 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Artificial Scientist -- in-transit Machine Learning of Plasma Simulations
Jan 06, 2025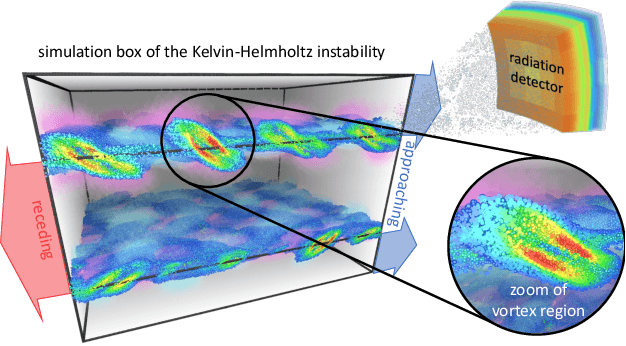
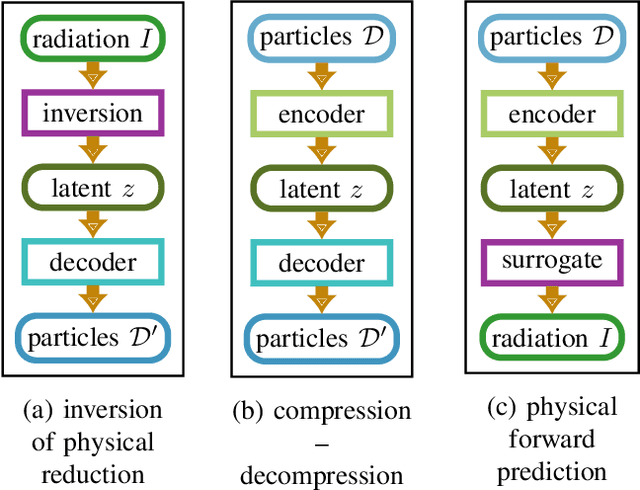
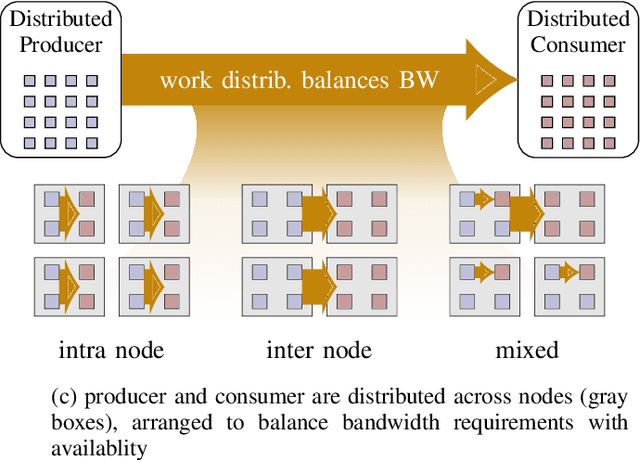
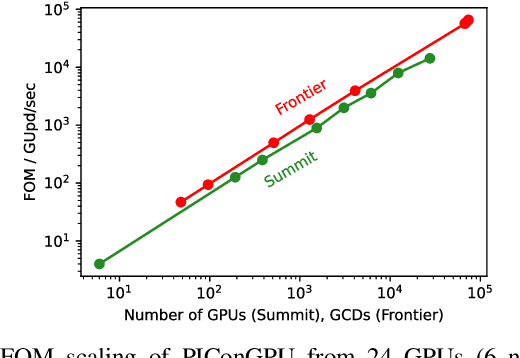
Increasing HPC cluster sizes and large-scale simulations that produce petabytes of data per run, create massive IO and storage challenges for analysis. Deep learning-based techniques, in particular, make use of these amounts of domain data to extract patterns that help build scientific understanding. Here, we demonstrate a streaming workflow in which simulation data is streamed directly to a machine-learning (ML) framework, circumventing the file system bottleneck. Data is transformed in transit, asynchronously to the simulation and the training of the model. With the presented workflow, data operations can be performed in common and easy-to-use programming languages, freeing the application user from adapting the application output routines. As a proof-of-concept we consider a GPU accelerated particle-in-cell (PIConGPU) simulation of the Kelvin- Helmholtz instability (KHI). We employ experience replay to avoid catastrophic forgetting in learning from this non-steady process in a continual manner. We detail challenges addressed while porting and scaling to Frontier exascale system.
