-grade GPUs; for instance, GS-Scale can scale the number of Gaussians from 4 million to 18 million on an RTX 4070 Mobile GPU, leading to 23-35% LPIPS (learned perceptual image patch similarity) improvement.
KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
May 29, 2025Transformer-based large language models (LLMs) cache context as key-value (KV) pairs during inference. As context length grows, KV cache sizes expand, leading to substantial memory overhead and increased attention latency. This paper introduces KVzip, a query-agnostic KV cache eviction method enabling effective reuse of compressed KV caches across diverse queries. KVzip quantifies the importance of a KV pair using the underlying LLM to reconstruct original contexts from cached KV pairs, subsequently evicting pairs with lower importance. Extensive empirical evaluations demonstrate that KVzip reduces KV cache size by 3-4$\times$ and FlashAttention decoding latency by approximately 2$\times$, with negligible performance loss in question-answering, retrieval, reasoning, and code comprehension tasks. Evaluations include various models such as LLaMA3.1-8B, Qwen2.5-14B, and Gemma3-12B, with context lengths reaching up to 170K tokens. KVzip significantly outperforms existing query-aware KV eviction methods, which suffer from performance degradation even at a 90% cache budget ratio under multi-query scenarios.
GuidedQuant: Large Language Model Quantization via Exploiting End Loss Guidance
May 11, 2025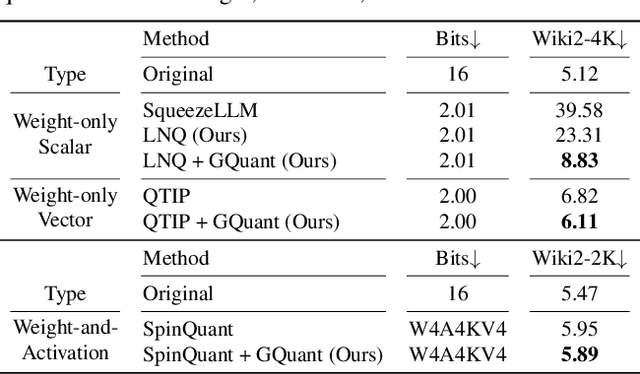
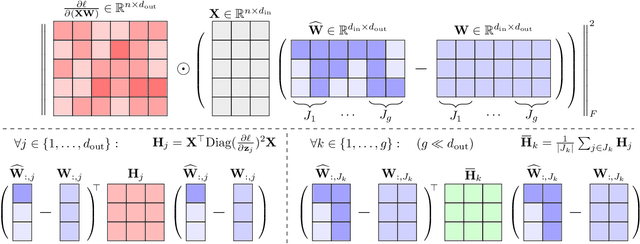
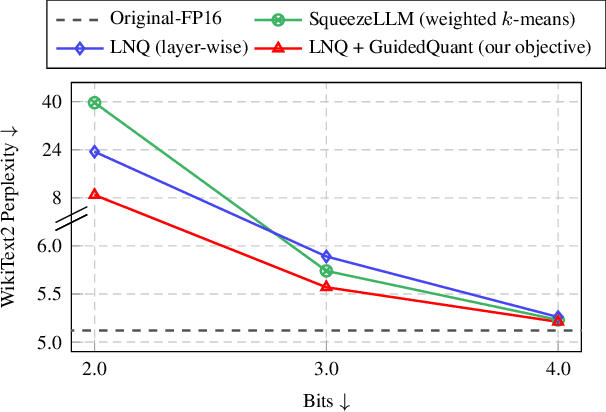
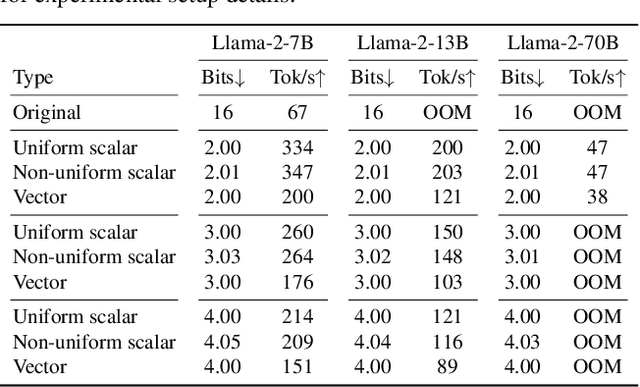
Post-training quantization is a key technique for reducing the memory and inference latency of large language models by quantizing weights and activations without requiring retraining. However, existing methods either (1) fail to account for the varying importance of hidden features to the end loss or, when incorporating end loss, (2) neglect the critical interactions between model weights. To address these limitations, we propose GuidedQuant, a novel quantization approach that integrates gradient information from the end loss into the quantization objective while preserving cross-weight dependencies within output channels. GuidedQuant consistently boosts the performance of state-of-the-art quantization methods across weight-only scalar, weight-only vector, and weight-and-activation quantization. Additionally, we introduce a novel non-uniform scalar quantization algorithm, which is guaranteed to monotonically decrease the quantization objective value, and outperforms existing methods in this category. We release the code at https://github.com/snu-mllab/GuidedQuant.
