 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Inference for OneRec-V2
Mar 12, 2026Quantized inference has demonstrated substantial system-level benefits in large language models while preserving model quality. In contrast, reliably applying low-precision quantization to recommender systems remains challenging in industrial settings. This difficulty arises from differences in training paradigms, architectural patterns, and computational characteristics, which lead to distinct numerical behaviors in weights and activations. Traditional recommender models often exhibit high-magnitude and high-variance weights and activations, making them more sensitive to quantization-induced perturbations. In addition, recommendation workloads frequently suffer from limited hardware utilization, limiting the practical gains of low-precision computation. In this work, we revisit low-precision inference in the context of generative recommendation. Through empirical distribution analysis, we show that the weight and activation statistics of OneRec-V2 are significantly more controlled and closer to those of large language models than traditional recommendation models. Moreover, OneRec-V2 exhibits a more compute-intensive inference pattern with substantially higher hardware utilization, enabling more end-to-end throughput gains with low-precision computation. Leveraging this property, we develop a FP8 post training quantization framework and integrate it into an optimized inference infrastructure. The proposed joint optimization achieves a 49\% reduction in end-to-end inference latency and a 92\% increase in throughput. Extensive online A/B testing further confirms that FP8 inference introduces no degradation in core metrics. These results suggest that as recommender systems evolve toward the paradigms of large language models, algorithm-level and system-level optimization techniques established in the LLM domain can be effectively adapted to large-scale recommendation workloads.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025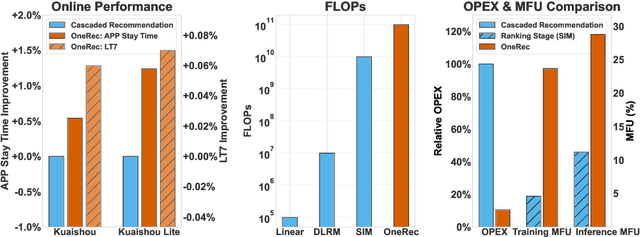

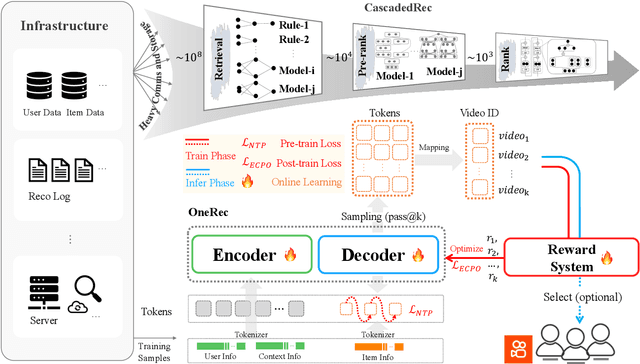

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Knowledge Fused Recognition: Fusing Hierarchical Knowledge for Image Recognition through Quantitative Relativity Modeling and Deep Metric Learning
Jul 30, 2024Image recognition is an essential baseline for deep metric learning. Hierarchical knowledge about image classes depicts inter-class similarities or dissimilarities. Effective fusion of hierarchical knowledge about image classes to enhance image recognition remains a challenging topic to advance. In this paper, we propose a novel deep metric learning based method to effectively fuse hierarchical prior knowledge about image classes and enhance image recognition performances in an end-to-end supervised regression manner. Existing deep metric learning incorporated image classification mainly exploits qualitative relativity between image classes, i.e., whether sampled images are from the same class. A new triplet loss function term that exploits quantitative relativity and aligns distances in model latent space with those in knowledge space is also proposed and incorporated in the proposed dual-modality fusion method. Experimental results indicate that the proposed method enhanced image recognition performances and outperformed baseline and existing methods on CIFAR-10, CIFAR-100, Mini-ImageNet, and ImageNet-1K datasets.