Scalable Training of Graph Foundation Models for Atomistic Materials Modeling: A Case Study with HydraGNN
Jun 12, 2024We present our work on developing and training scalable graph foundation models (GFM) using HydraGNN, a multi-headed graph convolutional neural network architecture. HydraGNN expands the boundaries of graph neural network (GNN) in both training scale and data diversity. It abstracts over message passing algorithms, allowing both reproduction of and comparison across algorithmic innovations that define convolution in GNNs. This work discusses a series of optimizations that have allowed scaling up the GFM training to tens of thousands of GPUs on datasets that consist of hundreds of millions of graphs. Our GFMs use multi-task learning (MTL) to simultaneously learn graph-level and node-level properties of atomistic structures, such as the total energy and atomic forces. Using over 150 million atomistic structures for training, we illustrate the performance of our approach along with the lessons learned on two United States Department of Energy (US-DOE) supercomputers, namely the Perlmutter petascale system at the National Energy Research Scientific Computing Center and the Frontier exascale system at Oak Ridge National Laboratory. The HydraGNN architecture enables the GFM to achieve near-linear strong scaling performance using more than 2,000 GPUs on Perlmutter and 16,000 GPUs on Frontier. Hyperparameter optimization (HPO) was performed on over 64,000 GPUs on Frontier to select GFM architectures with high accuracy. Early stopping was applied on each GFM architecture for energy awareness in performing such an extreme-scale task. The training of an ensemble of highest-ranked GFM architectures continued until convergence to establish uncertainty quantification (UQ) capabilities with ensemble learning. Our contribution opens the door for rapidly developing, training, and deploying GFMs using large-scale computational resources to enable AI-accelerated materials discovery and design.
Deriving Disinformation Insights from Geolocalized Twitter Callouts
Aug 06, 2021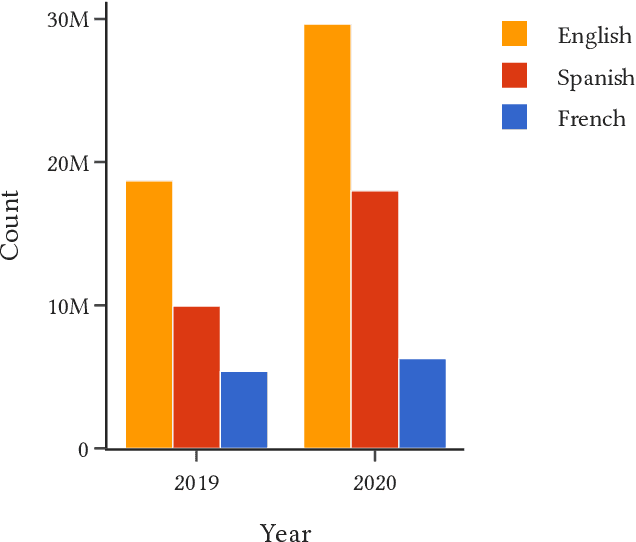

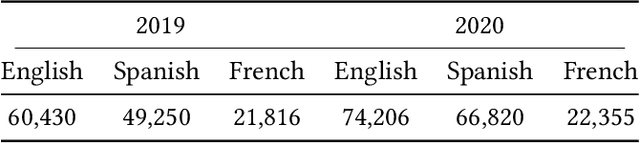
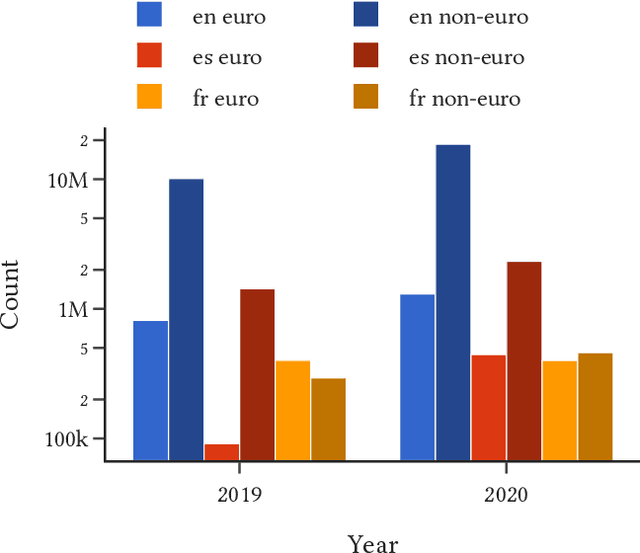
This paper demonstrates a two-stage method for deriving insights from social media data relating to disinformation by applying a combination of geospatial classification and embedding-based language modelling across multiple languages. In particular, the analysis in centered on Twitter and disinformation for three European languages: English, French and Spanish. Firstly, Twitter data is classified into European and non-European sets using BERT. Secondly, Word2vec is applied to the classified texts resulting in Eurocentric, non-Eurocentric and global representations of the data for the three target languages. This comparative analysis demonstrates not only the efficacy of the classification method but also highlights geographic, temporal and linguistic differences in the disinformation-related media. Thus, the contributions of the work are threefold: (i) a novel language-independent transformer-based geolocation method; (ii) an analytical approach that exploits lexical specificity and word embeddings to interrogate user-generated content; and (iii) a dataset of 36 million disinformation related tweets in English, French and Spanish.