Pushing the Envelope of Low-Bit LLM via Dynamic Error Compensation
Dec 28, 2024
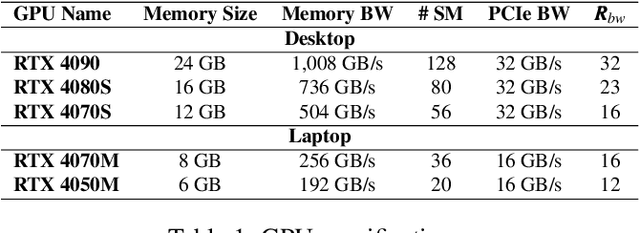

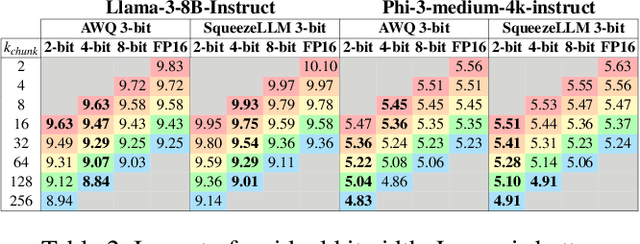
Quantization of Large Language Models (LLMs) has recently gained popularity, particularly for on-device settings with limited hardware resources. While efficient, quantization inevitably degrades model quality, especially in aggressive low-bit settings such as 3-bit and 4-bit precision. In this paper, we propose QDEC, an inference scheme that improves the quality of low-bit LLMs while preserving the key benefits of quantization: GPU memory savings and inference latency reduction. QDEC stores the residual matrix -- the difference between full-precision and quantized weights -- in CPU, and dynamically fetches the residuals for only a small portion of the weights. This portion corresponds to the salient channels, marked by activation outliers, with the fetched residuals helping to correct quantization errors in these channels. Salient channels are identified dynamically at each decoding step by analyzing the input activations -- this allows for the adaptation to the dynamic nature of activation distribution, and thus maximizes the effectiveness of error compensation. We demonstrate the effectiveness of QDEC by augmenting state-of-the-art quantization methods. For example, QDEC reduces the perplexity of a 3-bit Llama-3-8B-Instruct model from 10.15 to 9.12 -- outperforming its 3.5-bit counterpart -- while adding less than 0.0003\% to GPU memory usage and incurring only a 1.7\% inference slowdown on NVIDIA RTX 4050 Mobile GPU. The code will be publicly available soon.
Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
Feb 16, 2024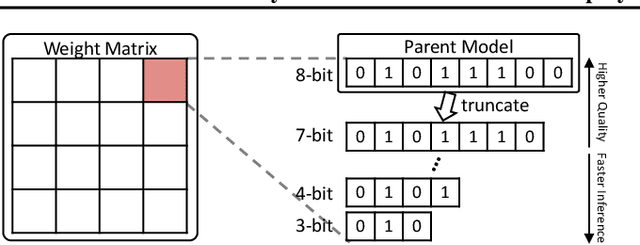
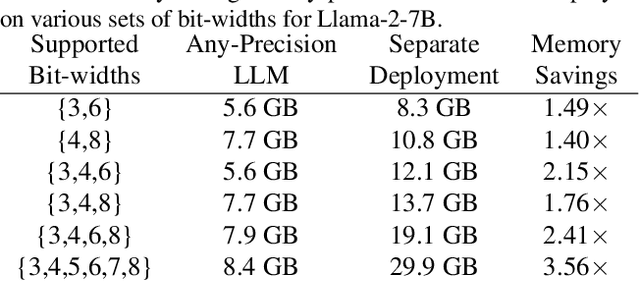
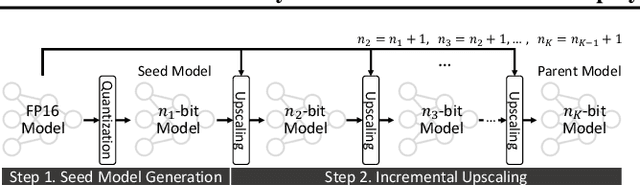
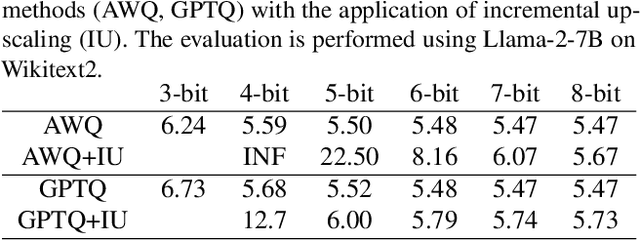
Recently, considerable efforts have been directed towards compressing Large Language Models (LLMs), which showcase groundbreaking capabilities across diverse applications but entail significant deployment costs due to their large sizes. Meanwhile, much less attention has been given to mitigating the costs associated with deploying multiple LLMs of varying sizes despite its practical significance. Thus, this paper introduces \emph{any-precision LLM}, extending the concept of any-precision DNN to LLMs. Addressing challenges in any-precision