 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Graph Foundation Models for Atomistic Materials Modeling: A Case Study with HydraGNN
Jun 12, 2024We present our work on developing and training scalable graph foundation models (GFM) using HydraGNN, a multi-headed graph convolutional neural network architecture. HydraGNN expands the boundaries of graph neural network (GNN) in both training scale and data diversity. It abstracts over message passing algorithms, allowing both reproduction of and comparison across algorithmic innovations that define convolution in GNNs. This work discusses a series of optimizations that have allowed scaling up the GFM training to tens of thousands of GPUs on datasets that consist of hundreds of millions of graphs. Our GFMs use multi-task learning (MTL) to simultaneously learn graph-level and node-level properties of atomistic structures, such as the total energy and atomic forces. Using over 150 million atomistic structures for training, we illustrate the performance of our approach along with the lessons learned on two United States Department of Energy (US-DOE) supercomputers, namely the Perlmutter petascale system at the National Energy Research Scientific Computing Center and the Frontier exascale system at Oak Ridge National Laboratory. The HydraGNN architecture enables the GFM to achieve near-linear strong scaling performance using more than 2,000 GPUs on Perlmutter and 16,000 GPUs on Frontier. Hyperparameter optimization (HPO) was performed on over 64,000 GPUs on Frontier to select GFM architectures with high accuracy. Early stopping was applied on each GFM architecture for energy awareness in performing such an extreme-scale task. The training of an ensemble of highest-ranked GFM architectures continued until convergence to establish uncertainty quantification (UQ) capabilities with ensemble learning. Our contribution opens the door for rapidly developing, training, and deploying GFMs using large-scale computational resources to enable AI-accelerated materials discovery and design.
Scalable training of graph convolutional neural networks for fast and accurate predictions of HOMO-LUMO gap in molecules
Jul 22, 2022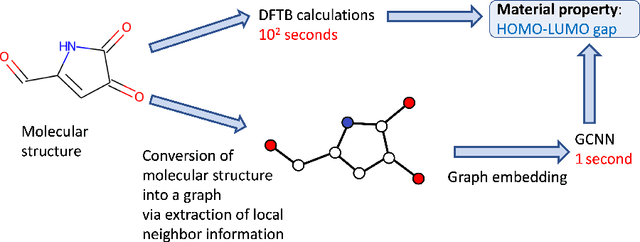


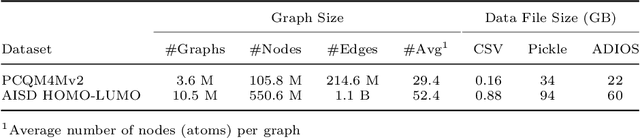
Graph Convolutional Neural Network (GCNN) is a popular class of deep learning (DL) models in material science to predict material properties from the graph representation of molecular structures. Training an accurate and comprehensive GCNN surrogate for molecular design requires large-scale graph datasets and is usually a time-consuming process. Recent advances in GPUs and distributed computing open a path to reduce the computational cost for GCNN training effectively. However, efficient utilization of high performance computing (HPC) resources for training requires simultaneously optimizing large-scale data management and scalable stochastic batched optimization techniques. In this work, we focus on building GCNN models on HPC systems to predict material properties of millions of molecules. We use HydraGNN, our in-house library for large-scale GCNN training, leveraging distributed data parallelism in PyTorch. We use ADIOS, a high-performance data management framework for efficient storage and reading of large molecular graph data. We perform parallel training on two open-source large-scale graph datasets to build a GCNN predictor for an important quantum property known as the HOMO-LUMO gap. We measure the scalability, accuracy, and convergence of our approach on two DOE supercomputers: the Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF) and the Perlmutter system at the National Energy Research Scientific Computing Center (NERSC). We present our experimental results with HydraGNN showing i) reduction of data loading time up to 4.2 times compared with a conventional method and ii) linear scaling performance for training up to 1,024 GPUs on both Summit and Perlmutter.