Predicting Themes within Complex Unstructured Texts: A Case Study on Safeguarding Reports
Oct 29, 2020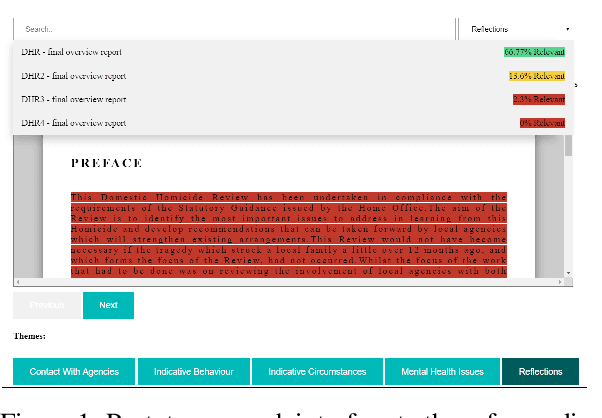
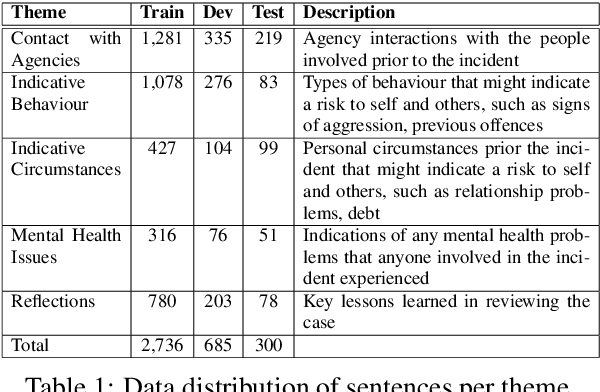
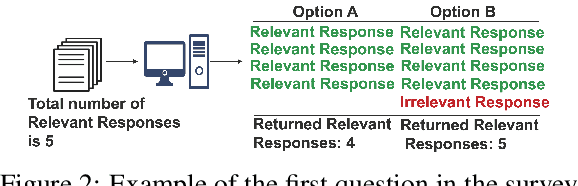
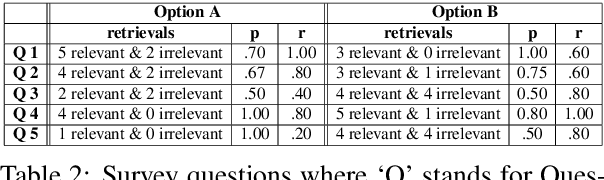
The task of text and sentence classification is associated with the need for large amounts of labelled training data. The acquisition of high volumes of labelled datasets can be expensive or unfeasible, especially for highly-specialised domains for which documents are hard to obtain. Research on the application of supervised classification based on small amounts of training data is limited. In this paper, we address the combination of state-of-the-art deep learning and classification methods and provide an insight into what combination of methods fit the needs of small, domain-specific, and terminologically-rich corpora. We focus on a real-world scenario related to a collection of safeguarding reports comprising learning experiences and reflections on tackling serious incidents involving children and vulnerable adults. The relatively small volume of available reports and their use of highly domain-specific terminology makes the application of automated approaches difficult. We focus on the problem of automatically identifying the main themes in a safeguarding report using supervised classification approaches. Our results show the potential of deep learning models to simulate subject-expert behaviour even for complex tasks with limited labelled data.