LLM, we propose a lightweight method for any-precision quantization of LLMs, leveraging a post-training quantization framework, and develop a specialized software engine for its efficient serving. As a result, our solution significantly reduces the high costs of deploying multiple, different-sized LLMs by overlaying LLMs quantized to varying bit-widths, such as 3, 4, ..., $n$ bits, into a memory footprint comparable to a single $n$-bit LLM. All the supported LLMs with varying bit-widths demonstrate state-of-the-art model quality and inference throughput, proving itself to be a compelling option for deployment of multiple, different-sized LLMs. The source code will be publicly available soon.
Ginex: SSD-enabled Billion-scale Graph Neural Network Training on a Single Machine via Provably Optimal In-memory Caching
Aug 19, 2022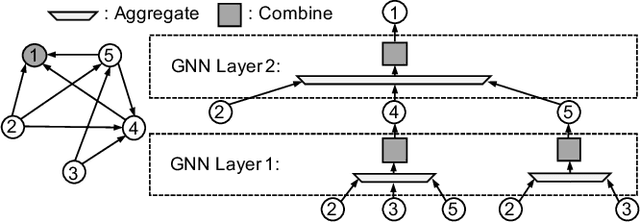

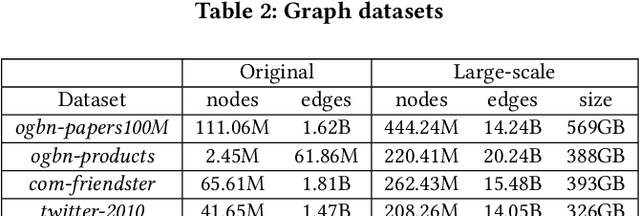
Recently, Graph Neural Networks (GNNs) have been receiving a spotlight as a powerful tool that can effectively serve various inference tasks on graph structured data. As the size of real-world graphs continues to scale, the GNN training system faces a scalability challenge. Distributed training is a popular approach to address this challenge by scaling out CPU nodes. However, not much attention has been paid to disk-based GNN training, which can scale up the single-node system in a more cost-effective manner by leveraging high-performance storage devices like NVMe SSDs. We observe that the data movement between the main memory and the disk is the primary bottleneck in the SSD-based training system, and that the conventional GNN training pipeline is sub-optimal without taking this overhead into account. Thus, we propose Ginex, the first SSD-based GNN training system that can process billion-scale graph datasets on a single machine. Inspired by the inspector-executor execution model in compiler optimization, Ginex restructures the GNN training pipeline by separating sample and gather stages. This separation enables Ginex to realize a provably optimal replacement algorithm, known as Belady's algorithm, for caching feature vectors in memory, which account for the dominant portion of I/O accesses. According to our evaluation with four billion-scale graph datasets, Ginex achieves 2.11x higher training throughput on average (up to 2.67x at maximum) than the SSD-extended PyTorch Geometric.