Socialized Learning: A Survey of the Paradigm Shift for Edge Intelligence in Networked Systems
Apr 20, 2024Amidst the robust impetus from artificial intelligence (AI) and big data, edge intelligence (EI) has emerged as a nascent computing paradigm, synthesizing AI with edge computing (EC) to become an exemplary solution for unleashing the full potential of AI services. Nonetheless, challenges in communication costs, resource allocation, privacy, and security continue to constrain its proficiency in supporting services with diverse requirements. In response to these issues, this paper introduces socialized learning (SL) as a promising solution, further propelling the advancement of EI. SL is a learning paradigm predicated on social principles and behaviors, aimed at amplifying the collaborative capacity and collective intelligence of agents within the EI system. SL not only enhances the system's adaptability but also optimizes communication, and networking processes, essential for distributed intelligence across diverse devices and platforms. Therefore, a combination of SL and EI may greatly facilitate the development of collaborative intelligence in the future network. This paper presents the findings of a literature review on the integration of EI and SL, summarizing the latest achievements in existing research on EI and SL. Subsequently, we delve comprehensively into the limitations of EI and how it could benefit from SL. Special emphasis is placed on the communication challenges and networking strategies and other aspects within these systems, underlining the role of optimized network solutions in improving system efficacy. Based on these discussions, we elaborate in detail on three integrated components: socialized architecture, socialized training, and socialized inference, analyzing their strengths and weaknesses. Finally, we identify some possible future applications of combining SL and EI, discuss open problems and suggest some future research.
Calibration-compatible Listwise Distillation of Privileged Features for CTR Prediction
Dec 14, 2023



In machine learning systems, privileged features refer to the features that are available during offline training but inaccessible for online serving. Previous studies have recognized the importance of privileged features and explored ways to tackle online-offline discrepancies. A typical practice is privileged features distillation (PFD): train a teacher model using all features (including privileged ones) and then distill the knowledge from the teacher model using a student model (excluding the privileged features), which is then employed for online serving. In practice, the pointwise cross-entropy loss is often adopted for PFD. However, this loss is insufficient to distill the ranking ability for CTR prediction. First, it does not consider the non-i.i.d. characteristic of the data distribution, i.e., other items on the same page significantly impact the click probability of the candidate item. Second, it fails to consider the relative item order ranked by the teacher model's predictions, which is essential to distill the ranking ability. To address these issues, we first extend the pointwise-based PFD to the listwise-based PFD. We then define the calibration-compatible property of distillation loss and show that commonly used listwise losses do not satisfy this property when employed as distillation loss, thus compromising the model's calibration ability, which is another important measure for CTR prediction. To tackle this dilemma, we propose Calibration-compatible LIstwise Distillation (CLID), which employs carefully-designed listwise distillation loss to achieve better ranking ability than the pointwise-based PFD while preserving the model's calibration ability. We theoretically prove it is calibration-compatible. Extensive experiments on public datasets and a production dataset collected from the display advertising system of Alibaba further demonstrate the effectiveness of CLID.
