 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndPrompt: Efficient Long-Context Extension via Terminal Anchoring
May 14, 2026Extending the context window of large language models typically requires training on sequences at the target length, incurring quadratic memory and computational costs that make long-context adaptation expensive and difficult to reproduce. We propose EndPrompt, a method that achieves effective context extension using only short training sequences. The core insight is that exposing a model to long-range relative positional distances does not require constructing full-length inputs: we preserve the original short context as an intact first segment and append a brief terminal prompt as a second segment, assigning it positional indices near the target context length. This two-segment construction introduces both local and long-range relative distances within a short physical sequence while maintaining the semantic continuity of the training text--a property absent in chunk-based simulation approaches that split contiguous context. We provide a theoretical analysis grounded in Rotary Position Embedding and the Bernstein inequality, showing that position interpolation induces a rigorous smoothness constraint over the attention function, with shared Transformer parameters further suppressing unstable extrapolation to unobserved intermediate distances. Applied to LLaMA-family models extending the context window from 8K to 64K, EndPrompt achieves an average RULER score of 76.03 and the highest average on LongBench, surpassing LCEG (72.24), LongLoRA (72.95), and full-length fine-tuning (69.23) while requiring substantially less computation. These results demonstrate that long-context generalization can be induced from sparse positional supervision, challenging the prevailing assumption that dense long-sequence training is necessary for reliable context-window extension. The code is available at https://github.com/clx1415926/EndPrompt.
AGCD: Agent-Guided Cross-Modal Decoding for Weather Forecasting
Mar 16, 2026Accurate weather forecasting is more than grid-wise regression: it must preserve coherent synoptic structures and physical consistency of meteorological fields, especially under autoregressive rollouts where small one-step errors can amplify into structural bias. Existing physics-priors approaches typically impose global, once-for-all constraints via architectures, regularization, or NWP coupling, offering limited state-adaptive and sample-specific controllability at deployment. To bridge this gap, we propose Agent-Guided Cross-modal Decoding (AGCD), a plug-and-play decoding-time prior-injection paradigm that derives state-conditioned physics-priors from the current multivariate atmosphere and injects them into forecasters in a controllable and reusable way. Specifically, We design a multi-agent meteorological narration pipeline to generate state-conditioned physics-priors, utilizing MLLMs to extract various meteorological elements effectively. To effectively apply the priors, AGCD further introduce cross-modal region interaction decoding that performs region-aware multi-scale tokenization and efficient physics-priors injection to refine visual features without changing the backbone interface. Experiments on WeatherBench demonstrate consistent gains for 6-hour forecasting across two resolutions (5.625 degree and 1.40625 degree) and diverse backbones (generic and weather-specialized), including strictly causal 48-hour autoregressive rollouts that reduce early-stage error accumulation and improve long-horizon stability.
Boosting Instance Awareness via Cross-View Correlation with 4D Radar and Camera for 3D Object Detection
Feb 24, 20264D millimeter-wave radar has emerged as a promising sensing modality for autonomous driving due to its robustness and affordability. However, its sparse and weak geometric cues make reliable instance activation difficult, limiting the effectiveness of existing radar-camera fusion paradigms. BEV-level fusion offers global scene understanding but suffers from weak instance focus, while perspective-level fusion captures instance details but lacks holistic context. To address these limitations, we propose SIFormer, a scene-instance aware transformer for 3D object detection using 4D radar and camera. SIFormer first suppresses background noise during view transformation through segmentation- and depth-guided localization. It then introduces a cross-view activation mechanism that injects 2D instance cues into BEV space, enabling reliable instance awareness under weak radar geometry. Finally, a transformer-based fusion module aggregates complementary image semantics and radar geometry for robust perception. As a result, with the aim of enhancing instance awareness, SIFormer bridges the gap between the two paradigms, combining their complementary strengths to address inherent sparse nature of radar and improve detection accuracy. Experiments demonstrate that SIFormer achieves state-of-the-art performance on View-of-Delft, TJ4DRadSet and NuScenes datasets. Source code is available at github.com/shawnnnkb/SIFormer.
