 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Extreme Operating Condition Search for Online Relay Setting Calculation in Renewable Power Systems Based on Parallel Graph Neural Network
Jun 24, 2025The Extreme Operating Conditions Search (EOCS) problem is one of the key problems in relay setting calculation, which is used to ensure that the setting values of protection relays can adapt to the changing operating conditions of power systems over a period of time after deployment. The high penetration of renewable energy and the wide application of inverter-based resources make the operating conditions of renewable power systems more volatile, which urges the adoption of the online relay setting calculation strategy. However, the computation speed of existing EOCS methods based on local enumeration, heuristic algorithms, and mathematical programming cannot meet the efficiency requirement of online relay setting calculation. To reduce the time overhead, this paper, for the first time, proposes an efficient deep learning-based EOCS method suitable for online relay setting calculation. First, the power system information is formulated as four layers, i.e., a component parameter layer, a topological connection layer, an electrical distance layer, and a graph distance layer, which are fed into a parallel graph neural network (PGNN) model for feature extraction. Then, the four feature layers corresponding to each node are spliced and stretched, and then fed into the decision network to predict the extreme operating condition of the system. Finally, the proposed PGNN method is validated on the modified IEEE 39-bus and 118-bus test systems, where some of the synchronous generators are replaced by renewable generation units. The nonlinear fault characteristics of renewables are fully considered when computing fault currents. The experiment results show that the proposed PGNN method achieves higher accuracy than the existing methods in solving the EOCS problem. Meanwhile, it also provides greater improvements in online computation time.
Shape-Guided Clothing Warping for Virtual Try-On
Apr 21, 2025Image-based virtual try-on aims to seamlessly fit in-shop clothing to a person image while maintaining pose consistency. Existing methods commonly employ the thin plate spline (TPS) transformation or appearance flow to deform in-shop clothing for aligning with the person's body. Despite their promising performance, these methods often lack precise control over fine details, leading to inconsistencies in shape between clothing and the person's body as well as distortions in exposed limb regions. To tackle these challenges, we propose a novel shape-guided clothing warping method for virtual try-on, dubbed SCW-VTON, which incorporates global shape constraints and additional limb textures to enhance the realism and consistency of the warped clothing and try-on results. To integrate global shape constraints for clothing warping, we devise a dual-path clothing warping module comprising a shape path and a flow path. The former path captures the clothing shape aligned with the person's body, while the latter path leverages the mapping between the pre- and post-deformation of the clothing shape to guide the estimation of appearance flow. Furthermore, to alleviate distortions in limb regions of try-on results, we integrate detailed limb guidance by developing a limb reconstruction network based on masked image modeling. Through the utilization of SCW-VTON, we are able to generate try-on results with enhanced clothing shape consistency and precise control over details. Extensive experiments demonstrate the superiority of our approach over state-of-the-art methods both qualitatively and quantitatively. The code is available at https://github.com/xyhanHIT/SCW-VTON.
