 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitE : Accelerating Learned Query Optimization in a Mixed-Workload Environment
Jun 02, 2023Although the many efforts to apply deep reinforcement learning to query optimization in recent years, there remains room for improvement as query optimizers are complex entities that require hand-designed tuning of workloads and datasets. Recent research present learned query optimizations results mostly in bulks of single workloads which focus on picking up the unique traits of the specific workload. This proves to be problematic in scenarios where the different characteristics of multiple workloads and datasets are to be mixed and learned together. Henceforth, in this paper, we propose BitE, a novel ensemble learning model using database statistics and metadata to tune a learned query optimizer for enhancing performance. On the way, we introduce multiple revisions to solve several challenges: we extend the search space for the optimal Abstract SQL Plan(represented as a JSON object called ASP) by expanding hintsets, we steer the model away from the default plans that may be biased by configuring the experience with all unique plans of queries, and we deviate from the traditional loss functions and choose an alternative method to cope with underestimation and overestimation of reward. Our model achieves 19.6% more improved queries and 15.8% less regressed queries compared to the existing traditional methods whilst using a comparable level of resources.
Two-Stage Mesh Deep Learning for Automated Tooth Segmentation and Landmark Localization on 3D Intraoral Scans
Sep 24, 2021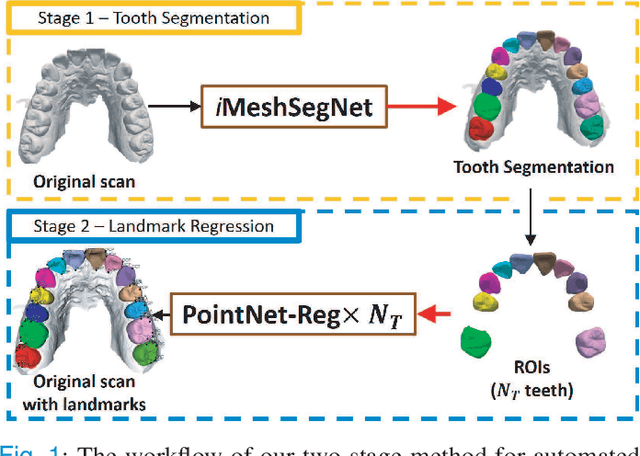
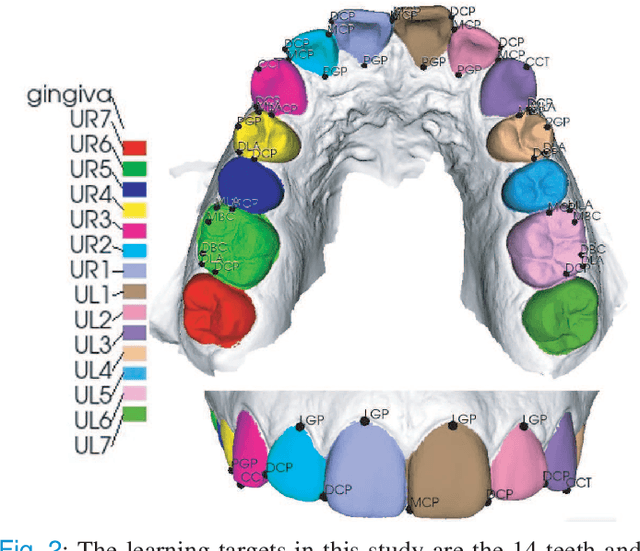
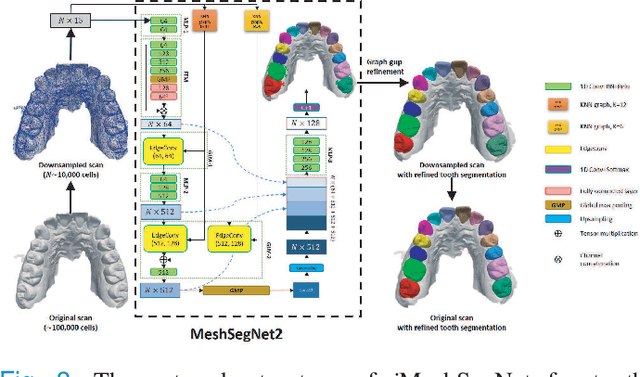
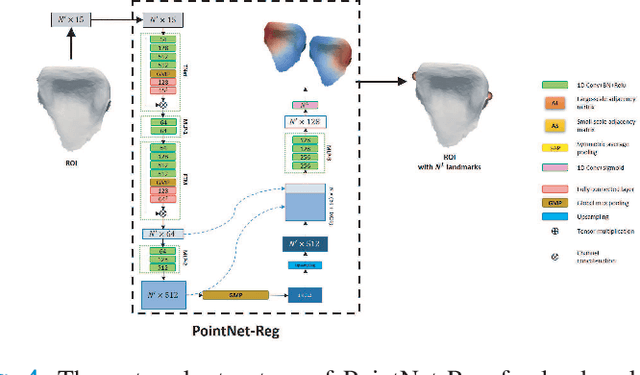
Accurately segmenting teeth and identifying the corresponding anatomical landmarks on dental mesh models are essential in computer-aided orthodontic treatment. Manually performing these two tasks is time-consuming, tedious, and, more importantly, highly dependent on orthodontists' experiences due to the abnormality and large-scale variance of patients' teeth. Some machine learning-based methods have been designed and applied in the orthodontic field to automatically segment dental meshes (e.g., intraoral scans). In contrast, the number of studies on tooth landmark localization is still limited. This paper proposes a two-stage framework based on mesh deep learning (called TS-MDL) for joint tooth labeling and landmark identification on raw intraoral scans. Our