 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexPro-1.0 Technical Report
Mar 11, 2025In this report, we introduce our first-generation reasoning model, LexPro-1.0, a large language model designed for the highly specialized Chinese legal domain, offering comprehensive capabilities to meet diverse realistic needs. Existing legal LLMs face two primary challenges. Firstly, their design and evaluation are predominantly driven by computer science perspectives, leading to insufficient incorporation of legal expertise and logic, which is crucial for high-precision legal applications, such as handling complex prosecutorial tasks. Secondly, these models often underperform due to a lack of comprehensive training data from the legal domain, limiting their ability to effectively address real-world legal scenarios. To address this, we first compile millions of legal documents covering over 20 types of crimes from 31 provinces in China for model training. From the extensive dataset, we further select high-quality for supervised fine-tuning, ensuring enhanced relevance and precision. The model further undergoes large-scale reinforcement learning without additional supervision, emphasizing the enhancement of its reasoning capabilities and explainability. To validate its effectiveness in complex legal applications, we also conduct human evaluations with legal experts. We develop fine-tuned models based on DeepSeek-R1-Distilled versions, available in three dense configurations: 14B, 32B, and 70B.
Multi-modal Food Recommendation using Clustering and Self-supervised Learning
Jun 27, 2024



Food recommendation systems serve as pivotal components in the realm of digital lifestyle services, designed to assist users in discovering recipes and food items that resonate with their unique dietary predilections. Typically, multi-modal descriptions offer an exhaustive profile for each recipe, thereby ensuring recommendations that are both personalized and accurate. Our preliminary investigation of two datasets indicates that pre-trained multi-modal dense representations might precipitate a deterioration in performance compared to ID features when encapsulating interactive relationships. This observation implies that ID features possess a relative superiority in modeling interactive collaborative signals. Consequently, contemporary cutting-edge methodologies augment ID features with multi-modal information as supplementary features, overlooking the latent semantic relations between recipes. To rectify this, we present CLUSSL, a novel food recommendation framework that employs clustering and self-supervised learning. Specifically, CLUSSL formulates a modality-specific graph tailored to each modality with discrete/continuous features, thereby transforming semantic features into structural representation. Furthermore, CLUSSL procures recipe representations pertinent to different modalities via graph convolutional operations. A self-supervised learning objective is proposed to foster independence between recipe representations derived from different unimodal graphs. Comprehensive experiments on real-world datasets substantiate that CLUSSL consistently surpasses state-of-the-art recommendation benchmarks in performance.
A Critical Look at Classic Test-Time Adaptation Methods in Semantic Segmentation
Oct 11, 2023Test-time adaptation (TTA) aims to adapt a model, initially trained on training data, to potential distribution shifts in the test data. Most existing TTA studies, however, focus on classification tasks, leaving a notable gap in the exploration of TTA for semantic segmentation. This pronounced emphasis on classification might lead numerous newcomers and engineers to mistakenly assume that classic TTA methods designed for classification can be directly applied to segmentation. Nonetheless, this assumption remains unverified, posing an open question. To address this, we conduct a systematic, empirical study to disclose the unique challenges of segmentation TTA, and to determine whether classic TTA strategies can effectively address this task. Our comprehensive results have led to three key observations. First, the classic batch norm updating strategy, commonly used in classification TTA, only brings slight performance improvement, and in some cases it might even adversely affect the results. Even with the application of advanced distribution estimation techniques like batch renormalization, the problem remains unresolved. Second, the teacher-student scheme does enhance training stability for segmentation TTA in the presence of noisy pseudo-labels. However, it cannot directly result in performance improvement compared to the original model without TTA. Third, segmentation TTA suffers a severe long-tailed imbalance problem, which is substantially more complex than that in TTA for classification. This long-tailed challenge significantly affects segmentation TTA performance, even when the accuracy of pseudo-labels is high. In light of these observations, we conclude that TTA for segmentation presents significant challenges, and simply using classic TTA methods cannot address this problem well.