Entire Space Cascade Delayed Feedback Modeling for Effective Conversion Rate Prediction
Aug 09, 2023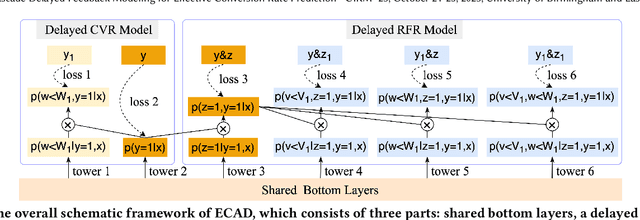
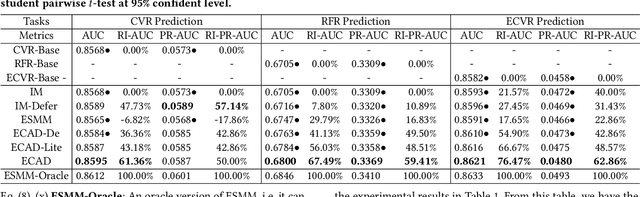
Conversion rate (CVR) prediction is an essential task for large-scale e-commerce platforms. However, refund behaviors frequently occur after conversion in online shopping systems, which drives us to pay attention to effective conversion for building healthier shopping services. This paper defines the probability of item purchasing without any subsequent refund as an effective conversion rate (ECVR). A simple paradigm for ECVR prediction is to decompose it into two sub-tasks: CVR prediction and post-conversion refund rate (RFR) prediction. However, RFR prediction suffers from data sparsity (DS) and sample selection bias (SSB) issues, as the refund behaviors are only available after user purchase. Furthermore, there is delayed feedback in both conversion and refund events and they are sequentially dependent, named cascade delayed feedback (CDF), which significantly harms data freshness for model training. Previous studies mainly focus on tackling DS and SSB or delayed feedback for a single event. To jointly tackle these issues in ECVR prediction, we propose an Entire space CAscade Delayed feedback modeling (ECAD) method. Specifically, ECAD deals with DS and SSB by constructing two tasks including CVR prediction and conversion \& refund rate (CVRFR) prediction using the entire space modeling framework. In addition, it carefully schedules auxiliary tasks to leverage both conversion and refund time within data to alleviate CDF. Experimental results on the offline industrial dataset and online A/B testing demonstrate the effectiveness of ECAD. In addition, ECAD has been deployed in one of the recommender systems in Alibaba, contributing to a significant improvement of ECVR.
Representing Camera Response Function by a Single Latent Variable and Fully Connected Neural Network
Sep 08, 2022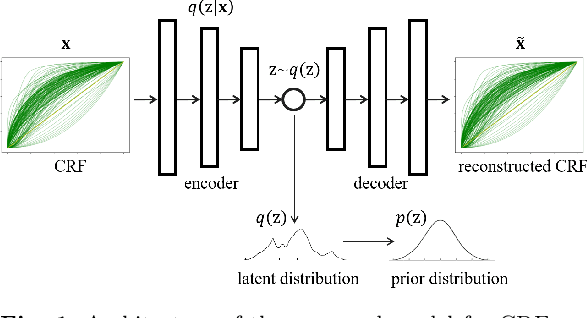
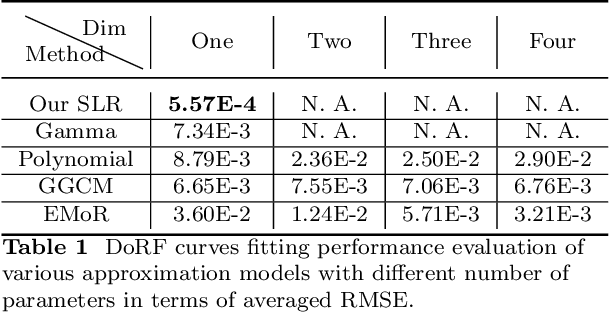
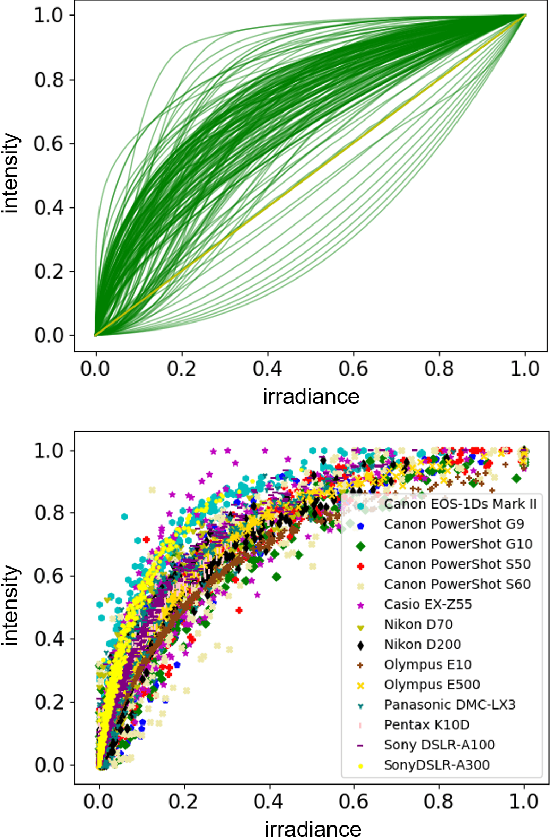
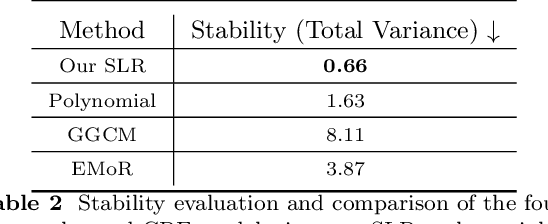
