 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3: Accelerator-Friendly Lossless Image Format for High-Resolution, High-Throughput DNN Training
Aug 18, 2022
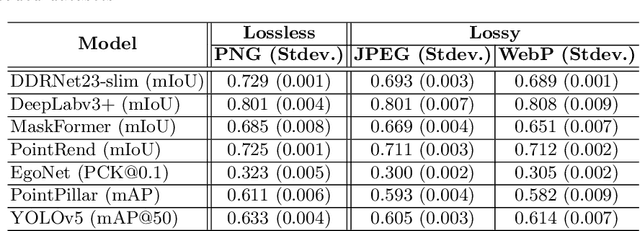
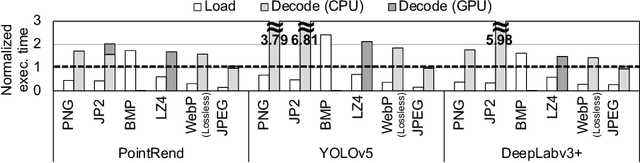
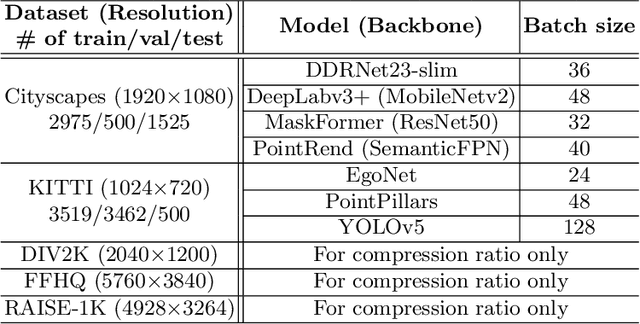
The training process of deep neural networks (DNNs) is usually pipelined with stages for data preparation on CPUs followed by gradient computation on accelerators like GPUs. In an ideal pipeline, the end-to-end training throughput is eventually limited by the throughput of the accelerator, not by that of data preparation. In the past, the DNN training pipeline achieved a near-optimal throughput by utilizing datasets encoded with a lightweight, lossy image format like JPEG. However, as high-resolution, losslessly-encoded datasets become more popular for applications requiring high accuracy, a performance problem arises in the data preparation stage due to low-throughput image decoding on the CPU. Thus, we propose L3, a custom lightweight, lossless image format for high-resolution, high-throughput DNN training. The decoding process of L3 is effectively parallelized on the accelerator, thus minimizing CPU intervention for data preparation during DNN training. L3 achieves a 9.29x higher data preparation throughput than PNG, the most popular lossless image format, for the Cityscapes dataset on NVIDIA A100 GPU, which leads to 1.71x higher end-to-end training throughput. Compared to JPEG and WebP, two popular lossy image formats, L3 provides up to 1.77x and 2.87x higher end-to-end training throughput for ImageNet, respectively, at equivalent metric performance.
A$^3$: Accelerating Attention Mechanisms in Neural Networks with Approximation
Feb 22, 2020
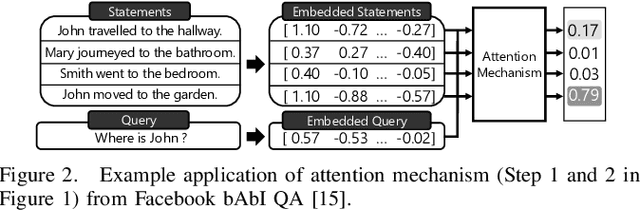
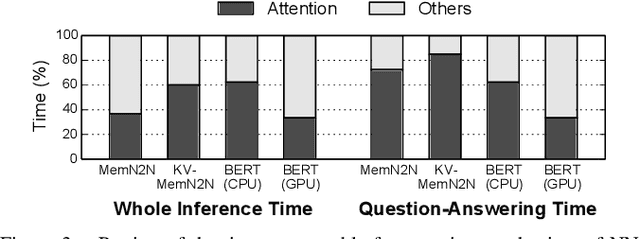

With the increasing computational demands of neural networks, many hardware accelerators for the neural networks have been proposed. Such existing neural network accelerators often focus on popular neural network types such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs); however, not much attention has been paid to attention mechanisms, an emerging neural network primitive that enables neural networks to retrieve most relevant information from a knowledge-base, external memory, or past states. The attention mechanism is widely adopted by many state-of-the-art neural networks for computer vision, natural language processing, and machine translation, and accounts for a large portion of total execution time. We observe today's practice of implementing this mechanism using matrix-vector multiplication is suboptimal as the attention mechanism is semantically a content-based search where a large portion of computations ends up not being used. Based on this observation, we design and architect A3, which accelerates attention mechanisms in neural networks with algorithmic approximation and hardware specialization. Our proposed accelerator achieves multiple orders of magnitude improvement in energy efficiency (performance/watt) as well as substantial speedup over the state-of-the-art conventional hardware.