Unsupervised Representation Learning for Time Series: A Review
Aug 03, 2023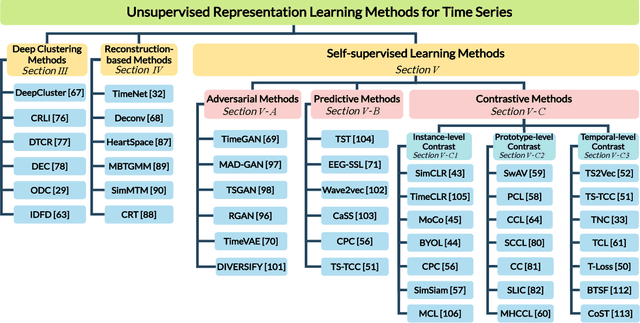
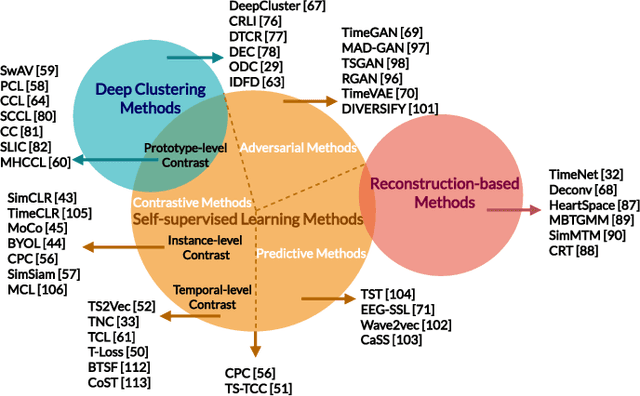
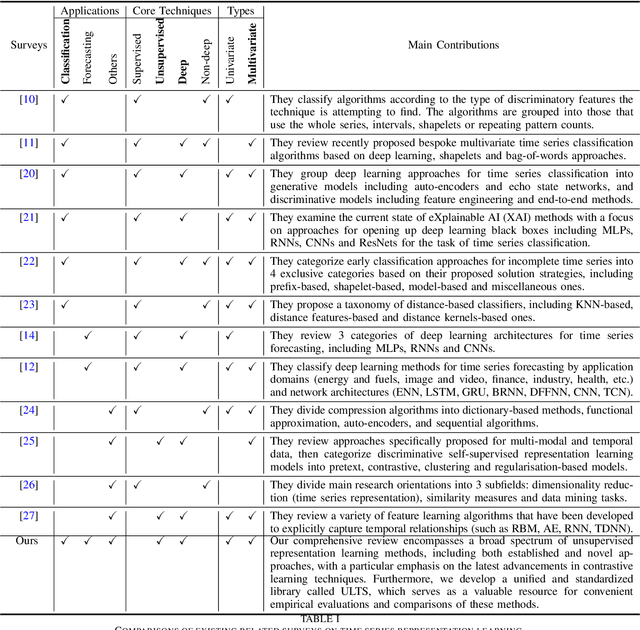

Unsupervised representation learning approaches aim to learn discriminative feature representations from unlabeled data, without the requirement of annotating every sample. Enabling unsupervised representation learning is extremely crucial for time series data, due to its unique annotation bottleneck caused by its complex characteristics and lack of visual cues compared with other data modalities. In recent years, unsupervised representation learning techniques have advanced rapidly in various domains. However, there is a lack of systematic analysis of unsupervised representation learning approaches for time series. To fill the gap, we conduct a comprehensive literature review of existing rapidly evolving unsupervised representation learning approaches for time series. Moreover, we also develop a unified and standardized library, named ULTS (i.e., Unsupervised Learning for Time Series), to facilitate fast implementations and unified evaluations on various models. With ULTS, we empirically evaluate state-of-the-art approaches, especially the rapidly evolving contrastive learning methods, on 9 diverse real-world datasets. We further discuss practical considerations as well as open research challenges on unsupervised representation learning for time series to facilitate future research in this field.