Modelling the mapping from scene irradiance to image intensity is essential for many computer vision tasks. Such mapping is known as the camera response. Most digital cameras use a nonlinear function to map irradiance, as measured by the sensor to an image intensity used to record the photograph. Modelling of the response is necessary for the nonlinear calibration. In this paper, a new high-performance camera response model that uses a single latent variable and fully connected neural network is proposed. The model is produced using unsupervised learning with an autoencoder on real-world (example) camera responses. Neural architecture searching is then used to find the optimal neural network architecture. A latent distribution learning approach was introduced to constrain the latent distribution. The proposed model achieved state-of-the-art CRF representation accuracy in a number of benchmark tests, but is almost twice as fast as the best current models when performing the maximum likelihood estimation during camera response calibration due to the simple yet efficient model representation.
Colour alignment for relative colour constancy via non-standard references
Dec 30, 2021
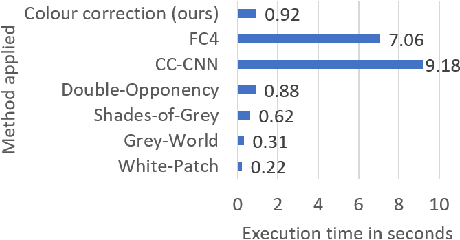
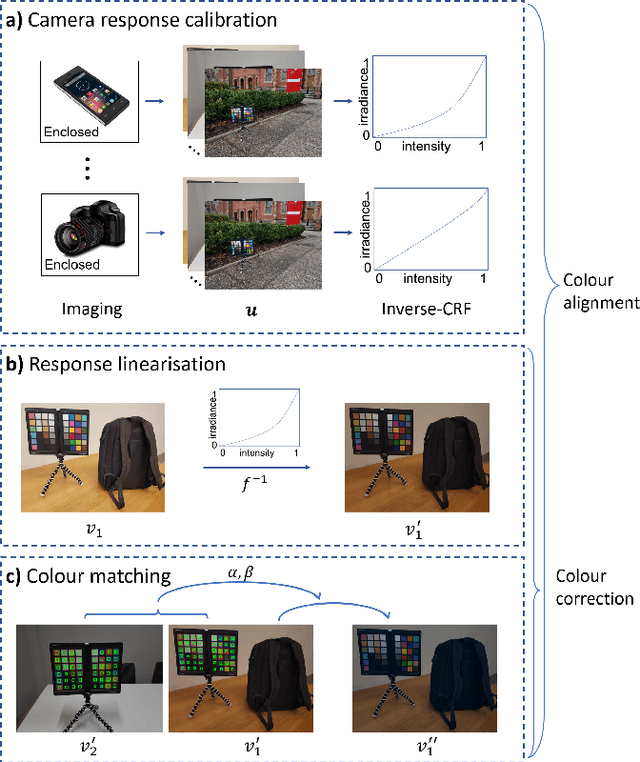
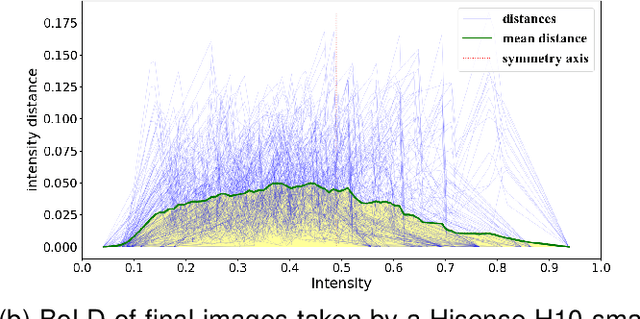
Relative colour constancy is an essential requirement for many scientific imaging applications. However, most digital cameras differ in their image formations and native sensor output is usually inaccessible, e.g., in smartphone camera applications. This makes it hard to achieve consistent colour assessment across a range of devices, and that undermines the performance of computer vision algorithms. To resolve this issue, we propose a colour alignment model that considers the camera image formation as a black-box and formulates colour alignment as a three-step process: camera response calibration, response linearisation, and colour matching. The proposed model works with non-standard colour references, i.e., colour patches without knowing the true colour values, by utilising a novel balance-of-linear-distances feature. It is equivalent to determining the camera parameters through an unsupervised process. It also works with a minimum number of corresponding colour patches across the images to be colour aligned to deliver the applicable processing. Two challenging image datasets collected by multiple cameras under various illumination and exposure conditions were used to evaluate the model. Performance benchmarks demonstrated that our model achieved superior performance compared to other popular and state-of-the-art methods.