Logic-Guided Multistage Inference for Explainable Multidefendant Judgment Prediction
Jan 19, 2026Crime disrupts societal stability, making law essential for balance. In multidefendant cases, assigning responsibility is complex and challenges fairness, requiring precise role differentiation. However, judicial phrasing often obscures the roles of the defendants, hindering effective AI-driven analyses. To address this issue, we incorporate sentencing logic into a pretrained Transformer encoder framework to enhance the intelligent assistance in multidefendant cases while ensuring legal interpretability. Within this framework an oriented masking mechanism clarifies roles and a comparative data construction strategy improves the model's sensitivity to culpability distinctions between principals and accomplices. Predicted guilt labels are further incorporated into a regression model through broadcasting, consolidating crime descriptions and court views. Our proposed masked multistage inference (MMSI) framework, evaluated on the custom IMLJP dataset for intentional injury cases, achieves significant accuracy improvements, outperforming baselines in role-based culpability differentiation. This work offers a robust solution for enhancing intelligent judicial systems, with publicly code available.
E-ConvNeXt: A Lightweight and Efficient ConvNeXt Variant with Cross-Stage Partial Connections
Aug 28, 2025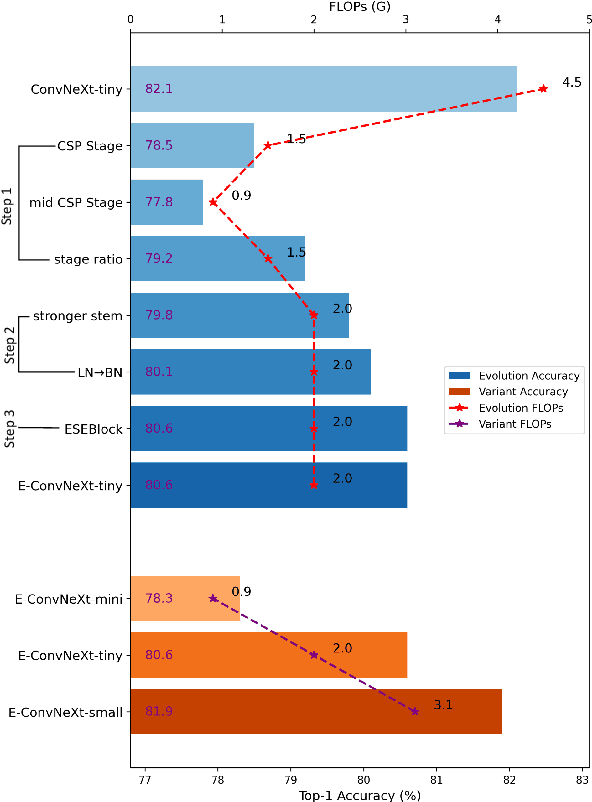

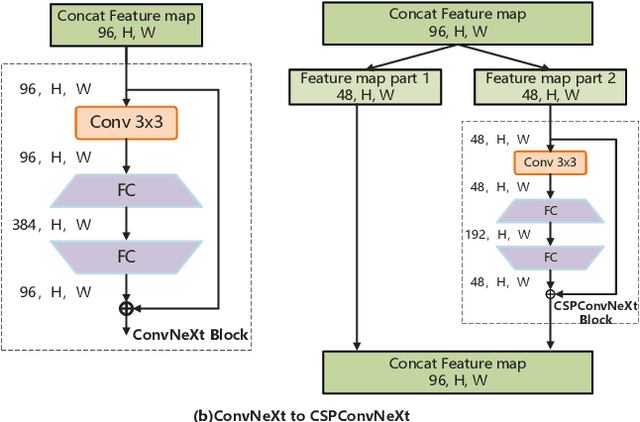
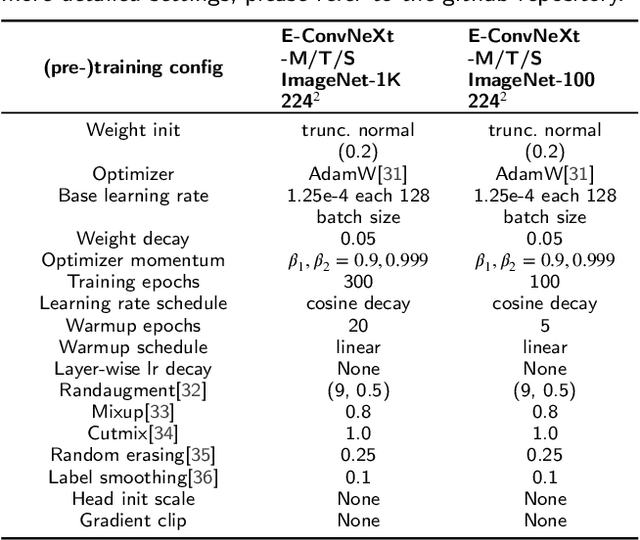
Many high-performance networks were not designed with lightweight application scenarios in mind from the outset, which has greatly restricted their scope of application. This paper takes ConvNeXt as the research object and significantly reduces the parameter scale and network complexity of ConvNeXt by integrating the Cross Stage Partial Connections mechanism and a series of optimized designs. The new network is named E-ConvNeXt, which can maintain high accuracy performance under different complexity configurations. The three core innovations of E-ConvNeXt are : (1) integrating the Cross Stage Partial Network (CSPNet) with ConvNeXt and adjusting the network structure, which reduces the model's network complexity by up to 80%; (2) Optimizing the Stem and Block structures to enhance the model's feature expression capability and operational efficiency; (3) Replacing Layer Scale with channel attention. Experimental validation on ImageNet classification demonstrates E-ConvNeXt's superior accuracy-efficiency balance: E-ConvNeXt-mini reaches 78.3% Top-1 accuracy at 0.9GFLOPs. E-ConvNeXt-small reaches 81.9% Top-1 accuracy at 3.1GFLOPs. Transfer learning tests on object detection tasks further confirm its generalization capability.