Model-Contrastive Federated Domain Adaptation
May 07, 2023Federated domain adaptation (FDA) aims to collaboratively transfer knowledge from source clients (domains) to the related but different target client, without communicating the local data of any client. Moreover, the source clients have different data distributions, leading to extremely challenging in knowledge transfer. Despite the recent progress in FDA, we empirically find that existing methods can not leverage models of heterogeneous domains and thus they fail to achieve excellent performance. In this paper, we propose a model-based method named FDAC, aiming to address {\bf F}ederated {\bf D}omain {\bf A}daptation based on {\bf C}ontrastive learning and Vision Transformer (ViT). In particular, contrastive learning can leverage the unlabeled data to train excellent models and the ViT architecture performs better than convolutional neural networks (CNNs) in extracting adaptable features. To the best of our knowledge, FDAC is the first attempt to learn transferable representations by manipulating the latent architecture of ViT under the federated setting. Furthermore, FDAC can increase the target data diversity by compensating from each source model with insufficient knowledge of samples and features, based on domain augmentation and semantic matching. Extensive experiments on several real datasets demonstrate that FDAC outperforms all the comparative methods in most conditions. Moreover, FDCA can also improve communication efficiency which is another key factor in the federated setting.
Dual Graph Multitask Framework for Imbalanced Delivery Time Estimation
Feb 17, 2023Delivery Time Estimation (DTE) is a crucial component of the e-commerce supply chain that predicts delivery time based on merchant information, sending address, receiving address, and payment time. Accurate DTE can boost platform revenue and reduce customer complaints and refunds. However, the imbalanced nature of industrial data impedes previous models from reaching satisfactory prediction performance. Although imbalanced regression methods can be applied to the DTE task, we experimentally find that they improve the prediction performance of low-shot data samples at the sacrifice of overall performance. To address the issue, we propose a novel Dual Graph Multitask framework for imbalanced Delivery Time Estimation (DGM-DTE). Our framework first classifies package delivery time as head and tail data. Then, a dual graph-based model is utilized to learn representations of the two categories of data. In particular, DGM-DTE re-weights the embedding of tail data by estimating its kernel density. We fuse two graph-based representations to capture both high- and low-shot data representations. Experiments on real-world Taobao logistics datasets demonstrate the superior performance of DGM-DTE compared to baselines.
Towards AI-Empowered Crowdsourcing
Dec 28, 2022Crowdsourcing, in which human intelligence and productivity is dynamically mobilized to tackle tasks too complex for automation alone to handle, has grown to be an important research topic and inspired new businesses (e.g., Uber, Airbnb). Over the years, crowdsourcing has morphed from providing a platform where workers and tasks can be matched up manually into one which leverages data-driven algorithmic management approaches powered by artificial intelligence (AI) to achieve increasingly sophisticated optimization objectives. In this paper, we provide a survey presenting a unique systematic overview on how AI can empower crowdsourcing - which we refer to as AI-Empowered Crowdsourcing(AIEC). We propose a taxonomy which divides algorithmic crowdsourcing into three major areas: 1) task delegation, 2) motivating workers, and 3) quality control, focusing on the major objectives which need to be accomplished. We discuss the limitations and insights, and curate the challenges of doing research in each of these areas to highlight promising future research directions.
A Survey on Federated Recommendation Systems
Dec 27, 2022Federated learning has recently been applied to recommendation systems to protect user privacy. In federated learning settings, recommendation systems can train recommendation models only collecting the intermediate parameters instead of the real user data, which greatly enhances the user privacy. Beside, federated recommendation systems enable to collaborate with other data platforms to improve recommended model performance while meeting the regulation and privacy constraints. However, federated recommendation systems faces many new challenges such as privacy, security, heterogeneity and communication costs. While significant research has been conducted in these areas, gaps in the surveying literature still exist. In this survey, we-(1) summarize some common privacy mechanisms used in federated recommendation systems and discuss the advantages and limitations of each mechanism; (2) review some robust aggregation strategies and several novel attacks against security; (3) summarize some approaches to address heterogeneity and communication costs problems; (4)introduce some open source platforms that can be used to build federated recommendation systems; (5) present some prospective research directions in the future. This survey can guide researchers and practitioners understand the research progress in these areas.
MHCCL: Masked Hierarchical Cluster-wise Contrastive Learning for Multivariate Time Series
Dec 02, 2022Learning semantic-rich representations from raw unlabeled time series data is critical for downstream tasks such as classification and forecasting. Contrastive learning has recently shown its promising representation learning capability in the absence of expert annotations. However, existing contrastive approaches generally treat each instance independently, which leads to false negative pairs that share the same semantics. To tackle this problem, we propose MHCCL, a Masked Hierarchical Cluster-wise Contrastive Learning model, which exploits semantic information obtained from the hierarchical structure consisting of multiple latent partitions for multivariate time series. Motivated by the observation that fine-grained clustering preserves higher purity while coarse-grained one reflects higher-level semantics, we propose a novel downward masking strategy to filter out fake negatives and supplement positives by incorporating the multi-granularity information from the clustering hierarchy. In addition, a novel upward masking strategy is designed in MHCCL to remove outliers of clusters at each partition to refine prototypes, which helps speed up the hierarchical clustering process and improves the clustering quality. We conduct experimental evaluations on seven widely-used multivariate time series datasets. The results demonstrate the superiority of MHCCL over the state-of-the-art approaches for unsupervised time series representation learning.