L3: Accelerator-Friendly Lossless Image Format for High-Resolution, High-Throughput DNN Training
Aug 18, 2022
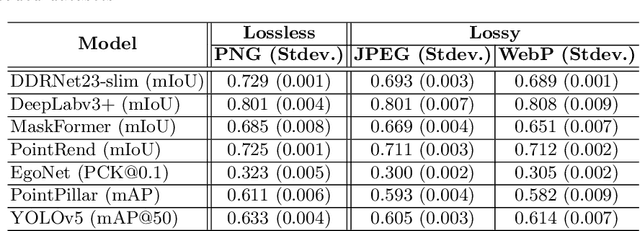
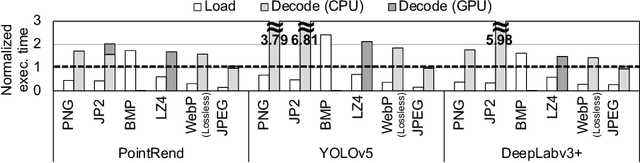
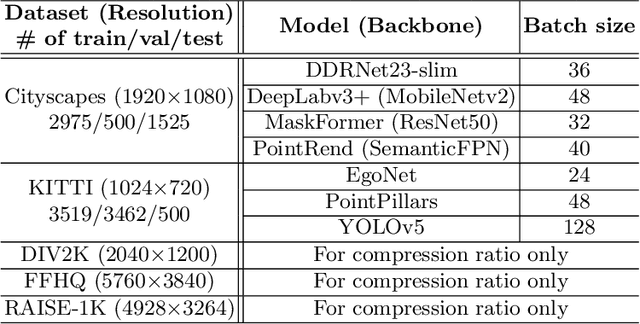
The training process of deep neural networks (DNNs) is usually pipelined with stages for data preparation on CPUs followed by gradient computation on accelerators like GPUs. In an ideal pipeline, the end-to-end training throughput is eventually limited by the throughput of the accelerator, not by that of data preparation. In the past, the DNN training pipeline achieved a near-optimal throughput by utilizing datasets encoded with a lightweight, lossy image format like JPEG. However, as high-resolution, losslessly-encoded datasets become more popular for applications requiring high accuracy, a performance problem arises in the data preparation stage due to low-throughput image decoding on the CPU. Thus, we propose L3, a custom lightweight, lossless image format for high-resolution, high-throughput DNN training. The decoding process of L3 is effectively parallelized on the accelerator, thus minimizing CPU intervention for data preparation during DNN training. L3 achieves a 9.29x higher data preparation throughput than PNG, the most popular lossless image format, for the Cityscapes dataset on NVIDIA A100 GPU, which leads to 1.71x higher end-to-end training throughput. Compared to JPEG and WebP, two popular lossy image formats, L3 provides up to 1.77x and 2.87x higher end-to-end training throughput for ImageNet, respectively, at equivalent metric performance.
A$^3$: Accelerating Attention Mechanisms in Neural Networks with Approximation
Feb 22, 2020
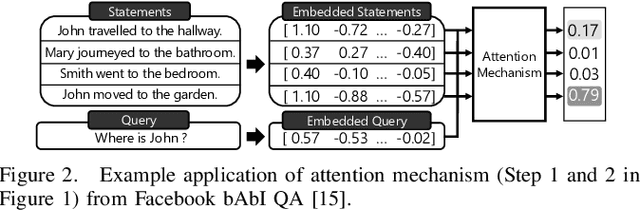
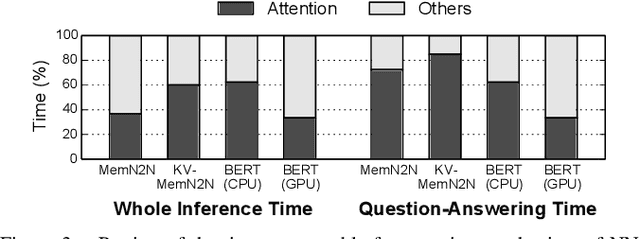

With the increasing computational demands of neural networks, many hardware accelerators for the neural networks have been proposed. Such existing neural network accelerators often focus on popular neural network types such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs); however, not much attention has been paid to attention mechanisms, an emerging neural network primitive that enables neural networks to retrieve most relevant information from a knowledge-base, external memory, or past states. The attention mechanism is widely adopted by many state-of-the-art neural networks for computer vision, natural language processing, and machine translation, and accounts for a large portion of total execution time. We observe today's practice of implementing this mechanism using matrix-vector multiplication is suboptimal as the attention mechanism is semantically a content-based search where a large portion of computations ends up not being used. Based on this observation, we design and architect A3, which accelerates attention mechanisms in neural networks with algorithmic approximation and hardware specialization. Our proposed accelerator achieves multiple orders of magnitude improvement in energy efficiency (performance/watt) as well as substantial speedup over the state-of-the-art conventional hardware.