Incorporating Legal Logic into Deep Learning: An Intelligent Approach to Probation Prediction
Aug 17, 2025Probation is a crucial institution in modern criminal law, embodying the principles of fairness and justice while contributing to the harmonious development of society. Despite its importance, the current Intelligent Judicial Assistant System (IJAS) lacks dedicated methods for probation prediction, and research on the underlying factors influencing probation eligibility remains limited. In addition, probation eligibility requires a comprehensive analysis of both criminal circumstances and remorse. Much of the existing research in IJAS relies primarily on data-driven methodologies, which often overlooks the legal logic underpinning judicial decision-making. To address this gap, we propose a novel approach that integrates legal logic into deep learning models for probation prediction, implemented in three distinct stages. First, we construct a specialized probation dataset that includes fact descriptions and probation legal elements (PLEs). Second, we design a distinct probation prediction model named the Multi-Task Dual-Theory Probation Prediction Model (MT-DT), which is grounded in the legal logic of probation and the \textit{Dual-Track Theory of Punishment}. Finally, our experiments on the probation dataset demonstrate that the MT-DT model outperforms baseline models, and an analysis of the underlying legal logic further validates the effectiveness of the proposed approach.
HGCN(O): A Self-Tuning GCN HyperModel Toolkit for Outcome Prediction in Event-Sequence Data
Jul 30, 2025We propose HGCN(O), a self-tuning toolkit using Graph Convolutional Network (GCN) models for event sequence prediction. Featuring four GCN architectures (O-GCN, T-GCN, TP-GCN, TE-GCN) across the GCNConv and GraphConv layers, our toolkit integrates multiple graph representations of event sequences with different choices of node- and graph-level attributes and in temporal dependencies via edge weights, optimising prediction accuracy and stability for balanced and unbalanced datasets. Extensive experiments show that GCNConv models excel on unbalanced data, while all models perform consistently on balanced data. Experiments also confirm the superior performance of HGCN(O) over traditional approaches. Applications include Predictive Business Process Monitoring (PBPM), which predicts future events or states of a business process based on event logs.