Limb-Aware Virtual Try-On Network with Progressive Clothing Warping
Mar 18, 2025
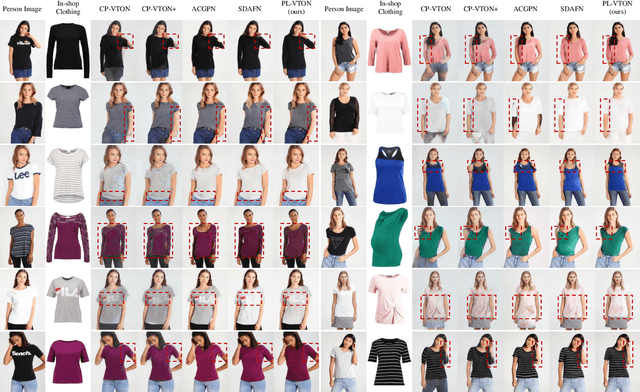


Image-based virtual try-on aims to transfer an in-shop clothing image to a person image. Most existing methods adopt a single global deformation to perform clothing warping directly, which lacks fine-grained modeling of in-shop clothing and leads to distorted clothing appearance. In addition, existing methods usually fail to generate limb details well because they are limited by the used clothing-agnostic person representation without referring to the limb textures of the person image. To address these problems, we propose Limb-aware Virtual Try-on Network named PL-VTON, which performs fine-grained clothing warping progressively and generates high-quality try-on results with realistic limb details. Specifically, we present Progressive Clothing Warping (PCW) that explicitly models the location and size of in-shop clothing and utilizes a two-stage alignment strategy to progressively align the in-shop clothing with the human body. Moreover, a novel gravity-aware loss that considers the fit of the person wearing clothing is adopted to better handle the clothing edges. Then, we design Person Parsing Estimator (PPE) with a non-limb target parsing map to semantically divide the person into various regions, which provides structural constraints on the human body and therefore alleviates texture bleeding between clothing and body regions. Finally, we introduce Limb-aware Texture Fusion (LTF) that focuses on generating realistic details in limb regions, where a coarse try-on result is first generated by fusing the warped clothing image with the person image, then limb textures are further fused with the coarse result under limb-aware guidance to refine limb details. Extensive experiments demonstrate that our PL-VTON outperforms the state-of-the-art methods both qualitatively and quantitatively.
* Accepted by IEEE Transactions on Multimedia (TMM). The code is available at https://github.com/aipixel/PL-VTONv2
Progressive Limb-Aware Virtual Try-On
Mar 16, 2025Existing image-based virtual try-on methods directly transfer specific clothing to a human image without utilizing clothing attributes to refine the transferred clothing geometry and textures, which causes incomplete and blurred clothing appearances. In addition, these methods usually mask the limb textures of the input for the clothing-agnostic person representation, which results in inaccurate predictions for human limb regions (i.e., the exposed arm skin), especially when transforming between long-sleeved and short-sleeved garments. To address these problems, we present a progressive virtual try-on framework, named PL-VTON, which performs pixel-level clothing warping based on multiple attributes of clothing and embeds explicit limb-aware features to generate photo-realistic try-on results. Specifically, we design a Multi-attribute Clothing Warping (MCW) module that adopts a two-stage alignment strategy based on multiple attributes to progressively estimate pixel-level clothing displacements. A Human Parsing Estimator (HPE) is then introduced to semantically divide the person into various regions, which provides structural constraints on the human body and therefore alleviates texture bleeding between clothing and limb regions. Finally, we propose a Limb-aware Texture Fusion (LTF) module to estimate high-quality details in limb regions by fusing textures of the clothing and the human body with the guidance of explicit limb-aware features. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art virtual try-on methods both qualitatively and quantitatively. The code is available at https://github.com/xyhanHIT/PL-VTON.
LexPro-1.0 Technical Report
Mar 11, 2025In this report, we introduce our first-generation reasoning model, LexPro-1.0, a large language model designed for the highly specialized Chinese legal domain, offering comprehensive capabilities to meet diverse realistic needs. Existing legal LLMs face two primary challenges. Firstly, their design and evaluation are predominantly driven by computer science perspectives, leading to insufficient incorporation of legal expertise and logic, which is crucial for high-precision legal applications, such as handling complex prosecutorial tasks. Secondly, these models often underperform due to a lack of comprehensive training data from the legal domain, limiting their ability to effectively address real-world legal scenarios. To address this, we first compile millions of legal documents covering over 20 types of crimes from 31 provinces in China for model training. From the extensive dataset, we further select high-quality for supervised fine-tuning, ensuring enhanced relevance and precision. The model further undergoes large-scale reinforcement learning without additional supervision, emphasizing the enhancement of its reasoning capabilities and explainability. To validate its effectiveness in complex legal applications, we also conduct human evaluations with legal experts. We develop fine-tuned models based on DeepSeek-R1-Distilled versions, available in three dense configurations: 14B, 32B, and 70B.