 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Graph Foundation Models for Atomistic Materials Modeling: A Case Study with HydraGNN
Jun 12, 2024We present our work on developing and training scalable graph foundation models (GFM) using HydraGNN, a multi-headed graph convolutional neural network architecture. HydraGNN expands the boundaries of graph neural network (GNN) in both training scale and data diversity. It abstracts over message passing algorithms, allowing both reproduction of and comparison across algorithmic innovations that define convolution in GNNs. This work discusses a series of optimizations that have allowed scaling up the GFM training to tens of thousands of GPUs on datasets that consist of hundreds of millions of graphs. Our GFMs use multi-task learning (MTL) to simultaneously learn graph-level and node-level properties of atomistic structures, such as the total energy and atomic forces. Using over 150 million atomistic structures for training, we illustrate the performance of our approach along with the lessons learned on two United States Department of Energy (US-DOE) supercomputers, namely the Perlmutter petascale system at the National Energy Research Scientific Computing Center and the Frontier exascale system at Oak Ridge National Laboratory. The HydraGNN architecture enables the GFM to achieve near-linear strong scaling performance using more than 2,000 GPUs on Perlmutter and 16,000 GPUs on Frontier. Hyperparameter optimization (HPO) was performed on over 64,000 GPUs on Frontier to select GFM architectures with high accuracy. Early stopping was applied on each GFM architecture for energy awareness in performing such an extreme-scale task. The training of an ensemble of highest-ranked GFM architectures continued until convergence to establish uncertainty quantification (UQ) capabilities with ensemble learning. Our contribution opens the door for rapidly developing, training, and deploying GFMs using large-scale computational resources to enable AI-accelerated materials discovery and design.
L3: Accelerator-Friendly Lossless Image Format for High-Resolution, High-Throughput DNN Training
Aug 18, 2022
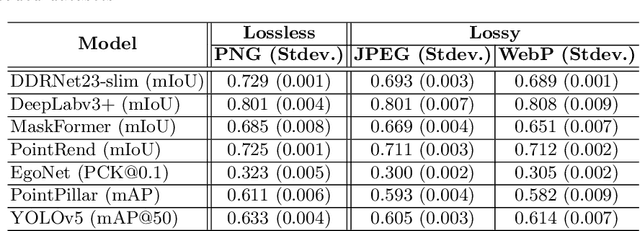
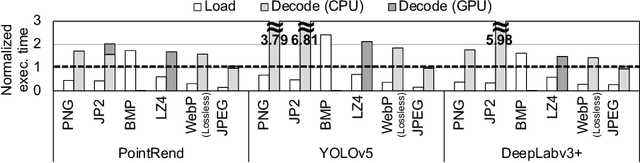
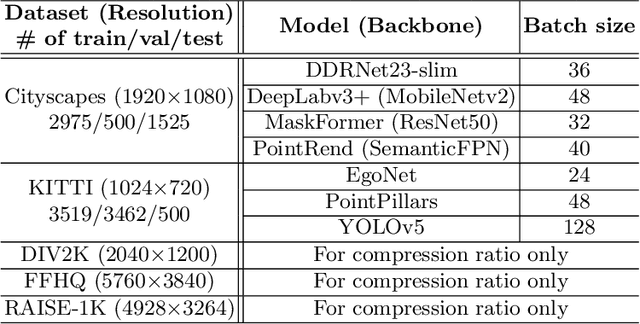
The training process of deep neural networks (DNNs) is usually pipelined with stages for data preparation on CPUs followed by gradient computation on accelerators like GPUs. In an ideal pipeline, the end-to-end training throughput is eventually limited by the throughput of the accelerator, not by that of data preparation. In the past, the DNN training pipeline achieved a near-optimal throughput by utilizing datasets encoded with a lightweight, lossy image format like JPEG. However, as high-resolution, losslessly-encoded datasets become more popular for applications requiring high accuracy, a performance problem arises in the data preparation stage due to low-throughput image decoding on the CPU. Thus, we propose L3, a custom lightweight, lossless image format for high-resolution, high-throughput DNN training. The decoding process of L3 is effectively parallelized on the accelerator, thus minimizing CPU intervention for data preparation during DNN training. L3 achieves a 9.29x higher data preparation throughput than PNG, the most popular lossless image format, for the Cityscapes dataset on NVIDIA A100 GPU, which leads to 1.71x higher end-to-end training throughput. Compared to JPEG and WebP, two popular lossy image formats, L3 provides up to 1.77x and 2.87x higher end-to-end training throughput for ImageNet, respectively, at equivalent metric performance.
PyNET-QxQ: A Distilled PyNET for QxQ Bayer Pattern Demosaicing in CMOS Image Sensor
Mar 08, 2022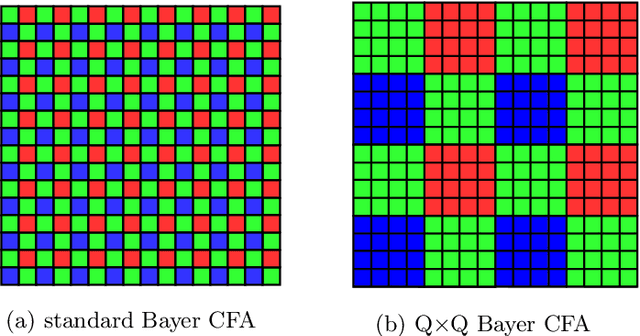
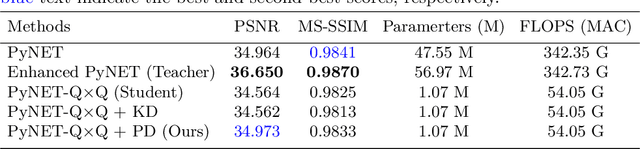
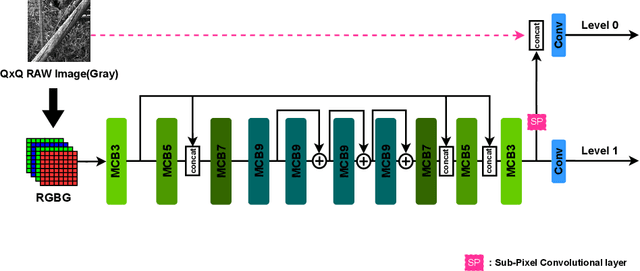
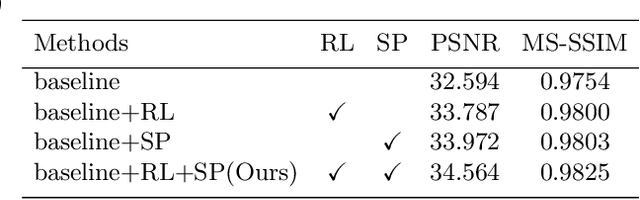
The deep learning-based ISP models for mobile cameras produce high-quality images comparable to the professional DSLR camera. However, many of them are computationally expensive, which may not be appropriate for mobile environments. Also, the recent mobile cameras adopt non-Bayer CFAs (e.g., Quad Bayer, Nona Bayer, and QxQ Bayer) to improve image quality; however, most deep learning-based ISP models mainly focus on standard Bayer CFA. In this work, we propose PyNET-QxQ based on PyNET, a light-weighted ISP explicitly designed for the QxQ CFA pattern. The number of parameters of PyNET-QxQ is less than 2.5% of PyNET. We also introduce a novel knowledge distillation technique, progressive distillation, to train the compressed network effectively. Finally, experiments with QxQ images (obtained by an actual QxQ camera sensor, under development) demonstrate the outstanding performance of PyNET-QxQ despite significant parameter reductions.