CKD-EHR:Clinical Knowledge Distillation for Electronic Health Records
Jun 18, 2025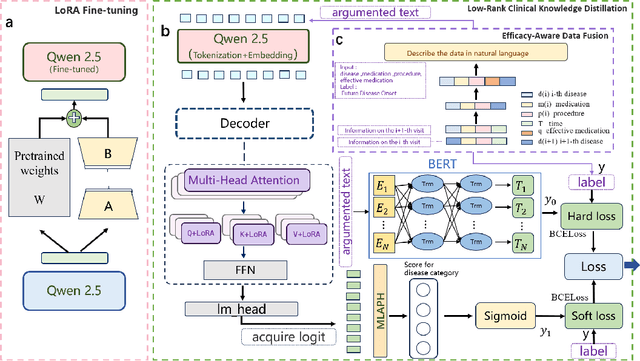
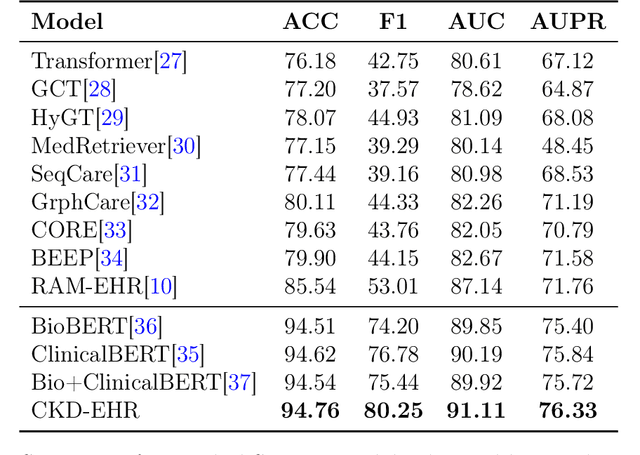

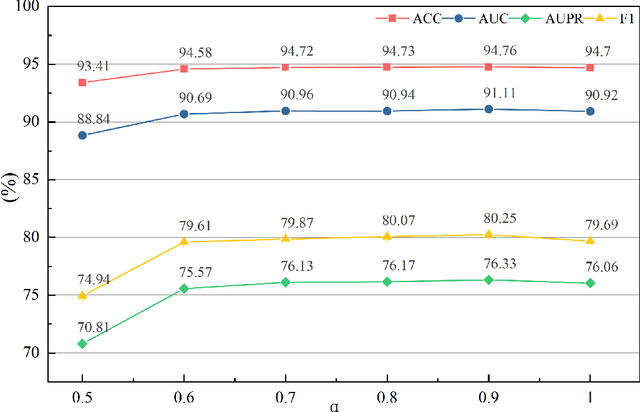
Electronic Health Records (EHR)-based disease prediction models have demonstrated significant clinical value in promoting precision medicine and enabling early intervention. However, existing large language models face two major challenges: insufficient representation of medical knowledge and low efficiency in clinical deployment. To address these challenges, this study proposes the CKD-EHR (Clinical Knowledge Distillation for EHR) framework, which achieves efficient and accurate disease risk prediction through knowledge distillation techniques. Specifically, the large language model Qwen2.5-7B is first fine-tuned on medical knowledge-enhanced data to serve as the teacher model.It then generates interpretable soft labels through a multi-granularity attention distillation mechanism. Finally, the distilled knowledge is transferred to a lightweight BERT student model. Experimental results show that on the MIMIC-III dataset, CKD-EHR significantly outperforms the baseline model:diagnostic accuracy is increased by 9%, F1-score is improved by 27%, and a 22.2 times inference speedup is achieved. This innovative solution not only greatly improves resource utilization efficiency but also significantly enhances the accuracy and timeliness of diagnosis, providing a practical technical approach for resource optimization in clinical settings. The code and data for this research are available athttps://github.com/209506702/CKD_EHR.
S2MNet: Speckle-To-Mesh Net for Three-Dimensional Cardiac Morphology Reconstruction via Echocardiogram
May 09, 2025

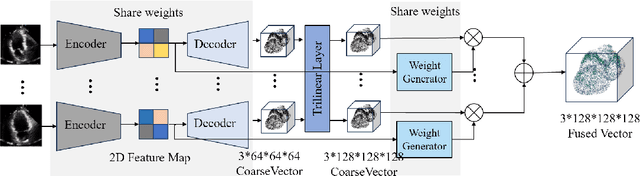
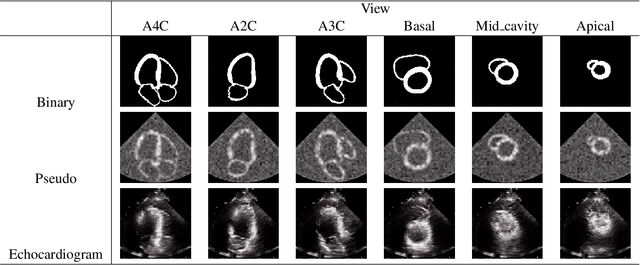
Echocardiogram is the most commonly used imaging modality in cardiac assessment duo to its non-invasive nature, real-time capability, and cost-effectiveness. Despite its advantages, most clinical echocardiograms provide only two-dimensional views, limiting the ability to fully assess cardiac anatomy and function in three dimensions. While three-dimensional echocardiography exists, it often suffers from reduced resolution, limited availability, and higher acquisition costs. To overcome these challenges, we propose a deep learning framework S2MNet that reconstructs continuous and high-fidelity 3D heart models by integrating six slices of routinely acquired 2D echocardiogram views. Our method has three advantages. First, our method avoid the difficulties on training data acquasition by simulate six of 2D echocardiogram images from corresponding slices of a given 3D heart mesh. Second, we introduce a deformation field-based method, which avoid spatial discontinuities or structural artifacts in 3D echocardiogram reconstructions. We validate our method using clinically collected echocardiogram and demonstrate that our estimated left ventricular volume, a key clinical indicator of cardiac function, is strongly correlated with the doctor measured GLPS, a clinical measurement that should demonstrate a negative correlation with LVE in medical theory. This association confirms the reliability of our proposed 3D construction method.
