 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Molecular Discovery with Natural Language
Jun 21, 2023Natural language is expected to be a key medium for various human-machine interactions in the era of large language models. When it comes to the biochemistry field, a series of tasks around molecules (e.g., property prediction, molecule mining, etc.) are of great significance while having a high technical threshold. Bridging the molecule expressions in natural language and chemical language can not only hugely improve the interpretability and reduce the operation difficulty of these tasks, but also fuse the chemical knowledge scattered in complementary materials for a deeper comprehension of molecules. Based on these benefits, we propose the conversational molecular design, a novel task adopting natural language for describing and editing target molecules. To better accomplish this task, we design ChatMol, a knowledgeable and versatile generative pre-trained model, enhanced by injecting experimental property information, molecular spatial knowledge, and the associations between natural and chemical languages into it. Several typical solutions including large language models (e.g., ChatGPT) are evaluated, proving the challenge of conversational molecular design and the effectiveness of our knowledge enhancement method. Case observations and analysis are conducted to provide directions for further exploration of natural-language interaction in molecular discovery.
Towards AI-Empowered Crowdsourcing
Dec 28, 2022Crowdsourcing, in which human intelligence and productivity is dynamically mobilized to tackle tasks too complex for automation alone to handle, has grown to be an important research topic and inspired new businesses (e.g., Uber, Airbnb). Over the years, crowdsourcing has morphed from providing a platform where workers and tasks can be matched up manually into one which leverages data-driven algorithmic management approaches powered by artificial intelligence (AI) to achieve increasingly sophisticated optimization objectives. In this paper, we provide a survey presenting a unique systematic overview on how AI can empower crowdsourcing - which we refer to as AI-Empowered Crowdsourcing(AIEC). We propose a taxonomy which divides algorithmic crowdsourcing into three major areas: 1) task delegation, 2) motivating workers, and 3) quality control, focusing on the major objectives which need to be accomplished. We discuss the limitations and insights, and curate the challenges of doing research in each of these areas to highlight promising future research directions.
Training Networks in Null Space of Feature Covariance for Continual Learning
Mar 17, 2021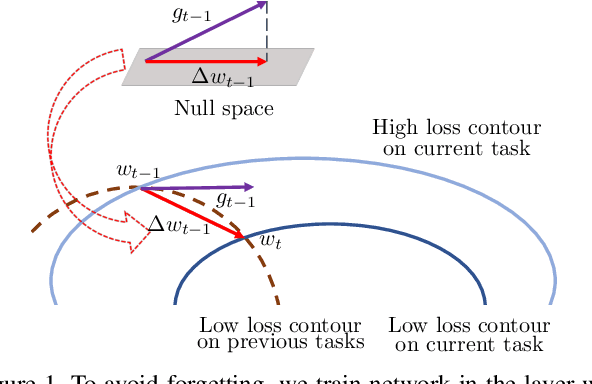
