 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards AI-Empowered Crowdsourcing
Dec 28, 2022Crowdsourcing, in which human intelligence and productivity is dynamically mobilized to tackle tasks too complex for automation alone to handle, has grown to be an important research topic and inspired new businesses (e.g., Uber, Airbnb). Over the years, crowdsourcing has morphed from providing a platform where workers and tasks can be matched up manually into one which leverages data-driven algorithmic management approaches powered by artificial intelligence (AI) to achieve increasingly sophisticated optimization objectives. In this paper, we provide a survey presenting a unique systematic overview on how AI can empower crowdsourcing - which we refer to as AI-Empowered Crowdsourcing(AIEC). We propose a taxonomy which divides algorithmic crowdsourcing into three major areas: 1) task delegation, 2) motivating workers, and 3) quality control, focusing on the major objectives which need to be accomplished. We discuss the limitations and insights, and curate the challenges of doing research in each of these areas to highlight promising future research directions.
Long-tail Cross Modal Hashing
Nov 28, 2022



Existing Cross Modal Hashing (CMH) methods are mainly designed for balanced data, while imbalanced data with long-tail distribution is more general in real-world. Several long-tail hashing methods have been proposed but they can not adapt for multi-modal data, due to the complex interplay between labels and individuality and commonality information of multi-modal data. Furthermore, CMH methods mostly mine the commonality of multi-modal data to learn hash codes, which may override tail labels encoded by the individuality of respective modalities. In this paper, we propose LtCMH (Long-tail CMH) to handle imbalanced multi-modal data. LtCMH firstly adopts auto-encoders to mine the individuality and commonality of different modalities by minimizing the dependency between the individuality of respective modalities and by enhancing the commonality of these modalities. Then it dynamically combines the individuality and commonality with direct features extracted from respective modalities to create meta features that enrich the representation of tail labels, and binaries meta features to generate hash codes. LtCMH significantly outperforms state-of-the-art baselines on long-tail datasets and holds a better (or comparable) performance on datasets with balanced labels.
Few-Shot Partial-Label Learning
Jun 02, 2021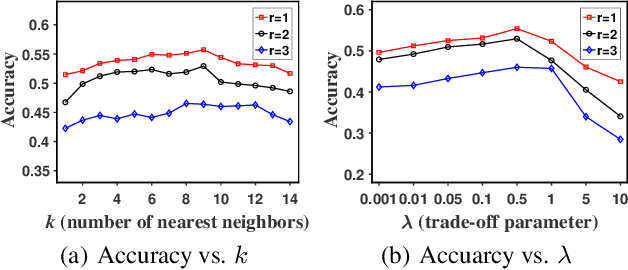
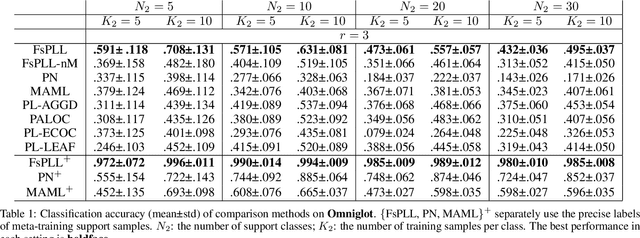
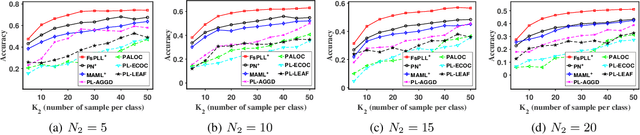
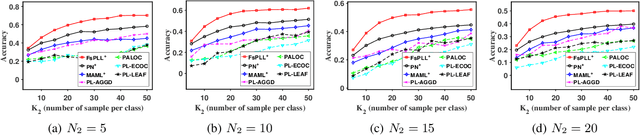
Partial-label learning (PLL) generally focuses on inducing a noise-tolerant multi-class classifier by training on overly-annotated samples, each of which is annotated with a set of labels, but only one is the valid label. A basic promise of existing PLL solutions is that there are sufficient partial-label (PL) samples for training. However, it is more common than not to have just few PL samples at hand when dealing with new tasks. Furthermore, existing few-shot learning algorithms assume precise labels of the support set; as such, irrelevant labels may seriously mislead the meta-learner and thus lead to a compromised performance. How to enable PLL under a few-shot learning setting is an important problem, but not yet well studied. In this paper, we introduce an approach called FsPLL (Few-shot PLL). FsPLL first performs adaptive distance metric learning by an embedding network and rectifying prototypes on the tasks previously encountered. Next, it calculates the prototype of each class of a new task in the embedding network. An unseen example can then be classified via its distance to each prototype. Experimental results on widely-used few-shot datasets (Omniglot and miniImageNet) demonstrate that our FsPLL can achieve a superior performance than the state-of-the-art methods across different settings, and it needs fewer samples for quickly adapting to new tasks.