TS-MDL first adopts an end-to-end \emph{i}MeshSegNet method (i.e., a variant of the existing MeshSegNet with both improved accuracy and efficiency) to label each tooth on the downsampled scan. Guided by the segmentation outputs, our TS-MDL further selects each tooth's region of interest (ROI) on the original mesh to construct a light-weight variant of the pioneering PointNet (i.e., PointNet-Reg) for regressing the corresponding landmark heatmaps. Our TS-MDL was evaluated on a real-clinical dataset, showing promising segmentation and localization performance. Specifically, \emph{i}MeshSegNet in the first stage of TS-MDL reached an averaged Dice similarity coefficient (DSC) at $0.953\pm0.076$, significantly outperforming the original MeshSegNet. In the second stage, PointNet-Reg achieved a mean absolute error (MAE) of $0.623\pm0.718 \, mm$ in distances between the prediction and ground truth for $44$ landmarks, which is superior compared with other networks for landmark detection. All these results suggest the potential usage of our TS-MDL in clinical practices.
A$^3$: Accelerating Attention Mechanisms in Neural Networks with Approximation
Feb 22, 2020
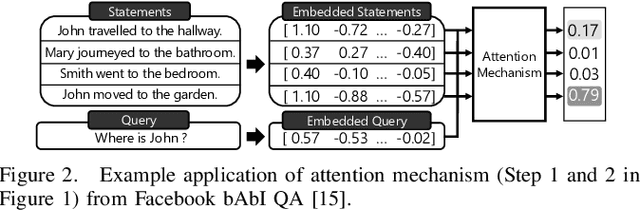
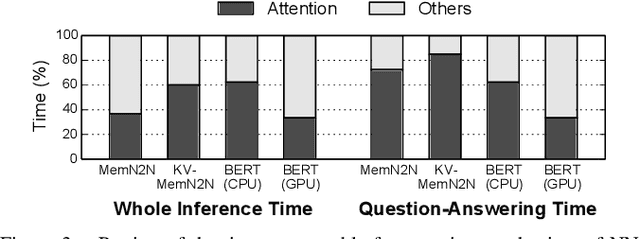

With the increasing computational demands of neural networks, many hardware accelerators for the neural networks have been proposed. Such existing neural network accelerators often focus on popular neural network types such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs); however, not much attention has been paid to attention mechanisms, an emerging neural network primitive that enables neural networks to retrieve most relevant information from a knowledge-base, external memory, or past states. The attention mechanism is widely adopted by many state-of-the-art neural networks for computer vision, natural language processing, and machine translation, and accounts for a large portion of total execution time. We observe today's practice of implementing this mechanism using matrix-vector multiplication is suboptimal as the attention mechanism is semantically a content-based search where a large portion of computations ends up not being used. Based on this observation, we design and architect A3, which accelerates attention mechanisms in neural networks with algorithmic approximation and hardware specialization. Our proposed accelerator achieves multiple orders of magnitude improvement in energy efficiency (performance/watt) as well as substantial speedup over the state-of-the-art conventional hardware.