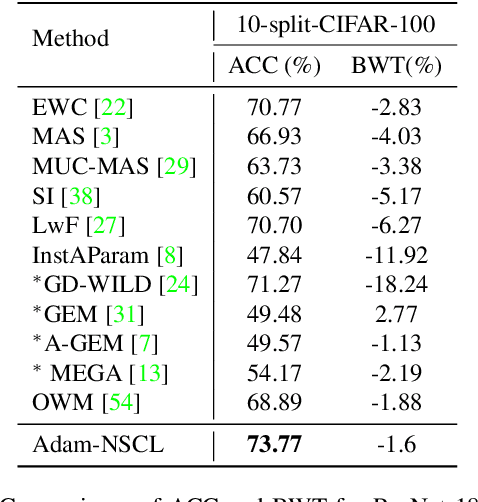
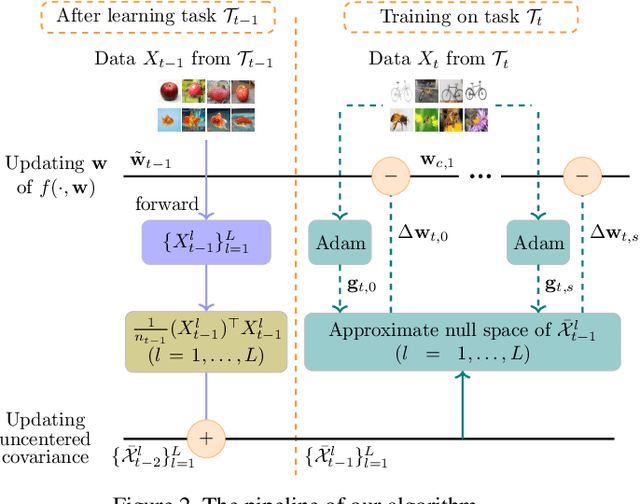
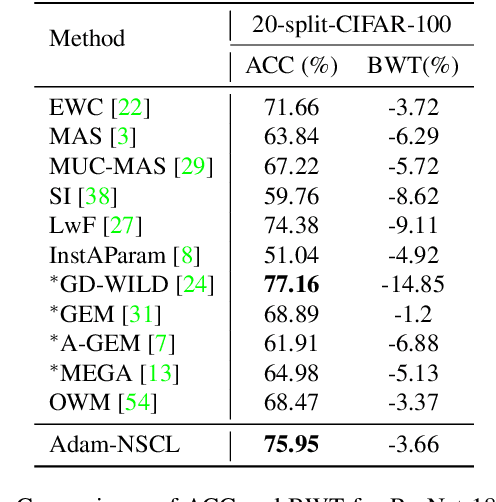
In the setting of continual learning, a network is trained on a sequence of tasks, and suffers from catastrophic forgetting. To balance plasticity and stability of network in continual learning, in this paper, we propose a novel network training algorithm called Adam-NSCL, which sequentially optimizes network parameters in the null space of previous tasks. We first propose two mathematical conditions respectively for achieving network stability and plasticity in continual learning. Based on them, the network training for sequential tasks can be simply achieved by projecting the candidate parameter update into the approximate null space of all previous tasks in the network training process, where the candidate parameter update can be generated by Adam. The approximate null space can be derived by applying singular value decomposition to the uncentered covariance matrix of all input features of previous tasks for each linear layer. For efficiency, the uncentered covariance matrix can be incrementally computed after learning each task. We also empirically verify the rationality of the approximate null space at each linear layer. We apply our approach to training networks for continual learning on benchmark datasets of CIFAR-100 and TinyImageNet, and the results suggest that the proposed approach outperforms or matches the state-ot-the-art continual learning approaches.
HyperAdam: A Learnable Task-Adaptive Adam for Network Training
Nov 22, 2018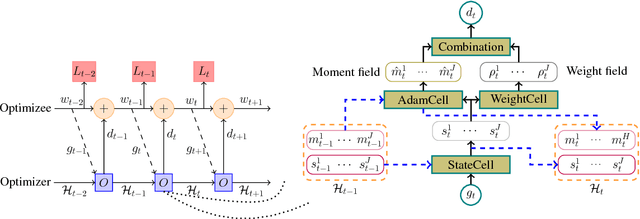

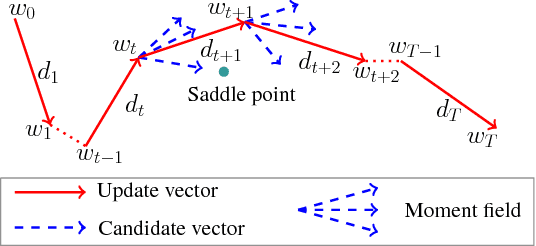

Deep neural networks are traditionally trained using human-designed stochastic optimization algorithms, such as SGD and Adam. Recently, the approach of learning to optimize network parameters has emerged as a promising research topic. However, these learned black-box optimizers sometimes do not fully utilize the experience in human-designed optimizers, therefore have limitation in generalization ability. In this paper, a new optimizer, dubbed as \textit{HyperAdam}, is proposed that combines the idea of "learning to optimize" and traditional Adam optimizer. Given a network for training, its parameter update in each iteration generated by HyperAdam is an adaptive combination of multiple updates generated by Adam with varying decay rates. The combination weights and decay rates in HyperAdam are adaptively learned depending on the task. HyperAdam is modeled as a recurrent neural network with AdamCell, WeightCell and StateCell. It is justified to be state-of-the-art for various network training, such as multilayer perceptron, CNN and LSTM.