CoT-RAG: Integrating Chain of Thought and Retrieval-Augmented Generation to Enhance Reasoning in Large Language Models
Apr 18, 2025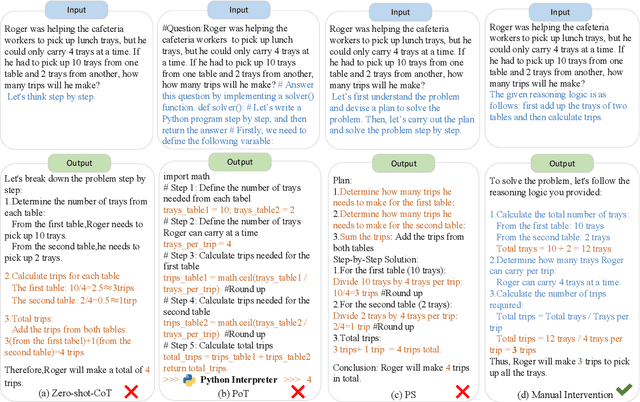

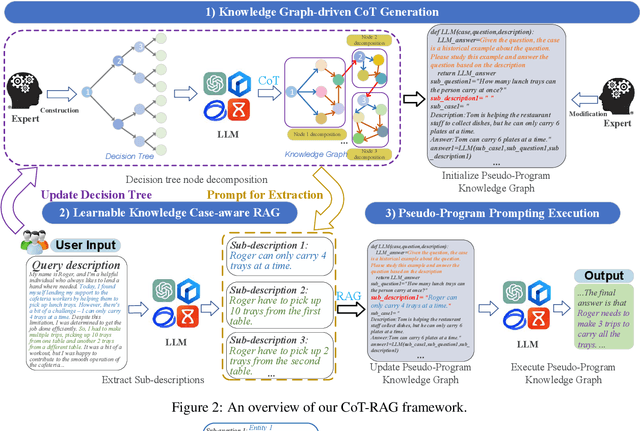

While chain-of-thought (CoT) reasoning improves the performance of large language models (LLMs) in complex tasks, it still has two main challenges: the low reliability of relying solely on LLMs to generate reasoning chains and the interference of natural language reasoning chains on the inference logic of LLMs. To address these issues, we propose CoT-RAG, a novel reasoning framework with three key designs: (i) Knowledge Graph-driven CoT Generation, featuring knowledge graphs to modulate reasoning chain generation of LLMs, thereby enhancing reasoning credibility; (ii) Learnable Knowledge Case-aware RAG, which incorporates retrieval-augmented generation (RAG) into knowledge graphs to retrieve relevant sub-cases and sub-descriptions, providing LLMs with learnable information; (iii) Pseudo-Program Prompting Execution, which encourages LLMs to execute reasoning tasks in pseudo-programs with greater logical rigor. We conduct a comprehensive evaluation on nine public datasets, covering three reasoning problems. Compared with the-state-of-the-art methods, CoT-RAG exhibits a significant accuracy improvement, ranging from 4.0% to 23.0%. Furthermore, testing on four domain-specific datasets, CoT-RAG shows remarkable accuracy and efficient execution, highlighting its strong practical applicability and scalability.