Few-Shot Partial-Label Learning
Jun 02, 2021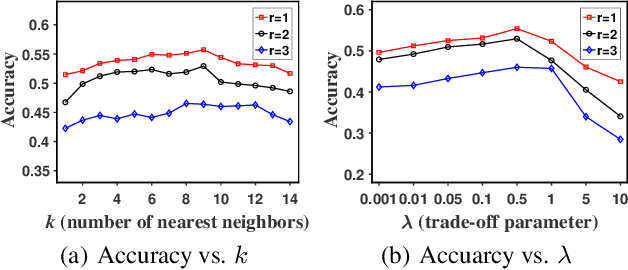
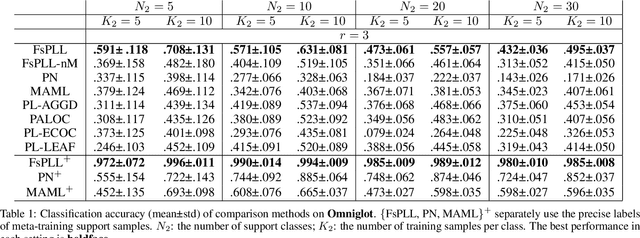
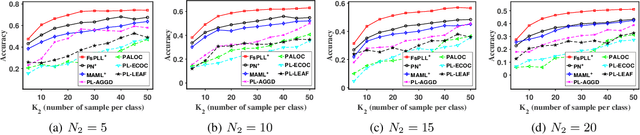
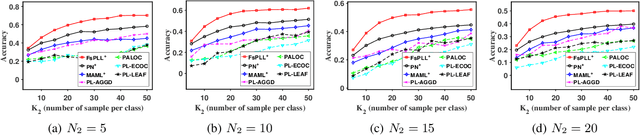
Partial-label learning (PLL) generally focuses on inducing a noise-tolerant multi-class classifier by training on overly-annotated samples, each of which is annotated with a set of labels, but only one is the valid label. A basic promise of existing PLL solutions is that there are sufficient partial-label (PL) samples for training. However, it is more common than not to have just few PL samples at hand when dealing with new tasks. Furthermore, existing few-shot learning algorithms assume precise labels of the support set; as such, irrelevant labels may seriously mislead the meta-learner and thus lead to a compromised performance. How to enable PLL under a few-shot learning setting is an important problem, but not yet well studied. In this paper, we introduce an approach called FsPLL (Few-shot PLL). FsPLL first performs adaptive distance metric learning by an embedding network and rectifying prototypes on the tasks previously encountered. Next, it calculates the prototype of each class of a new task in the embedding network. An unseen example can then be classified via its distance to each prototype. Experimental results on widely-used few-shot datasets (Omniglot and miniImageNet) demonstrate that our FsPLL can achieve a superior performance than the state-of-the-art methods across different settings, and it needs fewer samples for quickly adapting to new tasks.