Enhancing Sequential Recommendation with Graph Contrastive Learning
Jun 07, 2022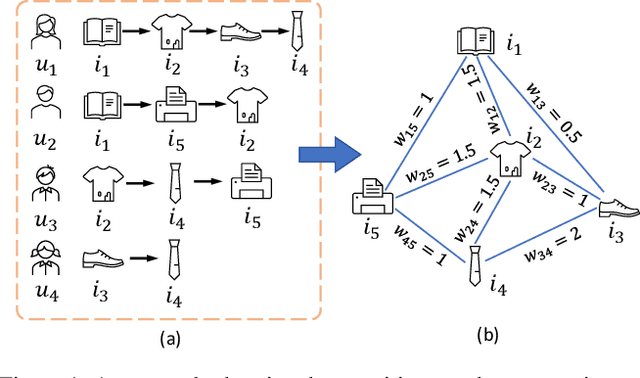
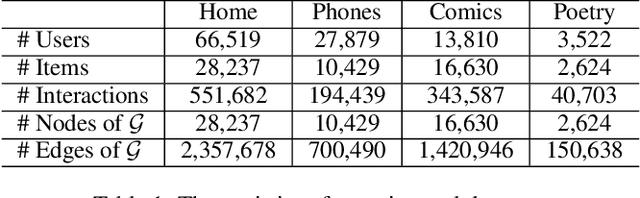
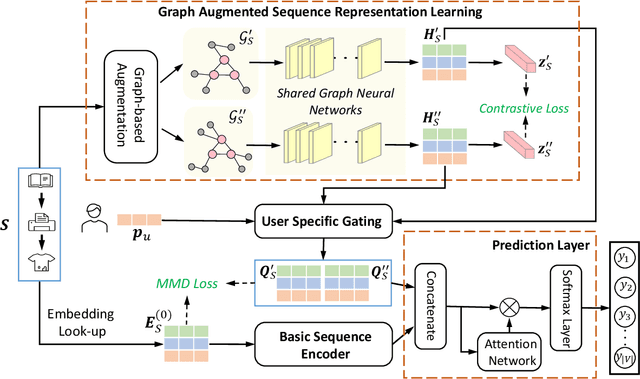
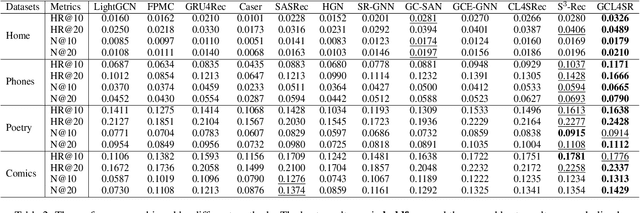
The sequential recommendation systems capture users' dynamic behavior patterns to predict their next interaction behaviors. Most existing sequential recommendation methods only exploit the local context information of an individual interaction sequence and learn model parameters solely based on the item prediction loss. Thus, they usually fail to learn appropriate sequence representations. This paper proposes a novel recommendation framework, namely Graph Contrastive Learning for Sequential Recommendation (GCL4SR). Specifically, GCL4SR employs a Weighted Item Transition Graph (WITG), built based on interaction sequences of all users, to provide global context information for each interaction and weaken the noise information in the sequence data. Moreover, GCL4SR uses subgraphs of WITG to augment the representation of each interaction sequence. Two auxiliary learning objectives have also been proposed to maximize the consistency between augmented representations induced by the same interaction sequence on WITG, and minimize the difference between the representations augmented by the global context on WITG and the local representation of the original sequence. Extensive experiments on real-world datasets demonstrate that GCL4SR consistently outperforms state-of-the-art sequential recommendation methods.