 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Graph Foundation Models for Atomistic Materials Modeling: A Case Study with HydraGNN
Jun 12, 2024We present our work on developing and training scalable graph foundation models (GFM) using HydraGNN, a multi-headed graph convolutional neural network architecture. HydraGNN expands the boundaries of graph neural network (GNN) in both training scale and data diversity. It abstracts over message passing algorithms, allowing both reproduction of and comparison across algorithmic innovations that define convolution in GNNs. This work discusses a series of optimizations that have allowed scaling up the GFM training to tens of thousands of GPUs on datasets that consist of hundreds of millions of graphs. Our GFMs use multi-task learning (MTL) to simultaneously learn graph-level and node-level properties of atomistic structures, such as the total energy and atomic forces. Using over 150 million atomistic structures for training, we illustrate the performance of our approach along with the lessons learned on two United States Department of Energy (US-DOE) supercomputers, namely the Perlmutter petascale system at the National Energy Research Scientific Computing Center and the Frontier exascale system at Oak Ridge National Laboratory. The HydraGNN architecture enables the GFM to achieve near-linear strong scaling performance using more than 2,000 GPUs on Perlmutter and 16,000 GPUs on Frontier. Hyperparameter optimization (HPO) was performed on over 64,000 GPUs on Frontier to select GFM architectures with high accuracy. Early stopping was applied on each GFM architecture for energy awareness in performing such an extreme-scale task. The training of an ensemble of highest-ranked GFM architectures continued until convergence to establish uncertainty quantification (UQ) capabilities with ensemble learning. Our contribution opens the door for rapidly developing, training, and deploying GFMs using large-scale computational resources to enable AI-accelerated materials discovery and design.
Cost-Effective Methodology for Complex Tuning Searches in HPC: Navigating Interdependencies and Dimensionality
Mar 12, 2024

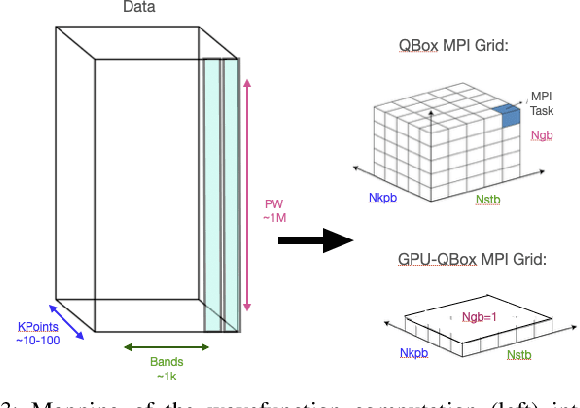

Tuning searches are pivotal in High-Performance Computing (HPC), addressing complex optimization challenges in computational applications. The complexity arises not only from finely tuning parameters within routines but also potential interdependencies among them, rendering traditional optimization methods inefficient. Instead of scrutinizing interdependencies among parameters and routines, practitioners often face the dilemma of conducting independent tuning searches for each routine, thereby overlooking interdependence, or pursuing a more resource-intensive joint search for all routines. This decision is driven by the consideration that some interdependence analysis and high-dimensional decomposition techniques in literature may be prohibitively expensive in HPC tuning searches. Our methodology adapts and refines these methods to ensure computational feasibility while maximizing performance gains in real-world scenarios. Our methodology leverages a cost-effective interdependence analysis to decide whether to merge several tuning searches into a joint search or conduct orthogonal searches. Tested on synthetic functions with varying levels of parameter interdependence, our methodology efficiently explores the search space. In comparison to Bayesian-optimization-based full independent or fully joint searches, our methodology suggested an optimized breakdown of independent and merged searches that led to final configurations up to 8% more accurate, reducing the search time by up to 95%. When applied to GPU-offloaded Real-Time Time-Dependent Density Functional Theory (RT-TDDFT), an application in computational materials science that challenges modern HPC autotuners, our methodology achieved an effective tuning search. Its adaptability and efficiency extend beyond RT-TDDFT, making it valuable for related applications in HPC.